
实验2-鸢尾花分类
VMware虚拟机 Ubuntu20-LTS
python3.6
tensorflow1.15.0
keras2.3.1
运行截图:
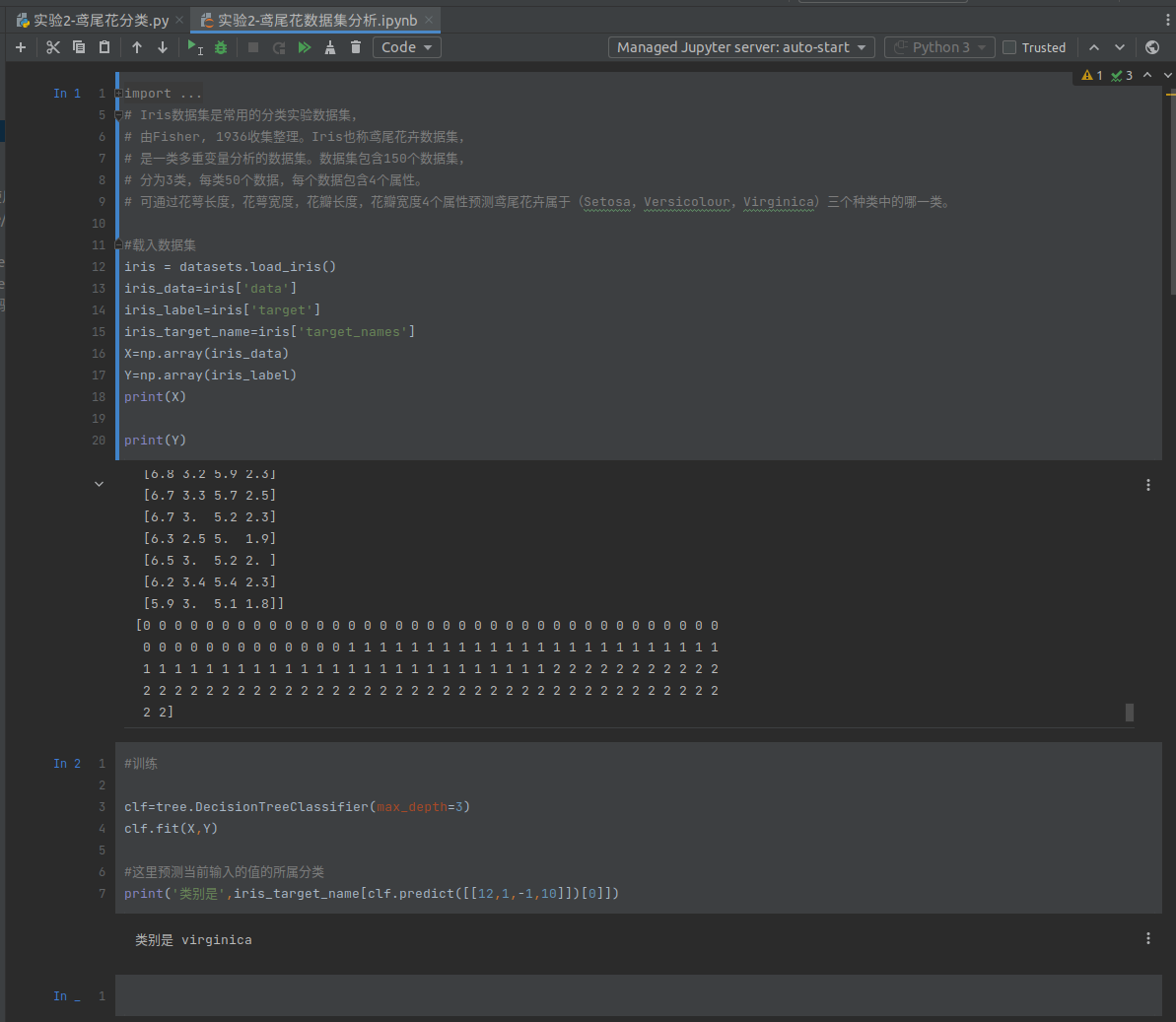
代码:

from sklearn import datasets import matplotlib.pyplot as plt import numpy as np from sklearn import tree # Iris数据集是常用的分类实验数据集, # 由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集, # 是一类多重变量分析的数据集。数据集包含150个数据集, # 分为3类,每类50个数据,每个数据包含4个属性。 # 可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。 #载入数据集 iris = datasets.load_iris() iris_data=iris['data'] iris_label=iris['target'] iris_target_name=iris['target_names'] X=np.array(iris_data) Y=np.array(iris_label) print(X) print(Y) #训练 clf=tree.DecisionTreeClassifier(max_depth=3) clf.fit(X,Y) #这里预测当前输入的值的所属分类 print('类别是',iris_target_name[clf.predict([[12,1,-1,10]])[0]])


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人