


分布式事务
大纲:
- 本地事务、分布式事务
- CAP理论
- BASE理论
- 2PC解决方案
- TCC解决方案
- MQ消息解决方案
一、本地事务、分布式事务
本地事务:一个数据库事务
分布式事务:跨数据库,或者跨jvm产生的事务。例:一个应用提交一个本地事务,然后远程调用另外一个应用提交一个本地事务,这2个事务就是分布式事务。
二、CAP理论
Consistency(一致性):客户端请求所有服务端,给出的结果都是一致的。例:客户端请求订单系统和支付系统中一个订单状态,这2个系统给出的状态应该是一致的。
Availability(可用性):客户端请求所有服务端,都能给出响应,无论结果对错。例:客户端请求订单系统和支付系统中一个订单状态,这2个系统应立刻给出响应,即使在支付成功回调订单系统修改状态失败后,订单状态在两个系统不一致。
Partition tolerance(分区容忍性):服务端网络发生通讯故障产生了分区时,仍可对外提供服务。例:A,B两个机房构成一个分布式系统,AB间网络发生故障时,仍要对外提供服务,就是脑裂问题

三、BASE理论
BASE理论是基于CAP理论逐步演化而来的,是CP(强一致性)和AP(强可用性)权衡的结果。
BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点采用适当的方式来使系统达到最终一致性。
Basically Available(基本可用)
响应时间上的损失:正常情况下,处理用户请求需要0.5s返回结果,但是由于系统出现故障,处理用户请求的时间变成3s。系统功能上的损失:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的非核心功能无法使用。
Soft state(软状态)
数据处理中被查询到可以是一个中间状态,如订单的"支付中"。
Eventually consistent(最终一致性)
系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态,不要求实时。
四、2PC解决方案
一些术语:
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
2PC两阶段提交:TM发起全局事务,通知RM进入PREPARE阶段,执行本地事务但不提交,然后返回是否可以提交事务,当所有RM返回可以提交之后,TM通知RM提交事务;如果其中任意一个RM返回超时或者返回不可提交,TM通知RM回滚事务。3PC是2PC的优化,将PREPARE细分为2个阶段,这样第一个阶段仅判断是否每个RM状态正常不占用任何锁资源,提高后面2个阶段实际执行事务的成功率。
4.1 2PC解决方案-XA
XA是数据库提供的接口规范(即接口函数),作用就是在多个数据库纳入一个事务进行管理。大多主流数据库支持XA协议,但由于性能较差,使用者并不多。
4.2 2PC解决方案-SEATA AT模式
SEATA简介: http://seata.io/zh-cn/docs/overview/what-is-seata.html
Seata 是一款开源的分布式事务解决方案,其中AT模式就是2PC的一种演变,SEATA需要一个独立部署的TC,并在应用数据库种建一张用于回滚的本地undo log表,具体执行流程如下:
- TM向TC开启全局事务(注解实现)生成全局事务ID
- RM向TC注册分支事务,纳入全局事务管理
- 全局事务发起方在同一个本地事务中向业务表和undolog表各插入一条数据,然后通过远程调用将XID传给下游(SEATA对springcloud支持很好,有默认的feign拦截器),下游系统做同样的操作。
- 远程调用成功全局事务异步提交,失败则用undolog表中日志进行反向补偿
小结:2PC主要在数据库层面保持事务的全局一致
五、TCC解决方案
TCC:TCC是TRY(预处理阶段),CONFIRM(提交阶段)/CANCEL(回滚阶段)的简写,相较于2PC基于数据库层面的一致性, TCC支持把自定义的分支事务纳入到全局事务的管理中,更加灵活。
TCC解决方案-SEATA TCC模式/HMILY框架(对spring cloud支持较好),TCC也有2个阶段:TM首先通知所有RM进行一阶段TRY操作,TM根据所有RM TRY的结果来决定二阶段CONFIRM或者CANCEL。这2阶段行为由分布式框架管理异步调用,而三种行为的逻辑部分完全由开发者自定义。若第二阶段执行失败,TM有重试机制。
TCC需要注意三种异常处理:
- 空回滚:没调用TRY的情况下,直接调用CANCEL,由于TRY和CANCEL都是独立线程执行,在TRY阶段异常时,相当于并没有执行成功,这时候直接CANCEL需要识别出TRY没有执行过,不能回滚。解决方法:TRY,CANCEL/COMMIT的时候同步插入事务日志表(包括全局事务ID),CANCEL时候检查TRY是否已经执行。
- 幂等:由于二阶段有重试机制,需要保证CANCEL,CONFIRM方法幂等。解决方法:检查CANCEL,CONFIRM是否已经执行。
- 悬挂:TRY方法由于网络慢第一时间没执行,导致TM超时,TM通知CANCEL,这时TRY方法又执行了。解决方法:TRY前检查是否该事务已经执行过CANCEL。
小结:TCC虽然可以灵活操作2个阶段的业务逻辑,但实现复杂、代码侵入性较强,而且对异常处理要格外小心。
六、MQ消息解决方案
6.1事务消息
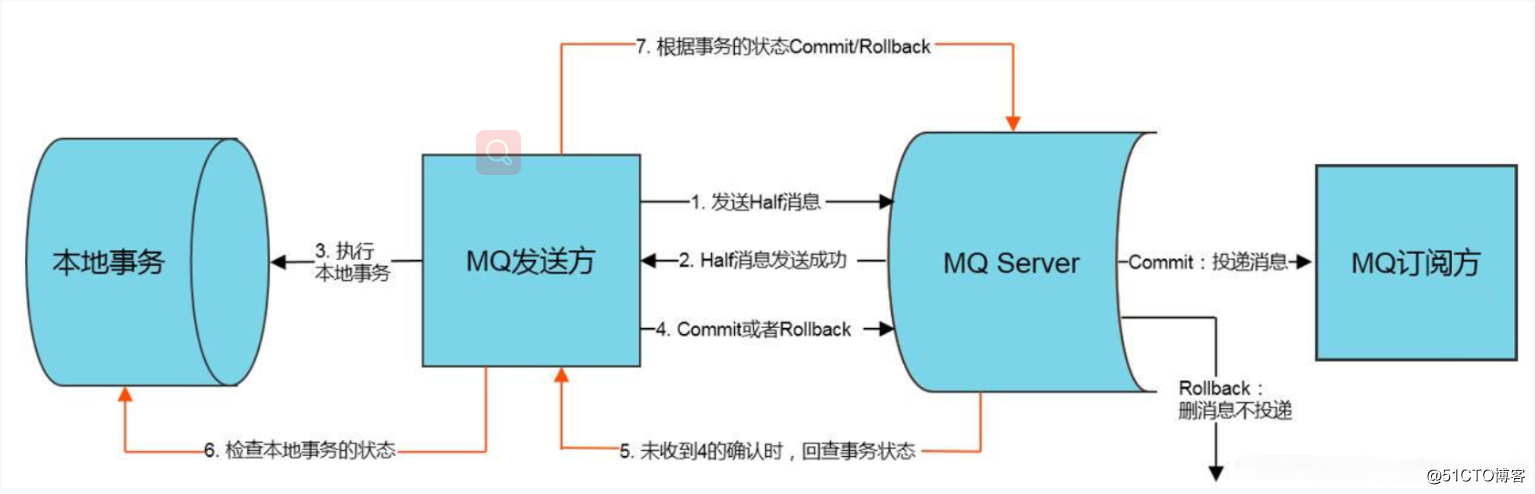
rocketmq支持事务消息,具体流程如图,其中事务发起方开发步骤2和5的回调函数(如果在2中返回UNKOWN,brocker会在一定间隔后回调5再次确认事务消息是否COMMIT或者ROLLBACK,回调次数和间隔可配置),来确保本地事务执行完成后,mq消息一定能保存到mq server上。
6.2最大努力通知
最大努力通知的执行流程简单:
- 事务发起方执行本地事务
- 发普通消息到mq server(无论失败与否)
- 然后接收方消费消息完成本地事务
- 事务发起方提供查询接口,防止消息没有被接收方消费。
小结:
两种mq消息保证事务一致性的思想不同:
事务消息:以消息一定能发到消费方来保证事务一致性,
最大努力通知:则是通过提供查询接口保证。
两者应用场景不同:
事务消息:适用于接收方不知道发起方发过消息的场景,例如注册用户送积分,积分服务收到用户服务的消息之前,并不能提前知道有用户注册了,这种场景依赖于注册用户后,消息一定要发到积分服务上。
最大努力通知:适用于接收方的数据处于一种中间状态,接收方知道这个状态会改变,例如支付系统中,上游系统修改订单支付状态后,使用mq通知自己系统的通知服务,然后通知服务通过http通知下游系统修改订单支付状态,即使通知失败了,在下游用户发现自己订单状态异常的时候可以通过上游系统提供订单状态查询接口来查询最新的订单状态。
两者缺点:
事务消息:事务强依赖于MQ。
最大努力通知:时效在通知失败的情况下会比较差。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!
2021-04-17 二叉树的遍历
2021-04-17 顺序存储二叉树