深度强化学习方法 策略迭代 & 值迭代
RL是一个序列化决策过程,核心思想是通过与环境的不断交互学习获得最大回报;
大部分RL方法都是基于MDP的;MDP的本质是获得一个可以使累计收益最大化的策略,并使用该策略选择最佳动作;
动态规划是RL中的一个关键技术,适用于RL中已知模型求解最优策略的特殊情况,主要有 策略迭代 和 值迭代 两种方法;
(RL中通常是不知道 奖励值、转移的新状态及状态转移概率 的,往往采用 蒙特卡洛 和 时序差分 的方法。蒙特卡洛方法需要采样一次完整的决策过程才可以对过程中的决策动作更新Q值,计算量较大,计算不方便,不能单步的改进动作Q值, 因此我们往往采用时序差分的方法,如Q-learning和Sarsa方法);
1. 策略迭代:
以某种策略开始,计算当前策略下的值函数;依据值函数更新策略,再依据更新后的策略更新值函数(需保证每个状态的值函数都收敛后才更新策略);直到下一个状态的值函数与前一个状态的值函数不再发生变化;
策略迭代花费了大量时间进行策略评估的过程,但也易于证明其收敛性;

2. 值迭代:
为了缩短策略迭代过程中策略评估的时间,可将值迭代理解为策略迭代的改进版本;
策略迭代每次需要值函数完全收敛的情况下才进行策略更新,将对策略评估的要求放低,以此提升迭代速度;
改进方法:使用贝尔曼方程,将策略改进视为价值改进,让策略函数与价值函数同时收敛,每一步求取最大的值函数,具体迭代公式如下:
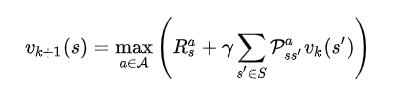
对当前状态s,对每一个可能的动作a都计算才去这个动作后下一个状态的期望值,将最大的期望值作为当前状态的价值函数,直到收敛;
与策略迭代相比,没有等到状态价值函数收敛再更新策略,而是根据贪心法寻找最优价值函数,值迭代的过程不会对应任何明确的策略;
值迭代是根据状态期望值选择动作,而策略迭代是先估计状态值,再更新策略;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号