[机器学习入门]泰坦尼克生存预测
亿点题外话:
大家都熟悉『you jump i jump』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇的数量有限,无法人人都有,副船长发话了『lady and kid first!』,所以是否获救其实并非随机,而是基于一些背景有rank先后的。
训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。
数据来源:
数据来源于 Kaggle,链接: TItanic 数据集
实践目标:
根据数据集中各个字段使用机器学习进行建模,来预测泰坦尼克沉船事件中的任一旅客生还的概率
初步分析:
首先观察给出的信息条目,检查数据的完整性,做出常识性推理
得到以下信息:
再使用 describe(),得到数值型数据的一些分布
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | NaN | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | NaN | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | NaN | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
从中,我们得到,整体的平均存活率为0.38,1等舱的人数少于2等舱少于3等舱,平均年龄为29.7,其余信息暂且也不知道是否有效这里先不罗列。
条目分析
- PassengerId => 乘客ID,无关变量
- Survived => 乘客是否存活
为本次建模的因变量,其余为自变量 - Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
按照常理,姓名应该是无关变量,但是本次建模中,姓名内包含了“Miss”、“Mrs”这类可以体现年龄的名称,以及“Master”这类体现身份地位的名称,故具有一定的参考意义。 - Sex => 性别
- Age => 年龄
存在数据缺失,暂定通过姓名信息补全 - SibSp => 堂兄弟/妹个数
- Parch => 父母子女个数
- Ticket => 船票信息,无关变量
- Fare => 票价
- Cabin => 客舱
由于缺失过多,暂定以二元变量参与计算 - Embarked => 登船港口
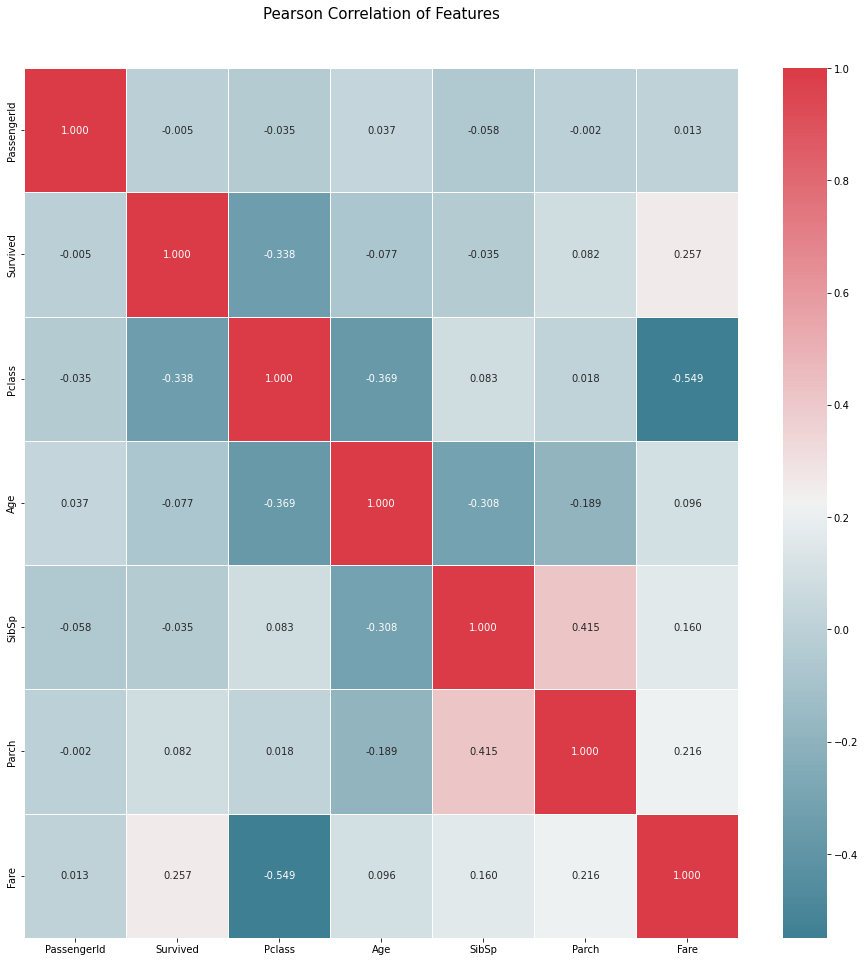
相关性检验:各个变量之间的皮尔逊系数没有强相关性,可以直接选用这些变量进行建模
逐条分析
Pclass:
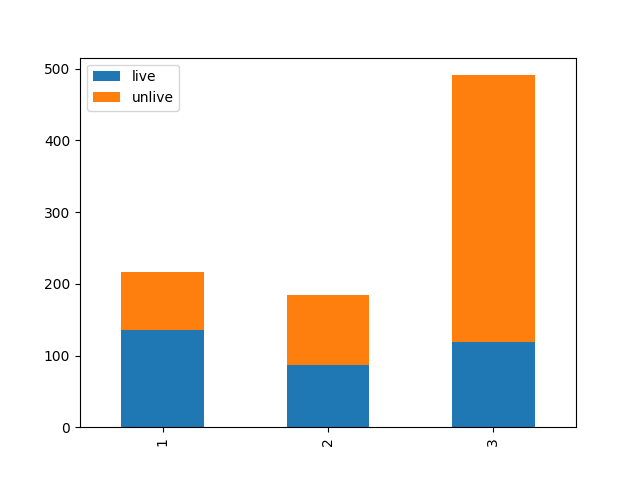
由常理推算,舱位可以体现经济状况,从而反映出是社会地位,那么在得救的时候就有了优先的权利,测了一下果然是酱紫,可见1/2等舱的存活率明显高于3等舱。那么这就成为了本次模型中一个很重要的特征。
Sex:

由此可见船长那一句“lady first”大家践行的还是很好的,不只是喊喊口号,所以Sex也成为一项重要的特征。
Age:
与前两项自变量不同,Age缺少了部分的数据。
通常遇到缺值的情况,我们会有几种常见的处理方式
- 如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
- 如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
- 如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
- 本例中,后两种处理方式应该都是可行的,我们先试试拟合补全吧(虽然说没有特别多的背景可供我们拟合,这不一定是一个多么好的选择)
我们这里用scikit-learn中的RandomForest(参考CSDN韩小阳)来拟合一下缺失的年龄数据(注:RandomForest是一个用在原始数据中做不同采样,建立多颗DecisionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法)
对 'SibSp'、'Parch'、'Sex'列生成新列
- 用“FamilySize”代替 'SibSp'、'Parch',因为通过对 'SibSp'、'Parch'单独分析发现没有显著特征,于是尝试合并两项(体现家族人数,也许大家族优先?)
- 生成 IsAlone 由于familysize数据较为分散,为了更好预测集中数据特征,将乘客分为一人与多人
- 用0/1代替 male/female
“Age”和“Fare”的数据收敛处理:
__EOF__

本文链接:https://www.cnblogs.com/liubaili/p/15815575.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本