

这一周,建民哥给我们进行了抗糖测验冲刺,冲刺的内容是论文爬虫系统,
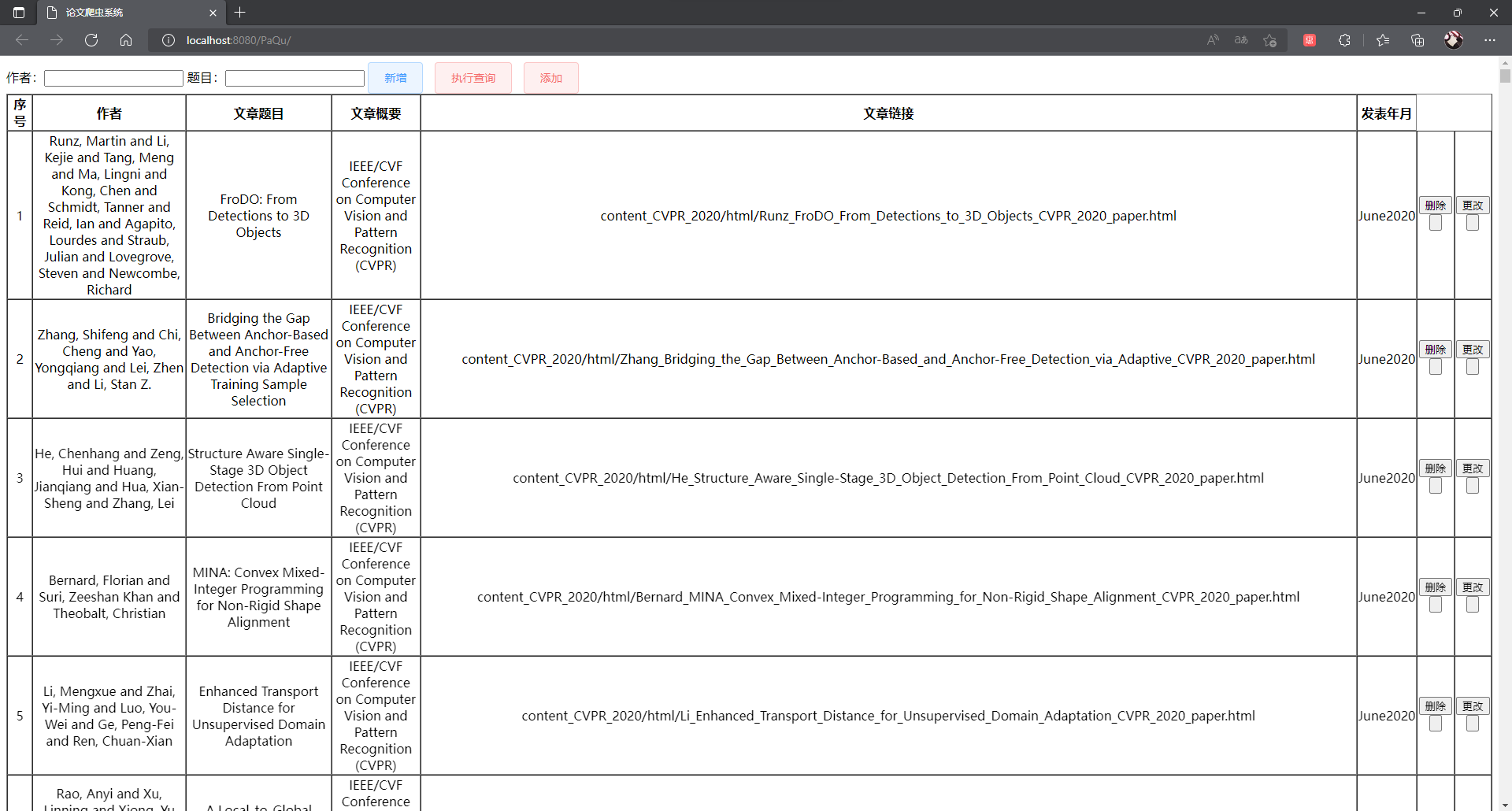
第一阶段是进行论文的增删改查以及爬虫爬取网页中的论文数据,经过了几天的努力终于完成了,代码截图如下:
论文添加:
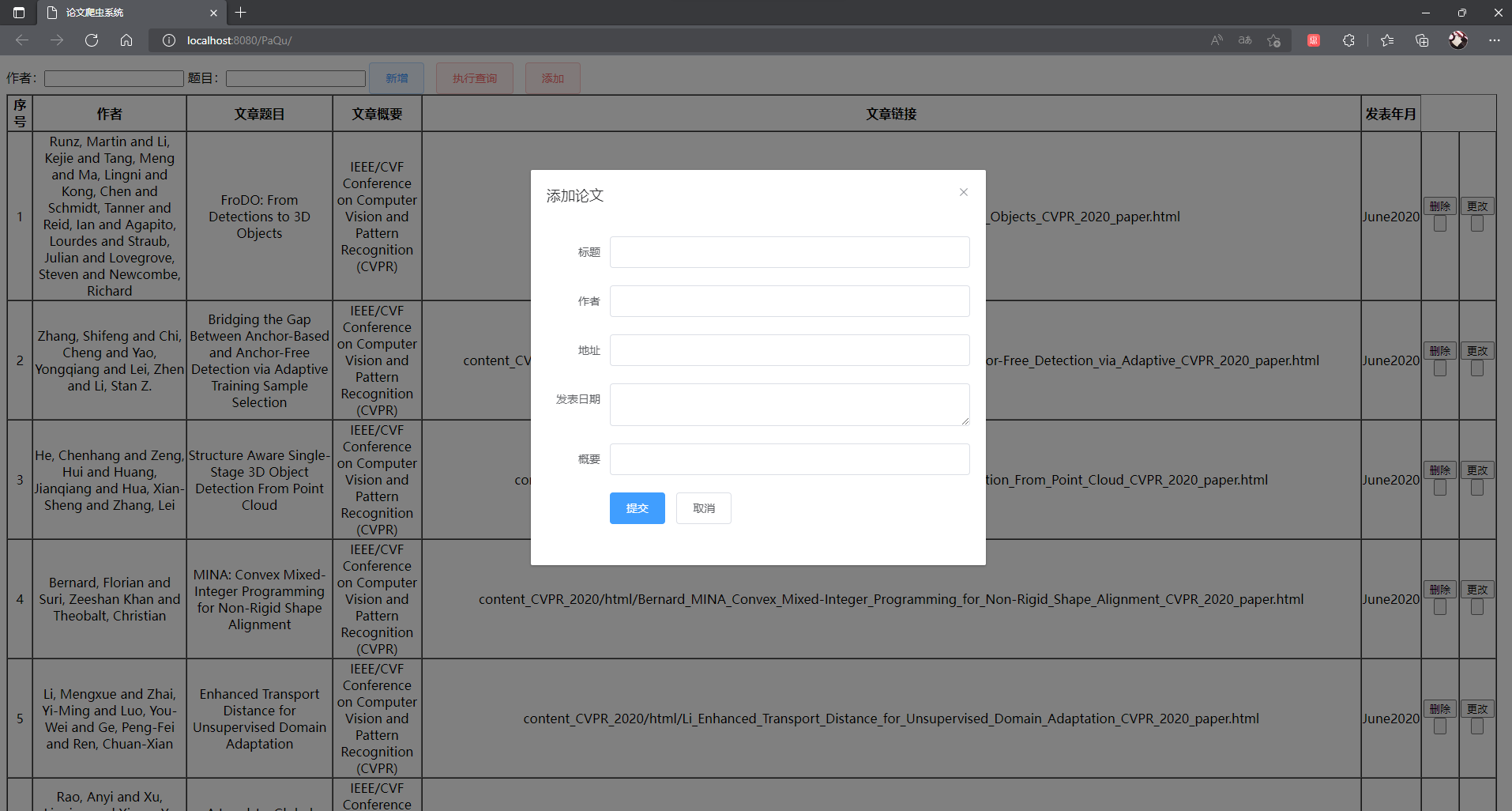
论文修改:

论文部分查询:

爬虫部分代码:
package bai.utils; import bai.pojo.Essay; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; import java.net.URL; import java.util.ArrayList; import java.util.List; public class pa { Elements elements,elements1; List<Essay> essays=new ArrayList<>(); public void PaQu() throws IOException { System.out.println("1"); String url="https://openaccess.thecvf.com/CVPR2020?day=2020-06-18"; Document document = Jsoup.parse(new URL(url), 30000); Element element=document.getElementById("content"); elements=element.getElementsByClass("bibref"); elements1=element.getElementsByClass("ptitle"); System.out.println("2"); System.out.println(elements.text()); } public List<Essay> dispose(){ int a=0; for (Element el:elements){ Essay essay=new Essay(); String attr=el.text(); String[] res=attr.split("="); for(int j=0;j<=5;j++){ res[j]=res[j].trim(); } int idx1=res[1].lastIndexOf("}"); essay.setAuthor(res[1].substring(1,idx1)); int idx2=res[2].lastIndexOf("}"); essay.setTitle(res[2].substring(1,idx2)); int idx3=res[3].lastIndexOf("}"); essay.setBookTitle(res[3].substring(1,idx3)); int idx4=res[4].lastIndexOf("}"); essay.setDate(res[4].substring(1,idx4)); essay.setDate(essay.getDate()+(res[5].substring(1,5))); essays.add(essay); } for (Element el:elements1){ if(a<essays.size()){ String address=el.getElementsByTag("a").attr("href"); essays.get(a).setAddress(address); } a++; } return essays; } }

