正则表达式
正则表达式
是什么? 通过一个规则,来从一段字符串中找到符合规则的内容/判断某段字符串是否符合规则
有什么用?
注册页/网页上 要求你输入一个信息 判断你输入的信息是否格式正
爬取数据 从网页上把代码以字符串的形式下载回到内存,提取这个大字符串中我想要的内容了
正规规则
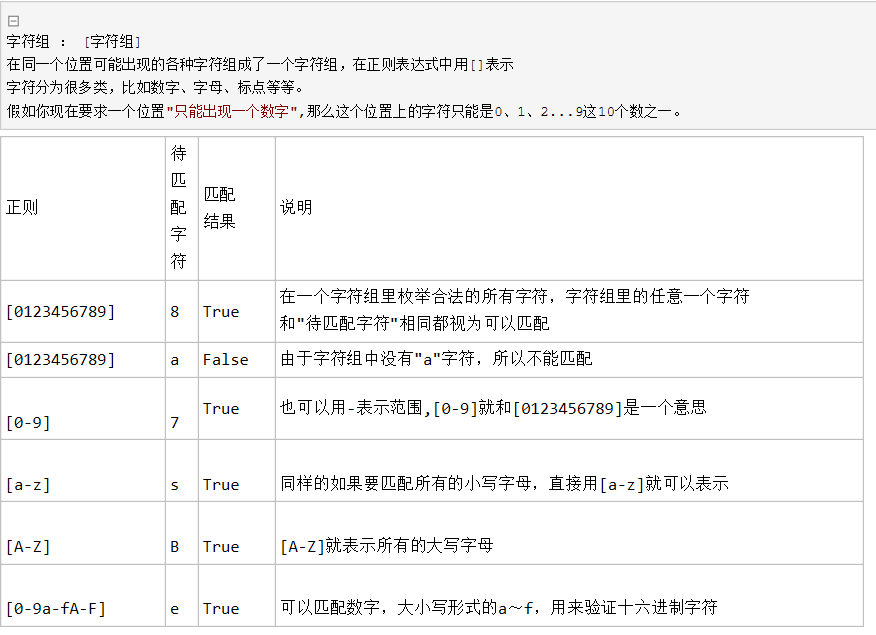
1.字符组 约束字符中某一个字符位置上的值是什么,只要是出现在字符组中的内容都算匹配到了
2.'[3-9]' 从小到达的顺序到底是根据 asc码的顺序来的
3.匹配数字 [0-9] 匹配字母[A-Za-z] 匹配数字和字母[0-9a-zA-Z]
元字符:
| 元字符 | 匹配内容 |
| . | 匹配除换行符意外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
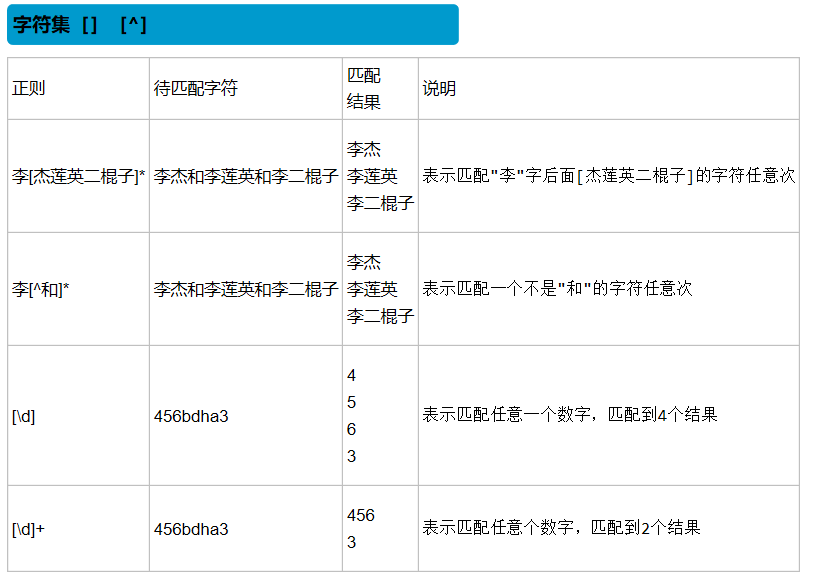
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
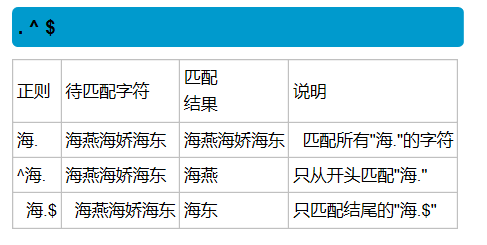
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
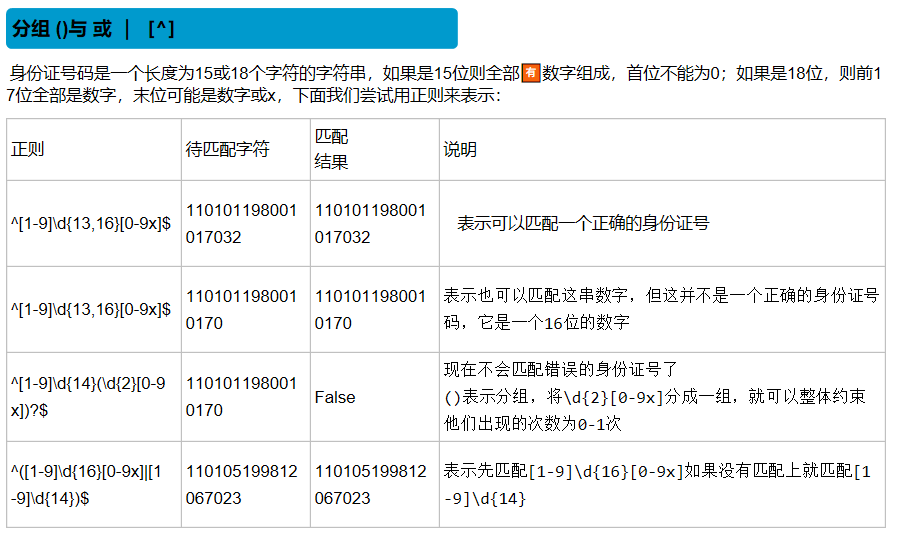
| () | 匹配括号内的表达式,也表示一个组 |
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配除了字符组中字符的所有字符 |
量词 :
| 量词 | 用法说明 |
| * | 重复零次或者更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |


findall 和 分组的问题 import re # ret = re.findall('\d+(?:\.\d+)?','1.2345+4.3') # ?:写在一个分组的最开始,表示在findall方法中取消这个分组的优先级 # 1.2345 4.3 # .2345 .3 # print(ret) # ret= re.search('\d+(\.\d+)?','1.2345+4.3') # print(ret.group()) # ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') # print(ret) # search # ret = re.match('\d+', 'hello,alex3714') # print(ret) # 'aa|bb'.split('|') # split中如果带有分组,会在分割的同时保留被分割内容中带分组的部分 # ret = re.split('(\d\d)','alex83wusir38egon20') # print(ret) # ret = re.sub('\d+','sb','alex83wusir38egon20',2) # print(ret) # ret = re.subn('\d+','sb','alex83wusir38egon20') # print(ret) # 节省时间 # obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 # print(obj) # ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 # print(ret.group()) # ret = obj.search('abc444eeee') #正则表达式对象调用search,参数为待匹配的字符串 # print(ret.group()) # finditer # 迭代功能的 # findall # 节省空间的 # ret = re.finditer('\d+','12aas14jsk38947cjhxj83') # print(ret) # for i in ret: # print(i.group()) # 基础查找 findall(分组优先显示) search match # 替换分割 split(分组保留) sub subn # 代码优化 compile finditer # 分组命名 # html标签语言 # html是一种代码 # 对于浏览器来说 浏览器和代码之间有一种约定 # 写在一个标识符之内的代码 可以有一种独立的格式 # 标识符 # <h1>sgjkagjgdjkf</h1> # 给分组起名字 (?P<tag>正则表达式),使用分组的名字(?P=tag) # ret = re.search('<(?P<tag>\w+?)>\w+</(?P=tag)>',"<b>hello</b>") # print(ret.group()) # print(ret.group('tag')) # 根据分组的索引使用分组 \1,1是分组的索引值 # ret = re.search(r'<(\w+?)>\w+</\1>',"<b>hello</b>") # print(ret.group()) # print(ret.group(1)) # ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") # ret.group(1) # ret = re.finditer(r'<(\w+?)>\w+</\1>',"<b>hesakdfkhfkllo</b>") # for i in ret: # print(i.group(1)) # print(i.group())

