Hadoop的简单了解与安装
hadoop
一, Hadoop 分布式 简介
Hadoop 是分布式的系统架构,是 Apache 基金会顶级金牌项目
分布式是什么?学会用大数据的思想来看待和解决问题 思 想很重要
1-1 、Hadoop 的思想之源:
来自于 Google 03 年发布 3 大论文, GFS、MapReduce、Bigtable ;Dougcutting 用 Java 实现
1-2 、Hadoop 创始人介绍
Hadoop 作者 Doug cutting,就职 Yahoo 期间开发了 Hadoop项目,目前在 Cloudera 公司从事架构工作

1-3 、Hadoop 发展历程
2003-2004 年,Google 公开了部分 GFS 和 Mapreduce 思想的细节,以此为基础 Doug Cutting 等人用了 2 年业余时间实现了DFS 和 Mapreduce 机制,一个微缩版:Nutch
Hadoop 于 2005 年秋天作为 Lucene 的子项目 Nutch 的一部分正式引入 Apache 基金会。2006 年 3 月份,Map-Reduce 分布式离线计算 和 Nutch Distributed File System (NDFS) nutch 分布式文件系统分别被纳入称为 Hadoop 的项目中。(Hadoop 如今是 Apache 基金会顶级金牌项目)Hadoop 这名字来源于 Doug Cutting 儿子的玩具大象
1-4 、Hadoop 组成:
Hadoop = hdfs(存储) + mapreduce(计算) + yarn(资源管理)
1-4-2、 、统 分布式存储系统 HDFS (Hadoop Distributed File
System )
– 分布式存储系统
– 提供了 高可靠性、高扩展性和高吞吐率的数据存储服务
1-4-2、 、架 分布式计算框架 MapReduce
– 分布式计算框架(计算向数据移动)
– 具有 易于编程、高容错性和高扩展性等优点。
1-4-3、 、架 分布式资源管理框架 YARN (Yet Another Resource Management )
– 负责集群资源的管理和调度
二、 分布式 文件存储系统 HDFS
2 2- -1 1 、S HDFS 是什么?
HDFS 是 Hadoop 分布式文件存储系统
为什么会有分布式的文件存储系统出现?
面对的大量的数据和如何计算的难题大量【pb 级以上】的网页怎么存储问题 (之前是用磁柜存储)
分布式存储系统 HDFS (Hadoop Distributed File System)
主要解决大数据的存储问题。经过多年的发展,HDFS 的应用已经非常成熟非常多,如百度网盘 360 云盘 腾讯微云 阿里云(不仅提供服务器和云存储还提供服务,比一般的强多了)大数据好多技术框架都架构于这个文件存储系统之上的。
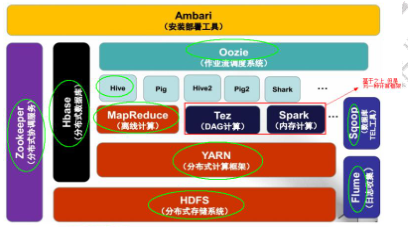
hadoo2.x生态系统
2-2 、HDFS 架构图( 重点) :
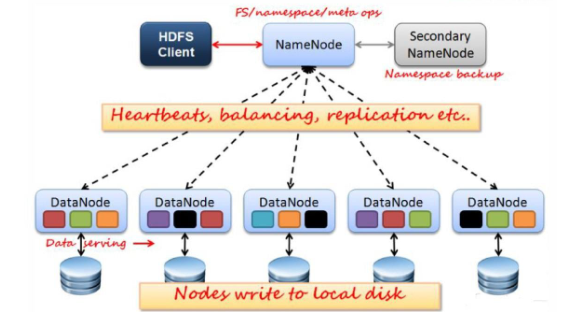
如图所示有 HDFS 中有哪些模块?
那么接下来我就一一给大家介绍这些功能模块及 HDFS 的原理!
众所周知关系型数据库是按什么储存的?行! 那么 HDFS 呢?
2-3 、HDFS 的功能模块及原理详解( 非常重要)
2-3-1 、HDFS 数据存储单元(block )
--文件被切分成固定大小的数据块 block
• 默认数据块大小为 128MB (hadoop2.x),可自定义配置
• 若文件大小不到 128MB ,则单独存成一个 block
- 一个文件存储方式
按大小被切分成若干个 block ,存储到不同节点上
• 默认情况下每个 block 都有 3 个副本
- Block 大小和副本数通过 Client 端上传文件时设置,文件上传成功后副本数可以变更,Block Size 不可变更
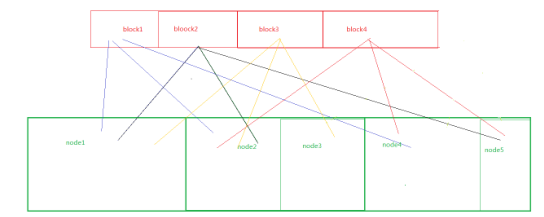

hdfs 存储模型:字节
– 文件线性切割成块(Block):偏移量 offset (byte)
– Block 分散存储在集群节点中
– 单一文件 Block 大小一致,文件与文件可以不一致
– Block 可以设置副本数,副本分散在不同节点中
• 副本数不要超过节点数量
– 文件上传可以设置 Block 大小和副本数
– 已上传的文件 Block 副本数可以调整,大小不变
– 只支持一次写入多次读取,同一时刻只有一个写入者
– 可以 append 追加数据
2-3-2 、NameNode (简称 NN )
2-3 -2 -1 NameNode 主要功能:
• 接受客户端的读/写服务
• 收集 DataNode 汇报的 Block 列表信息
2 - 3- 2- 2 、 基于内存存储 : 不会和磁盘发生交换
• 只存在内存中
• 持久化
2- 3- 2- 3 NameNode 保存 a metadata 信息:
• 文件 owership(归属)和 permissions(权限)
• 文件大小,时间
• (Block 列表:Block 偏移量),位置信息
• Block 保存在哪个 DataNode 信息(由 DataNode 启动时上
报,不保存在磁盘)
2 -3 -2-4 NameNode 持久化
• NameNode 的 metadate 信息在启动后会加载到内存
• metadata 存储到磁盘文件名为”fsimage”
• Block 的位置信息不会保存到 fsimage
• edits 记录对 metadata 的操作日志
fsimage 保存了最新的元数据检查点,类似快照。
- editslog 保存自最新检查点后的元信息变化,从最新检查点后,hadoop 将对每个文件的操作都保存在 edits 中。客户端修改文件时候,先写到 editlog,成功后才更新内存中的
metadata 信息。
Metadata = fsimage + editslog
2-3-4 、DataNode (DN )
• 本地磁盘目录存储数据(Block),文件形式
• 同时存储 Block 的元数据信息文件
• 启动 DN 进程的时候会向 NameNode 汇报 block 信息
• 通过向 NN 发送心跳保持与其联系(3 秒一次),如果 NN 10分钟没有收到 DN 的心跳,则认为其已经 lost,并 copy 其上的 block 到其它 DN
2-3-5 、SecondaryNameNode (SNN )
– 它的主要工作是帮助 NN 合并 edits log 文件,减少 NN 启动时间,它不是 NN 的备份(但可以做备份)。
– SNN 执行合并时间和机制
•A、根据配置文件设置的时间间隔 fs.checkpoint.period 默认 3600 秒。
•B、根据配置文件设置 edits log 大小 fs.checkpoint.size规定 edits 文件的最大值默认是 64MB
2-3-6 、SecondaryNameNode SNN 合并流程
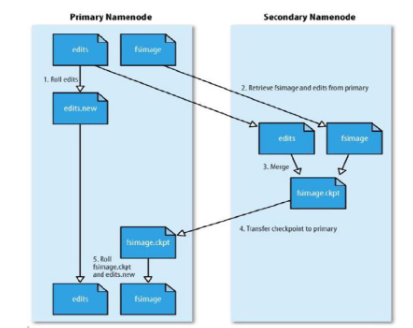
首先是 NN 中的 Fsimage 和 edits 文件通过网络拷贝,到达SNN 服务器中,拷贝的同时,用户的实时在操作数据,那么 NN中就会从新生成一个 edits 来记录用户的操作,而另一边的 SNN将拷贝过来的 edits 和 fsimage 进行合并,合并之后就替换NN 中的 fsimage。之后 NN 根据 fsimage 进行操作(当然每隔一段时间就进行替换合并,循环)。当然新的 edits 与合并之后传输过来的 fsimage 会在下一次时间内又进行合并。
2-3-6 、Block 的副本放置策略
– 第一个副本:放置在上传文件的 DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU 不太忙的节点。
– 第二个副本:放置在于第一个副本不同的机架的节点上。
– 第三个副本:与第二个副本相同机架的不同节点。
– 更多副本:随机节点

2-3-7 、HDFS 读写流程
2 -3 -7 -1写文件流程
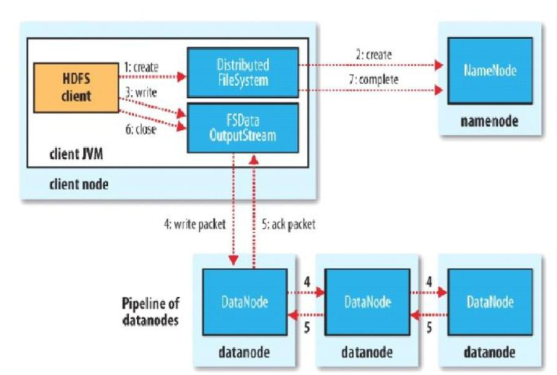
HDFS 写流程
– Client:
• 切分文件 Block
• 按 Block 线性和 NN 获取 DN 列表(副本数)
• 验证 DN 列表后以更小的单位(packet)流式传输数据
– 各节点,两两通信确定可用
• Block 传输结束后:
– DN 向 NN 汇报 Block 信息
– DN 向 Client 汇报完成
– Client 向 NN 汇报完成
• 获取下一个 Block 存放的 DN 列表
• ……………..
• 最终 Client 汇报完成
• NN 会在写流程更新文件状态
2-3 -7 -2 读文件过程
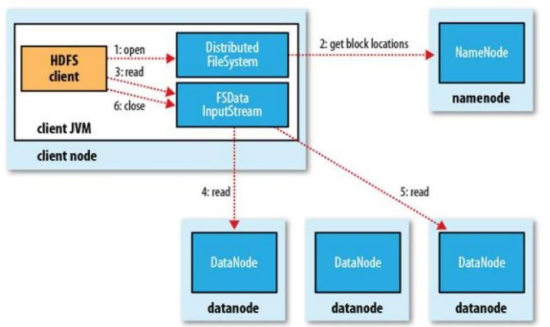
HDFS 读流程
– Client:
• 和 NN 获取一部分 Block 副本位置列表
• 线性和 DN 获取 Block,最终合并为一个文件
• 在 Block 副本列表中按距离择优选取
2- -4 4 、S HDFS 的优缺点(重要)
2-4-1 优点:
– 高容错性
• 数据自动保存多个副本
• 副本丢失后,自动恢复
– 适合批处理
• 移动计算而非数据
• 数据位置暴露给计算框架(Block 偏移量)
– 适合大数据处理
• GB 、TB 、甚至 PB 级数据
• 百万规模以上的文件数量
• 10K+ 节点
– 可构建在廉价机器上
• 通过多副本提高可靠性
• 提供了容错和恢复机制
2-4-2 缺点:
- 低延迟高数据吞吐访问问题
• 比如支持秒级别反应,不支持毫秒级
• 延迟与高吞吐率问题(吞吐量大但有限制于其延迟)
- 小文件存取
• 占用 NameNode 大量内存
• 寻道时间超过读取时间
- 并发写入、文件随机修改
• 一个文件只能有一个写者
• 仅支持 append
三、Hadoop 搭建
3-1、 伪分布式搭建
1、 jdk 安装,配置环境变量
- vi /etc/profile
• export JAVA_HOME=/opt/sxt/jdk1.7.0_75
• PATH=$PATH:$JAVA_HOME/bin
2、 ssh 免密钥(本机)
• ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
• cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3、 上传 hadoop.tar.gz 到服务器
- 解压部署包 到/opt/sxt 目录下
vi /etc/profile
• export HADOOP_PREFIX=/opt/sxt/hadoop-2.6.5
• PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
4、 /opt/sxt/hadoop-2.6.5/etc/hadoop 目录
- hadoop-env.sh
JAVA_HOME=/opt/sxt/jdk1.7.0_75
- core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/local</value>
</property>
- hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
- vi slaves(datanode 节点)
node01
5、 格式化 hdfs namenode -format
6、 启动 start-dfs.sh
7、 查看服务进程启动了么? jps
a) SecondaryNameNode
b) NameNode
c) DataNode
d) Jps
8、 访问 node01:50070
• 确保防火墙关闭(service iptables stop)
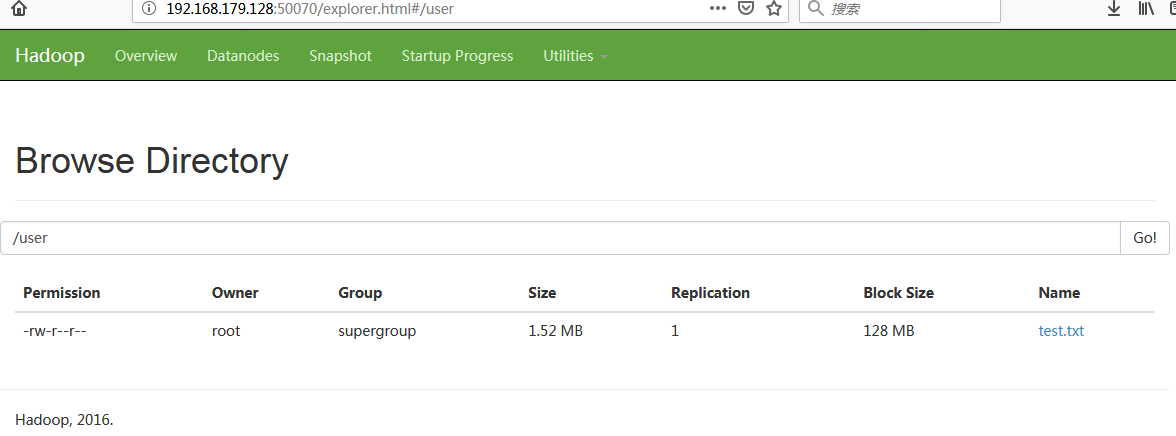
9、 hdfs dfs -mkdir /user
10、 hdfs dfs -ls /user
11 、 hdfs dfs 命令:
• hdfs dfs - - put fileName[ 本地文件名 ] PATH 【s hdfs 的文
件路劲】
• hdfs dfs -du [-s][-h]URI[URI ...] 显示文件(夹)
大小.
• hdfs dfs - - mkdir[- - p] <paths> 创建
• hdfs dfs - - rm - - r /myhadoop1.0 删除
• hdfs dfs -cp [-f][-p|-p[topax]]URI[URI...]<dest >复制文件(夹),可以覆盖,可以保留原有权限信息
产生 100000 条数据:
for i in `seq 100000`;do echo "hello sxt $i" >> test.txt;done
四、Windows 开发环境整合
1、windows 上部署 hadoop 包
• 部署包
• 源码包
• lib 整合
• 将老师给的bin目录下的文件覆盖到部署目录的bin目
录下
– hadoop.dll 放到 c:/windows/system32 下
2、windows 环境变量配置
– hadoop 的 bin 目录 添加到 path 路径下
– HADOOP_USER_NAME
• root
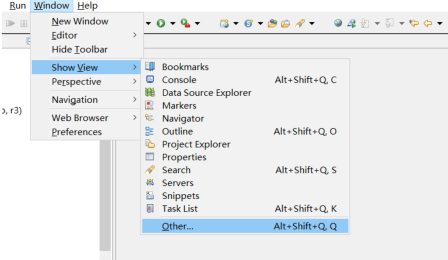
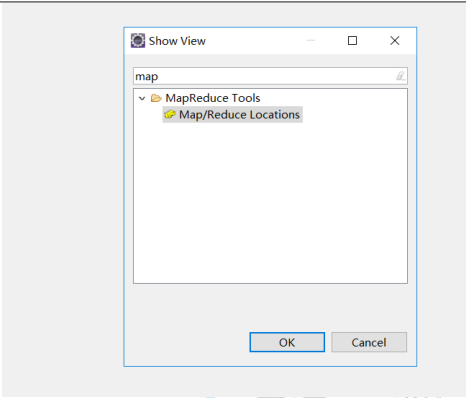
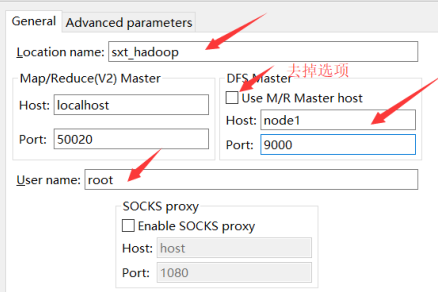
3、eclipse 插件
解压 eclipse 插件压缩包:eclipse-mars
将以下 jar 包放入 eclipse 的 plugins 文件夹中
hadoop-eclipse-plugin-2.6.0.jar
启动 eclipse:出现界面如下: