OO第一单元总结
第一单元主要任务是简化符合特定书写规则的数学表达式。从第一次做作业中只含关于x的多项式,到第二次作业包含简单的三角函数以及函数,再到第三次中实现括号嵌套。难度逐渐上升。本人在最初没有很好为自己的程序留出拓展空间,因此经历了痛苦的重构过程。整体上看,第一次作业由于不用考虑嵌套,我采用了“等级明确”的结构,即”表达式包含项,项包含因子,因子是最小单元“的结构;在第二次和第三次作业中都采用互相包含的结构,通过适当算法将表达式拆成项,项拆成因子,在解析因子时可以回到表达式一级,实现递归下降。
1 第一次作业
1.1 层次结构
先上图
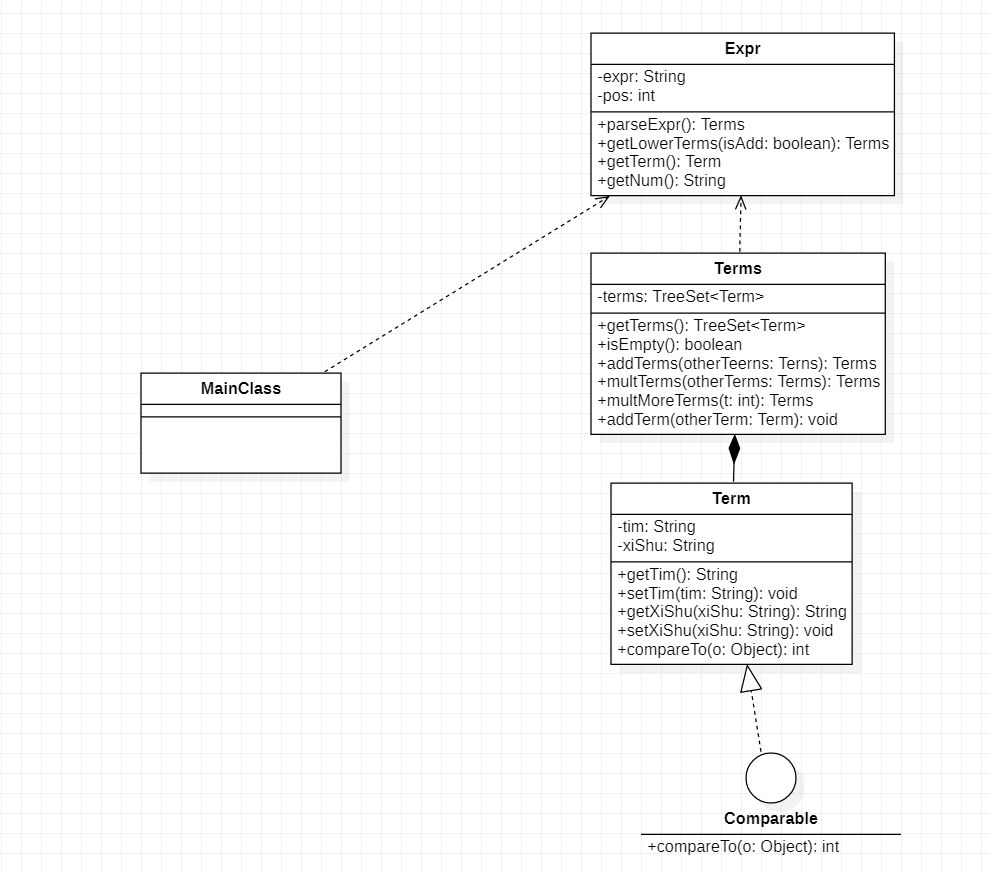
可以看出第一次作业的结构式很简单的。总体上:Term(项)是基础单元,由系数和次数组成,如果是常数则次数为零。Terms是Term的聚集(TreeSet实现),同时为了排序,Term实现了java内置的Comparable接口,重写compareTo方法,以实现在Terms中按照次数小的在前。Terms中有isEmpty方法用来判断Terms是否为空;有addTerm方法用来在Terms中合理地加入一个项(这里的加入可以是新增,也可以是合并同类项)。程序在addTerm的基础上,还实现了Terms之间的运算,比如加法,乘法或者乘方。
可能另大家有些不解的是Expr的地位:图中显示Terms依赖于Expr。实际上这里的Express类是一个“工具类”:它负责将一个字符串转化成Terms,为了实现转化书写了其中的方法。
正如上文所提到,在第一次作业中我并没有考虑到扩展性,因此Expr中的方法也极局限。我的整体思路是:通过复杂的判断模式来”不回溯“地解决问题。这里不回溯是指:我没有进行过任何字符串的截取,但设置了一个指向字符串的指针,即图中的pos,该类中的方法都会移动pos的位置,且pos只会向前,不会退后,直至字符串解析完成。基本方案如下:parse将得到一个预处理好的字符串,parse方法是最高层方法,他会一次一次的调用getLower方法,然后getLower方法一次次地调用getTerm方法。
看起来这样的结构还说的过去?实际不然,这三个方法虽然都遵守着“不超过60行”的规定,却写得我昏天黑地。没错,都是不回溯的设计理念导致的。比如,由于没有事先界定一个Term的范围,最底层的getTerm在得到一个Term的时候就要有很多判断:遇到‘+’怎么办,‘-’怎么办,‘*’怎么办,还可能遇到‘(’等等。其上层的getLower更是麻烦。
可以这样说:不嵌套是“不回溯”的前提条件,正是因为没有了多级括号,才使得可以在pos指针移动的过程中“容易”(虽然实际上写起来并不容易)只根据当前状况来进行判断。
1.2代码结构
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Mainclass.main(String[]) | 64 | 1 | 16 | 16 |
| expr.Expr.Expr(String, int) | 0 | 1 | 1 | 1 |
| expr.Expr.getLowerTerms(boolean) | 31 | 7 | 10 | 13 |
| expr.Expr.getNum() | 2 | 1 | 3 | 3 |
| expr.Expr.getTerm() | 22 | 8 | 10 | 12 |
| expr.Expr.matchRightCurly() | 3 | 3 | 2 | 3 |
| expr.Expr.matchWordEnd() | 2 | 1 | 2 | 3 |
| expr.Expr.parseExpr() | 6 | 1 | 5 | 5 |
| expr.Term.Term() | 0 | 1 | 1 | 1 |
| expr.Term.Term(String, String) | 0 | 1 | 1 | 1 |
| expr.Term.compareTo(Object) | 1 | 2 | 2 | 2 |
| expr.Term.getTim() | 0 | 1 | 1 | 1 |
| expr.Term.getXiShu() | 0 | 1 | 1 | 1 |
| expr.Term.setTim(String) | 0 | 1 | 1 | 1 |
| expr.Term.setXiShu(String) | 0 | 1 | 1 | 1 |
| expr.Terms.Terms(boolean) | 0 | 1 | 1 | 1 |
| expr.Terms.addTerm(Term) | 15 | 4 | 7 | 7 |
| expr.Terms.addTerms(Terms) | 2 | 1 | 3 | 3 |
| expr.Terms.getTerms() | 0 | 1 | 1 | 1 |
| expr.Terms.isEmpty() | 0 | 1 | 1 | 1 |
| expr.Terms.multMoreTerms(int) | 2 | 1 | 2 | 3 |
| expr.Terms.multTerms(Terms) | 3 | 1 | 3 | 3 |
| Total | 153.0 | 41.0 | 75.0 | 83.0 |
| Average | 6.954545454545454 | 1.8636363636363635 | 3.409090909090909 | 3.7727272727 |
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Mainclass | 16 | 16 | 16 |
| expr.Expr | 4.43 | 10 | 31 |
| expr.Term | 1.14 | 2 | 8 |
| expr.Terms | 2.57 | 6 | 18 |
可以看到,在“可回溯”方案下,平均复杂度是很高的,由于MainClass中直接实现了输入,处理和输出过程,其复杂度是极高的。而紧随其后的getLower,getTerm等方法等方法也因为上文提到的“复杂的判断模式”复杂度极高。这些方法可读性很差,思考的地方太多。虽然第一次作业的代码量只有300多行,但是却耗费了我大量的时间。
1.3 关于bug
由于时间分配原因,第一次作业我未能按时完成,但我自己构造了数据,并测试了一些其他同学的数据(包括他们被hack的点),目前是没有找到bug的。
2 第二次作业
在第二次作业中,我没有及时重构,最终也没能评测,因此实际上我是跳过了第二次,直接实现了第三次作业。接下来是我在第二次作业的失败经历中总结的经验。
2.1 “不回溯”方法理论可行,实际难度大
由于没有嵌套的括号,理论上依然可以不划分结构,并只用读一遍字符串就解析出结果。但实际上这样做会比第一次的判断更加复杂,比如当遇到自定义函数,需要判断出每一个实参在字符串的右边界,这个右边界既可以是逗号,也可以是右括号(即函数的右括号),但是‘)’也可以在实参内部。也就是说需要在之前遇到左括号的时候就进行记录,来判断右括号是属于哪种。这种做法已经很接近不被推荐的”栈结构“了,已经偏离了这一单元的核心。
2.2 不要害怕递归,不要试图用一层结构存所有东西。
这个经验是我在意识到通过”不回溯“方法凭我自身实力实现不了但已经来不及重写一遍时对下一次作业的提前准备,当时我预测第三次作业应该是要求嵌套了。
先说标题前半句:我的结论是只要能找到能使递归结束的点,写递归是很容易的。在这一单元的任务中,递归结束的点就是“x"或数字。sin函数里面可以套一个sin,可以套sin再加上其他的各种各样的东西,但是迭代到最后s三角函数里一定是一个只包含幂函数和数字之和的表达式,只要解析好这个表达式,就可以一层一层的返回。
但在有了上述思考之后,我依然有认知上的误区,我希望的结果如下:最上层是表达式,表达式是项的聚合,项里是因子的乘积,因子是最小单元。
我之所以会这样想,还源于另一个问题:如果结构不是这样的,那我该如何将结果输出呢,一个因子是可以写toString方法的,但是要是因子套了其他东西,比如一个表达式,toString方法怎么写呢?调用这 个表达式的toString吗?可这个表达式里还可以有sin。。。
后来我才意识到,其实这还是我没有深刻理解递归:递归是可以结束的,在sin里可以存也可以调用表达式的toString,因为正如上文的分析,表达式迟早会变成幂函数和数字的和,这时他的toString就明确了,递归到达了最深的一层,然后可以逐层的解套。当然,为了让答案更短,可以进行特判。
第三次作业
有了之前的积累,第三次作业完成较顺利。除了在合并的时候遇到了一点困难。
3.1 层次结构

先说整体框架:首先设置了Factor类,其子类有XFactor,SinFactor,CosFactor,和SelfFactor。前三者用于组成Term,SelfFactor用于存储自定义函数的信息。Term组成Expr。Term中有addFactor方法来加入因子,有mulTerm方法来返还两个项乘积的结果。Expr中有addTerm方法来加入一个项,在addTerm的基础上,mult方法实现了Express的各种运算,除此之外还有负责运算的add和multMore方法负责Expr之间的加法和乘方。
可以看到有三个迭代器类:ExprIt,TermIt,SelfIt。ExprIt在Expr类的parse方法中使用:ExprIt接受一个字符串,每调用一次matchTerm方法返还一个项的字符串,通过hasNext来判断是否还有下一项。TermIt类似于ExprIt,是在Term的parse方法中使用,每次返还一个Factor字符串。而SelfIt则负责逐次返还自定义函数的实参的字符串。
在获取Factor级别的字符串后,工具类Tools中的方法实现了将字符串变成对象的过程。虽然Tools中的方法都是“parsexxxFactor"但实际上他们返还的都是Expr。这里大家可能会有些疑惑,如果是表达式因子,那返还Expr是可以的,为什么其他因子也要返还Expr呢?首先这样做形式更统一,而更关键的是:这样利于特殊情况的处理。比如对于sin(0),就可以进行如下的处理。
temp = Expr.parseExpr(string.substring(4, string.length() - 1));
if (temp.getTerms().isEmpty()) {
return temp;
}
这段代码是parseSinFactor的一部分。先对sin内部的字符串进行了处理得到一个Expr,返还到temp。若temp为空(空代表0),则直接向上返还temp这个空表达式,也就是0。
此外,可以看到,虽然在Tools中有关于ExprFactor和SumFactor的解析方法,但我并没有设置这两个类,一方面,在最终答案中这两种因子是不允许出现的,而且也没有必要像SelfFactor一样事先存储;另一方面,这是因为这两个解析方法调用了Expr类中的parse方法,和乘方方法,这足以解决问题,不用再设置这两个类了。
3.2代码结构
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expr.Expr.Expr() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.setTerms(HashSet) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.ExprIt.ExprIt() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.ExprIt.ExprIt(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.ExprIt.hasNext() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.SelfIt.SelfIt() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.SelfIt.SelfIt(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.SelfIt.hasNext() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.getCoe() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.setCoe(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.setFactors(HashSet) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.TermIt.TermIt() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.TermIt.TermIt(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.TermIt.hasNext() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.CosFactor.CosFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.CosFactor.CosFactor(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.CosFactor.getInter() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.CosFactor.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.CosFactor.setInter(Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.Factor.getIndex() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.Factor.setIndex(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.Factor.similar(Object) | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SelfFactor.SelfFactor(int, ArrayList, String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SelfFactor.getArguNames() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SelfFactor.getArguNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SelfFactor.getFuncName() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SelfFactor.getInter() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SinFactor.SinFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SinFactor.SinFactor(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SinFactor.getInter() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SinFactor.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.SinFactor.setInter(Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| factor.XFactor.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| tool.Tools.preWork(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Mainclass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.parseExpr(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.equals(Object) | 1.0 | 2.0 | 2.0 | 2.0 |
| factor.CosFactor.equals(Object) | 1.0 | 2.0 | 1.0 | 2.0 |
| factor.SinFactor.equals(Object) | 1.0 | 2.0 | 1.0 | 2.0 |
| factor.XFactor.equals(Object) | 1.0 | 2.0 | 1.0 | 2.0 |
| factor.XFactor.similar(Object) | 1.0 | 2.0 | 1.0 | 2.0 |
| tool.Tools.parseSumFactor(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Mainclass.createSelf(String) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.add(Expr) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.mult(Factor) | 2.0 | 2.0 | 2.0 | 3.0 |
| expr.Term.addFactor(BigInteger) | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.multTerm(Term) | 2.0 | 1.0 | 3.0 | 3.0 |
| factor.XFactor.toString() | 2.0 | 2.0 | 2.0 | 2.0 |
| expr.Expr.multMore(BigInteger) | 3.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.mult(BigInteger) | 4.0 | 2.0 | 3.0 | 3.0 |
| expr.ExprIt.matchParen() | 4.0 | 1.0 | 2.0 | 4.0 |
| expr.SelfIt.matchParen() | 4.0 | 1.0 | 2.0 | 4.0 |
| expr.TermIt.matchParen() | 4.0 | 1.0 | 2.0 | 4.0 |
| expr.Expr.mult(Expr) | 5.0 | 2.0 | 4.0 | 5.0 |
| expr.SelfIt.matchSelf() | 5.0 | 1.0 | 4.0 | 4.0 |
| expr.TermIt.matchFactor() | 5.0 | 1.0 | 4.0 | 4.0 |
| factor.CosFactor.similar(Object) | 5.0 | 3.0 | 3.0 | 3.0 |
| factor.SinFactor.similar(Object) | 5.0 | 3.0 | 3.0 | 3.0 |
| tool.Tools.parseSelfFactor(String) | 5.0 | 1.0 | 4.0 | 4.0 |
| tool.Tools.parseXFactor(String) | 5.0 | 3.0 | 3.0 | 3.0 |
| expr.Term.addFactor(Factor) | 6.0 | 3.0 | 5.0 | 5.0 |
| expr.Expr.addTerm(Term) | 7.0 | 4.0 | 4.0 | 5.0 |
| tool.Tools.parseExprFactor(String) | 7.0 | 3.0 | 3.0 | 4.0 |
| factor.CosFactor.toString() | 8.0 | 2.0 | 6.0 | 7.0 |
| factor.SinFactor.toString() | 8.0 | 2.0 | 6.0 | 7.0 |
| expr.ExprIt.matchTerm() | 12.0 | 5.0 | 8.0 | 8.0 |
| expr.Term.parseTerm(String) | 12.0 | 1.0 | 11.0 | 11.0 |
| expr.Term.toString() | 12.0 | 3.0 | 6.0 | 6.0 |
| expr.Expr.toString() | 13.0 | 2.0 | 5.0 | 5.0 |
| tool.Tools.parseCosFactor(String) | 13.0 | 5.0 | 4.0 | 6.0 |
| tool.Tools.parseSinFactor(String) | 13.0 | 5.0 | 4.0 | 6.0 |
| expr.Expr.equals(Object) | 14.0 | 6.0 | 4.0 | 6.0 |
| expr.Term.similar(Object) | 14.0 | 6.0 | 4.0 | 6.0 |
| Total | 213.0 | 131.0 | 177.0 | 201.0 |
| Average | 2.597560975609756 | 1.5975609756097562 | 2.158536585365854 | 2.451219512195122 |
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| expr.Term | 2.8666666666666667 | 11.0 | 43.0 |
| expr.Expr | 2.6666666666666665 | 6.0 | 40.0 |
| tool.Tools | 3.7142857142857144 | 6.0 | 26.0 |
| factor.CosFactor | 1.875 | 5.0 | 15.0 |
| factor.SinFactor | 1.875 | 5.0 | 15.0 |
| expr.ExprIt | 2.6 | 6.0 | 13.0 |
| expr.SelfIt | 2.0 | 4.0 | 10.0 |
| expr.TermIt | 2.0 | 4.0 | 10.0 |
| factor.XFactor | 1.75 | 2.0 | 7.0 |
| factor.SelfFactor | 1.0 | 1.0 | 5.0 |
| Mainclass | 2.0 | 2.0 | 4.0 |
| factor.Factor | 1.0 | 1.0 | 3.0 |
| Total | 191.0 | ||
| Average | 2.3292682926829267 | 4.416666666666667 | 15.916666666666666 |
可以看到整体看复杂度并不高,但是各种parse方法以及addTerm方法复杂度很高。parse方法的复杂度高是可以理解的。而addTerm复杂是因为在该方法中实现了合并同类项,以及在某一项系数为0时需要将其剔除的过程。判断量增加了。
3.3关于bug
第三次作业我被发现的bug有一处,也就是广为流传的sum(i**2)。这个bug是很好改的,只要在替换字符串时将i变为(i)即可。
对于做过第二次作业的同学,这个bug可能更容易出现,因为可能没有仔细再看一遍sum函数的要求。但是对我来说,这样的bug反而是不太能接受的,完全是想的不够细致导致的。在被轮番轰炸30多次的情况下,我很庆幸只被hack了四次,感谢室友们。
4 关于hack
我成功地hack了两个点,第一个便是sum(i**2) 第二个是关于遇到减号是符号的转换问题。
对于sum(i**2),正如上文所说,是两次作业规则不同导致的,就是看大家有没有仔细看指导书。
对于第二个hack,这是来自我同学的建议,他在处理减号时,曾经直接把每一个Term的正号变成符号,负号变成正号 结果遇到了
-sin((-(1+x))),在他的处理方法下就变成了-sin((-(1-x)))然后就错了。
5 关于架构
在第一次作业中,我采用的是“不回溯”也不截取字符串的架构,上文已经论述了其巨大的缺点。因此在第三次作业中我改成了递归下降的嵌套结构。由于经历了痛苦的重构过程,我深刻体会到:在写代码之前多动动脑子是很重要的。尽量增加代码的扩展性,比如本次作业中从不嵌套改为嵌套是很难直接实现的,这在设计阶段就要考虑好。lzqnb!!!
6 心得体会
不得不说,在本学期刚开始时我就瞬间感受到了OO课程的压迫感。在假期,我并没有采取正确的策略:我更多的倾向于先听完java的网课再去做pre,结果再第一次作业开始时还对git等工具不太熟悉,导致了第一周时间的大量损失,以致最后没能完成。而第二周又由于没及时重构再次GG。pre确实很重要!!!。pre确实很重要!!!
