
redis(二)入门和数据类型的简单介绍
redis是什么?
C写的开源基于内存的高性能非关系型键值对数据库。底层采取epoll读写速度非常快,大多用于缓存,也提供了事务、持久化、分布式锁、消息队列、集群以及多种数据类型的功能。
什么时候需要用到redis?
首先我们明确几个常识问题:磁盘寻址是ms级别,带宽为G/M级别。而内存的寻址是n/s级别,在寻址上磁盘比内存慢了10W倍,内存的带宽也特别大。I/O buffer:磁盘有磁道和扇区,一个扇区512Byte带来成本变大:索引,
所以操作系统每次读取磁盘都是读取4K,无论读多少都是4K。总的来说就是内存比磁盘快很多,对于磁盘的读取的最小单位是4K。
我们知道传统的关系型数据库,这里以mysql为例子,数据都是存储在磁盘的。当数据量越来越大的时候,必然会出现I/O瓶颈,当并发量大的时候,硬盘带宽的限制也十分明显。当然索引可以解决一部分问题,我们先来大致
分析mysql索引的实现原理。mysql的会在内存中维护一个B+树,树的每个节点维护对应索引的区间,这些区间和磁盘中具体的索引信息对应,这些具体的索引信息又和磁盘中的具体存储的数据进行对应。所以假设在查询的时候,如果
数据量很小且命中索引的情况就下,数据量增大几乎没什么影响。但是当查询的数据量很大,且并发很大的时候,mysql数据库就会受制于I/O和带宽的限制,性能会受到极大的影响。
这个时候,我们就需要用到缓存,来缓解关系型数据库的压力。常用的缓存架构有memcached和redis,我们先来看看memcached和redis的区别:
-
redis可以存储的数据类型十分丰富,下面会介绍。但是memcached没用数据类型的概念。(计算向数据移动)
-
当物理内存满的时候,redis可以将不常用的数据swap到磁盘,而memcached不支持。
-
存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);
-
灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
-
Redis支持数据的备份,即master-slave模式的数据备份;
从上面的对比,我们可以很清晰的看到redis的优势,所以现在memcached正在慢慢被淘汰,接下来,我们来看看为什么redis性能高。
redis为什么快?
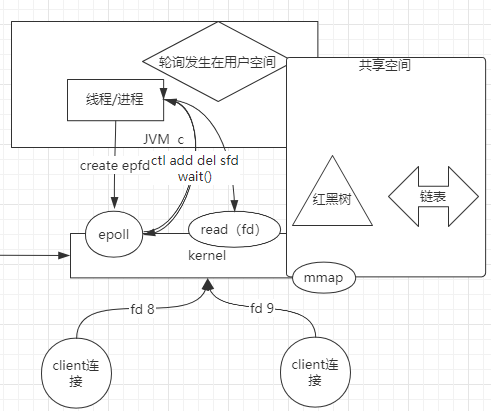
首先redis对于数据的处理是单进程、单线程、单实例的,避免了多个线程切换带来的性能消耗。其次,其底层是通过linux kernel 的epplo实现的,效率极高。
我们再来看linux的epplo是如何实现的,为什么效率这么高。
如何在linux上使用redis:
上一篇文章,介绍了如何在linux上安装redis,那么我们该如何使用它呢。在redi启动的情况下执行redis-cli命令,如图所示:
每一个redis服务包含16个库,下标0-15。如果我们在往redis放入数据的时候,不指定库,那么默认使用0库,我们来看看如何往指定数据库存入数据
执行select index命令(index为数据库的下标),比如我要切换到下标为2的数据库,如下图所以,切换之后会多一个2的标识:
我们来看看如何使用redis的命令,输入help命令,如下图所示:
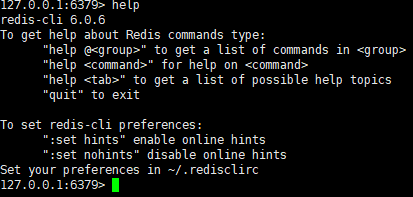
这里介绍了如何通过help来学习redis的命令,help @<group>指的是可以查看redis各个分组的命令,Redis命令十分丰富,包括的命令组有Cluster、Connection、Geo、Hashes、HyperLogLog、Keys、Lists、Pub/Sub、Scripting、Server、Sets、Sorted Sets、Strings、Transactions一共14个redis命令组两百多个redis命令,想要详细了解的话,参考http://www.redis.cn/commands.html。help后面还可以直接跟你想要了解的命令,还可以通过tab自动补全,这里也指出了通过quit可以退出redis客户端。
redis key的简单介绍:
我们都知道redis是key-value型的数据库,那么redis对key有什么限制呢?
Redis key值是二进制安全的,这意味着可以用任何二进制序列作为key值,空字符串也是有效key值。redis的key需满足以下规则:
- 键值不能太长,例如1024字节的键值就不合适,不仅因为消耗内存,而且在数据中查找这类键值的计算成本很高。
- 太短的键值也不合适,如果你要用”u:1000:pwd”来代替”user:1000:password”,这没有什么问题,但后者更易阅读,并且由此增加的空间消耗相对于key object和value object本身来说很小。当然,没人阻止您一定要用更短的键值节省一丁点儿空间。
- 最好坚持一种模式。例如:”object-type:id:field”就是个不错的注意,像这样”user:1000:password”。我喜欢对多单词的字段名中加上一个点,就像这样:”comment:1234:reply.to”。(这个是官网的描述,我一般使用都是通过下划线隔开,比如user_1000_password)
redis的数据类型的简单介绍:
- Strings:二进制安全的字符串。
- Lists: 按插入顺序排序的字符串元素的集合。他们基本上就是链表(linked lists)。
- Sets: 不重复且无序的字符串元素的集合。
- Sorted sets,类似Sets,但是每个字符串元素都关联到一个叫score浮动数值(floating number value)。里面的元素总是通过score进行着排序,所以不同的是,它是可以检索的一系列元素。(例如你可能会问:给我前面10个或者后面10个元素)。
- Hashes,由field和关联的value组成的map。field和value都是字符串的。这和Ruby、Python的hashes很像。
- Bit arrays (或者说 simply bitmaps): 通过特殊的命令,你可以将 String 值当作一系列 bits 处理:可以设置和清除单独的 bits,数出所有设为 1 的 bits 的数量,找到最前的被设为 1 或 0 的 bit,等等。
- HyperLogLogs: 被用于估计一个 set 中元素数量的概率性的数据结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号