
4.python函数基础
一.函数
1.函数简介
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
例如:
不用函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
while True: if cpu利用率 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 硬盘使用空间 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 内存占用 > 80%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 |
如果使用函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def 发送邮件(内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件('CPU报警') if 硬盘使用空间 > 90%: 发送邮件('硬盘报警') if 内存占用 > 80%: 发送邮件('内存报警') |
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
-
函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
-
面向对象:对函数进行分类和封装,让开发“更快更好更强...”
2.函数的定义及使用
(1)定义一个函数
以下是简单的规则:
-
函数代码块以def关键词开头,后接函数标识符名称和圆括号()。
-
任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
-
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
-
函数内容以冒号起始,并且缩进。
-
Return[expression]结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
以下是如下要点:
-
def:表示函数的关键字
-
函数名:函数的名称,日后根据函数名调用函数
-
函数体:函数中进行一系列的逻辑计算,如:实现报警,发送邮件。
-
参数:为函数体提供数据
-
返回值:当函数执行完毕后,可以给调用者返回数据。
语法:
|
1
2
3
4
|
def 函数名( 参数 ): "函数_文档字符串" 执行函数体 return [返回值] |
注:默认情况下,参数值和参数名称是按函数声明中定义的的顺序匹配起来的。
例:
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
|
1
2
3
4
5
6
7
|
# 定义函数>>> def hello():... print ('Hello World!')... # 调用函数>>> hello()Hello World! |
调用:
|
1
2
3
4
5
6
7
8
9
|
#!/usr/bin/python# 定义函数>>> def func(str):"打印任何传入的字符串"... print (str)...# 调用函数>>> func('yaoyao')yaoyao |
3.返回值
(1)return语句
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。
Python的函数的返回值使用return语句,可以将函数作为一个值赋值给指定变量:
该功能到底执行成功与否,需要通过返回值来告知调用者。
例:
|
1
2
3
4
5
|
def return_sum(x,y): c = x + y return cres = return_sum(4,5)print(res) |
|
1
2
3
4
5
|
def 接受用户和密码(user,passwd): if 用户和密码正确: return True else: return False |
4.参数
1.有参数实现
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
def CPU报警邮件() #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接def 硬盘报警邮件() #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接def 内存报警邮件() #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: CPU报警邮件() if 硬盘使用空间 > 90%: 硬盘报警邮件() if 内存占用 > 80%: 内存报警邮件() |
2.有参数实现
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def 发送邮件(邮件内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件("CPU报警了。") if 硬盘使用空间 > 90%: 发送邮件("硬盘报警了。") if 内存占用 > 80%: 发送邮件("内存报警了。") |
函数的有三中不同的参数:
普通参数
默认参数
动态参数
(1)普通参数
|
1
2
3
4
5
6
7
8
9
|
# ######### 定义函数 ######### # name 叫做函数func的形式参数,简称:形参def func(name): print name# ######### 执行函数 ######### # 'liuyao' 叫做函数func的实际参数,简称:实参func('liuyao') |
(2)默认参数
|
1
2
3
4
5
6
7
8
9
10
|
def func(name, age = 21): print "%s:%s" %(name,age)# 指定参数func('liuyao', 21)# 使用默认参数func('yaoyao')注:默认参数需要放在参数列表最后 |
(3) 动态参数-序列
|
1
2
3
4
5
6
7
8
9
10
11
|
def func(*args): print args# 执行方式一func(11,33,4,4454,5)# 执行方式二li = [11,2,2,3,3,4,54]func(*li) |
(4)动态参数-字典
|
1
2
3
4
5
6
7
8
9
10
11
|
def func(**kwargs): print args# 执行方式一func(name='liuyao',age=21)# 执行方式二li = {'name':'liuyao', age:21, 'job':'IT'}func(**li) |
(5)动态参数-序列和字典
|
1
2
3
4
|
def func(*args, **kwargs): print args print kwargs |
5.内置函数(Built-in Functions)
The Python interpreter has a number of functions and types built into it thatare always available. They are listed here in alphabetical order.
官方文档:点击
1.abs()【绝对值】
|
1
2
3
4
5
6
7
|
>>> abs(-10)10>>> abs(10)10>>> a=-10>>> a.__abs__()10 |
2.all()集合中的元素都为真的时候为真,若为空串返回为True
|
1
2
3
4
5
6
|
>>> li = ['yao','liu']>>> li_1=[]>>> print(all(li))True>>> print(all(li_1))True |
3.any()集合中的元素有一个为真的时候为真若为空串返回为False
|
1
2
3
4
5
6
7
8
9
|
>>> li['yao', 'liu']>>> li_1[]>>> print(any(li))True>>> print(any(li_1))False>>> |
4.chr()返回整数对应的ASCII字符
|
1
2
|
>>> print(chr(65))A |
5.ord()返回字符对应的ASC码数字编号
|
1
2
3
|
>>> print(ord('A'))65>>> |
6.bin(x)将整数x转换为二进制字符串
|
1
2
3
|
>>> print(bin(10))0b1010>>> |
7.bool(x)返回x的布尔值
|
1
2
3
4
5
|
>>> print(bool(0))False>>> print(bool(1))True>>> |
8.dir()不带参数时,返回当前范围内的变量、方法和定义的类型列表,带参数时,返回参数的属性、方法列表。
|
1
2
3
4
|
>>> dir()['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'li', 'li1', 'li2', 'li_1']>>> dir(list)['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] |
9.divmod()分别取商和余数.
|
1
2
|
>>> divmod(20,6)(3, 2) |
10.enumerate()返回一个可枚举的对象,该对象的next()方法将返回一个tuple
|
1
2
3
4
5
6
7
|
>>> info = ['liu','yao','sb']>>> for k,v in enumerate(info):... print(k,v)... 0 liu1 yao2 sb |
11.eval()将字符串str当成有效的表达式来求值并返回计算结果。
|
1
2
3
4
|
>>> name = '[[1,2], [3,4], [5,6], [7,8], [9,0]]'>>> a = eval(name)>>> print(a)[[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]] |
12.filter(function, iterable)函数可以对序列做过滤处理
|
1
2
3
4
5
6
7
|
>>> def guolvhanshu(num):... if num>5 and num<10:... return num>>> seq=(12,50,8,17,65,14,9,6,14,5)>>> result=filter(guolvhanshu,seq)>>> print(list(result))[8, 9, 6] |
13.hex(x)将整数x转换为16进制字符串。
|
1
2
|
>>> hex(21)'0x15' |
14.id()返回对象的内存地址
|
1
2
|
>>> id(22)10106496 |
15.len()返回对象的长度
|
1
2
3
|
>>> name = 'liuyao'>>> len(name)6 |
16.map遍历序列,对序列中每个元素进行操作,最终获取新的序列。
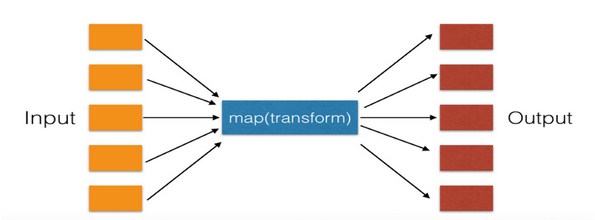
例:
|
1
2
|
li = [11, 22, 33]li_1 = map(lambda a: a + 100, li) |
|
1
2
3
|
li = [11, 22, 33]sl = [1, 2, 3]lit = map(lambda a, b: a + b, li, sl) |
17.oct()八进制转换
|
1
2
3
|
>>> oct(10)'0o12'>>> |
18.range()产生一个序列,默认从0开始
|
1
2
3
|
>>> range(14)range(0, 14)>>> |
19.reversed()反转
|
1
2
3
4
5
6
7
8
|
>>> re = list(range(10))>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> re_1 = reversed(re)>>> re_1<list_reverseiterator object at 0x7f50d1788be0>>>> print(list(re_1))[9, 8, 7, 6, 5, 4, 3, 2, 1, 0] |
20.round()四舍五入
|
1
2
3
4
|
>>> round(4,6)4>>> round(5,6)5 |
21.sorted()队集合排序
|
1
2
3
4
|
>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> sorted(re)[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
22.sum()对集合求和
|
1
2
3
4
5
6
|
>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> type(re)<class 'list'>>>> sum(re)45 |
23.type()返回该object的类型
|
1
2
3
4
|
>>> re[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> type(re)<class 'list'> |
24.vars()返回对象的变量,若无参数与dict()方法类似。
|
1
2
|
>>> vars(){'v': 'sb', 'a': [[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]], 'k': 2, '__builtins__': <module 'builtins' (built-in)>, 're': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'info': ['liu', 'yao', 'sb'], '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__doc__': None, 'li2': ['name', []], 're_1': <list_reverseiterator object at 0x7f50d1788be0>, 'guolvhanshu': <function guolvhanshu at 0x7f50d1874bf8>, 'li1': [], 'name': 'liuyao', 'seq': (12, 50, 8, 17, 65, 14, 9, 6, 14, 5), '__spec__': None, 'li_1': [], 'li': ['yao', 'liu'], '__name__': '__main__', 'result': <filter object at 0x7f50d1788ba8>, '__package__': None} |
25.zip()zip函数接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表。
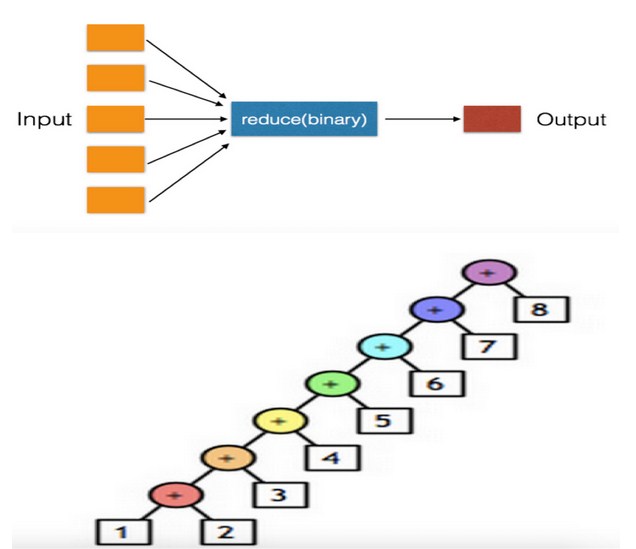
26.reduce对于序列内所有元素进行累计操作
|
1
2
3
4
5
6
7
|
li = [11, 22, 33]result = reduce(lambda arg1, arg2: arg1 + arg2, li)# reduce的第一个参数,函数必须要有两个参数# reduce的第二个参数,要循环的序列# reduce的第三个参数,初始值 |
6.open函数(该函数用于文件处理)
1.操作文件步骤:
打开文件
操作文件
关闭文件
2.打开文件模式:
|
1
|
file = open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件 |
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
关于open 模式:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
w 以写方式打开,a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)r+ 以读写模式打开w+ 以读写模式打开 (参见 w )a+ 以读写模式打开 (参见 a )rb 以二进制读模式打开wb 以二进制写模式打开 (参见 w )ab 以二进制追加模式打开 (参见 a )rb+ 以二进制读写模式打开 (参见 r+ )wb+ 以二进制读写模式打开 (参见 w+ )ab+ 以二进制读写模式打开 (参见 a+ )U" 表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)rUrU+ |
3.文件操作
1.关闭文件
|
1
|
file.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError |
2.返回一个长整型的”文件标签“
|
1
|
fp.fileno() |
3.读取指定字节数据
|
1
|
fp.read([size]) #size为读取的长度,以byte为单位 |
3.读一行
|
1
|
fp.read([size]) #size为读取的长度,以byte为单位 |
4.文件每一行作为一个list的一个成员,并返回这个list。
|
1
|
fp.readlines([size]) #其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。 |
5.写入
|
1
|
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符 |
6.全部写入
|
1
|
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。 |
7.把缓冲区的内容写入硬盘
|
1
|
fp.flush() |
8.判断文件是否为设备文件
|
1
|
fp.isatty() #文件是否是一个终端设备文件(unix系统中的) |
9.获取指针位置
|
1
|
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点 |
10.指定文件中指针位置
|
1
|
fp.seek(offset[,whence]) |
#将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
11.返回下一行
|
1
|
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。 |
12.文件裁成规定的大小
|
1
|
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。 |
3.指针是否可操作
|
1
|
seekable() 指针是否可操作 |
14.是否可写
|
1
|
writable() |
7.with函数管理文件
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
|
1
2
3
|
with open('log','r') as f: ... |
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
|
1
2
|
with open('log1') as obj1, open('log2') as obj2: pass |
8.lambda表达式
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
|
1
2
3
4
5
6
7
8
|
# 普通条件语句if1==1: name ='wupeiqi'else: name ='alex' # 三元运算name ='wupeiqi'if1==1else'alex' |
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# ###################### 普通函数 ####################### 定义函数(普通方式)deffunc(arg): returnarg +1 # 执行函数result =func(123) # ###################### lambda ###################### # 定义函数(lambda表达式)my_lambda =lambdaarg : arg +1 # 执行函数result =my_lambda(123) |
lambda存在意义就是对简单函数的简洁表示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号