


1、观点差异
- K8s专为管理长时间运行的流程而构建的
协调多个微服务,扩展、管理可用性,通常支持一个或多个web服务
- 云原生系统假设有"infinite"可用资源
优先级不是云编排的核心,体现在调度语义上,"Affinity"与"Anti-Affinity"设置不能转换为批处理工作流程
- HPC系统假设系统大小是固定的
但是工作量是无限的,队列优先级对于大多数大型系统至关重要
- Slurm是一个策略引擎
- Slurm涵盖了几个相关的HPC系统管理任务
作业排队和优先级,作业记账,用户对计算资源的访问控制(cgroups、pam_slurm_adopt),大规模作业启动(MPI、PMIx、nss_slurm、sbcast)
2、Kubernetes Batch支持
- K8s对批处理工作流程的支持有限
以"pods"或"jobs"为模型,由于"jobs"模型的问题,大多数工作流使用"pods"
- 优先级模型有限
先进先出是最常见的
- MPI风格的工作负载支持较弱
默认K8s组件不保证并发pod调度
- "MPI Operator"是确保Pod同时启动的最常用组件
无法扩大规模,很难达到80(!)以上的ranks
3、HPC 与云原生的融合
- 弥合HPC和云原生工作负载之间的差距
- 用一种方法,将熟悉的命令、工具和优先级模型引入到新的架构中
4、可能的模型
从Slurm的角度来看,可能的方法有:
- "Over"
- "Adjacent"
- "Under"
4.1、"Over"

- Slurm管理资源
- 在批处理作业中临时创建的K8s集群
- 在作业启动之前,K8s control plane不可用...
- 除了测试/开发之外不用特别有用
4.2、"Adjacent"

- 两个control plane重叠
- 安装Slurm K8s调度器插件
让Slurm优先考虑并安排 Slurm 和 K8s 工作负载
- K8s作业通过kubelet运行
拥有K8s的全部能力
- Slurm作业通过Slurm运行
高吞吐量,支持大规模MPI工作
- POC(Proof-of-concept)已经开始工作
通过"slurm-k8s-bridge" K8s调度程序插件
- 局限性
K8s调度只关心节点
- 目前没有进一步的粒度可用
正在努力做到这一点,但变更很难向上游推进
Slurm调度插件忽略了亲和/反亲和以及其他K8s调度机制,因为它们没有直接建模到传统的HPC概念
4.3、"Under"
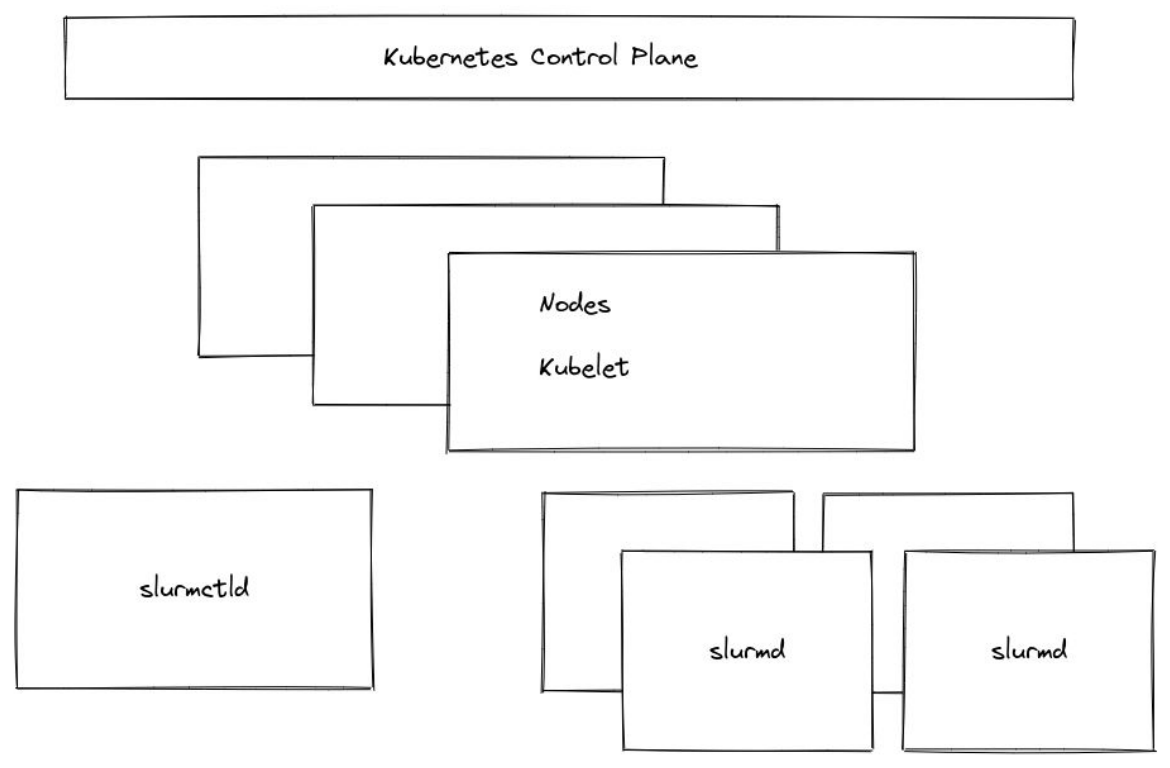
- 在K8s环境中运行Slurm集群
- K8s云原生提供商已经出现
- 长期"login"节点(pod)提供传统用户体验
- 自动缩放可用于将资源移入/移出 Slurm 的控制
优点
- Slurm用户的传统体验
- 允许更高的吞吐量和完整的MPI支持
缺点
- K8s的工作负载超出了Slurm的范围
- Slurm和K8s工作负载之间的优先级很难确定
- K8s调度的所有限制均适用
