
第七周作业
1. 总结pg和mysql的优劣势。
pgsql的主要优势:
- pgsql 完全免费,而且是BSD协议,没有被大公司垄断,在使用和二次开发上基本没有限制。而mysql数据库虽然是开源的,但被oracle收购后,基本上被oracle公司控制。
- 与pgsql配合的开源软件有很多,有很多分布式的集群软件,如pgpool、pgcluster、slony、plploxy等,很容易做读写分离、负载均衡、数据水平拆分等方案,而这在mysql下比较困难
- pgsql源代码写的很清晰,易读性比mysql强太多了,很多公司都是基于pgsql做二次开发。
- pgsql在很多方面都比mysql强,如复杂sql的执行、储存过程、触发器、索引。同时pgsql是多进程的,而mysql是线程的,虽然并发不高时,mysql处理速度快,但当高并发的时候,对于多核的单台机器上,mysql总体处理性能不如pgsql,原因是mysql线程无法充分利用CPU的能力
- pgsql是唯一能做到数据零丢失的开源数据库,稳定可靠。
pgsql的劣势:
pgsql只提供单个完整功能的版本,没有提供多个不同的社区版、商业版与企业版,这就没有像MySQL那样为用户提供更多的选择。
mysql优势:
提供了多个不同的社区版、商业版与企业版,这就为用户提供了更多的选择。
2. 总结pg二进制安装和编译安装。
源码编译安装
#安装依赖包 yum install -y gcc make readline-devel zlib-devel #下载源码 wget https://ftp.postgresql.org/pub/source/v15.5/postgresql-15.5.tar.gz tar xf postgresql-15.5.tar.gz cd postgresql-15.5 ./configure --prefix=/opt/pgsql --with-pgport=5432 make -j 2 world make install-world #创建用户和用户组 useradd -s /bin/bash -m -d /home/postgres postgres #创建数据目录并授权 mkdir -pv /opt/pgsql/data/ chown postgres.postgres /opt/pgsql/data/ #设置环境变量 vim /etc/profile.d/pgsql.sh export PGHOME=/opt/pgsql export PATH=$HOME/bin/:$PATH export PGDATA=/opt/pgsql/data export PGUSER=postgres export MANPATH=/opt/pgsql/share/man:$MANPATH source /etc/profile.d/pgsql.sh #初始化数据库 cd /opt/pgsql su - postgres initdb -A md5 -D $PGDATA -E utf8 --locale=C -U postgres -W #启动数据库 /opt/pgsql/bin/pg_ctl -D /opt/pgsql/data -l logfile start
3. 总结pg数据库结构组织
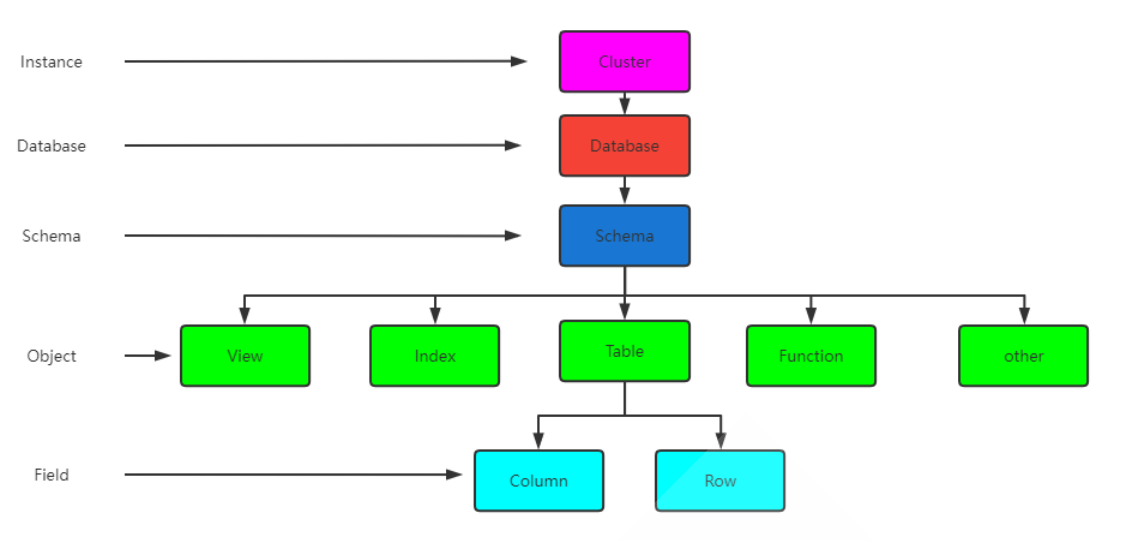
- 实例:一个postgresql对应一个安装的数据目录$PGDATA。即一个instance实例
- 数据库:一个postgresql 数据库服务下可以管理多个数据库,当应用连接到一个数据库时,一般只能访问这个数据库中的数据,而不能访问其他数据库中的内容。默认情况下初始实例只有三个数据库:postgres、template0、template1
- 模式:一个数据库可以创建多个不同的名称空间即Schema,用于分隔不同的业务数据
- 表和索引:一个数据库可以有多个表和索引,在postgresql中表的术语称为relation,而在其他数据库中通常叫table
- 行和列:每张表中有很多列和行数据,在postgresql中行的术语为“tuple”,而在其他数据库中则叫“row”
其他术语
segment:每个表和索引都单独对应一个文件,即为segment,如果文件大小超过1个,会创建多个相同名称但后缀不同的文件
page:表示在磁盘中的数据块,在文件中以块为单位存放数据,默认值为8kb,最大可以为32kb
- template1可以连接,template0不能连接
- 使用template1模板建库时不能指定encoding和locale,而template0可以
注意:template1和template0都不能删除
- 允许多个用户在使用同一个数据库时彼此不干扰
- 把数据库对象放在不同的模式下,然后组织成逻辑组,让它们便于管理
- 第三方的应用可以放在不同的模式下,这样就不会和其他对象的名字冲突了
4.图文并茂总结LSN和WAL日志相关概念
LSN:Log sequence number 用于记录WAL文件当前的位置,这是WAL日志唯一的、全局的标识
WAL 日志中写入是有顺序的,所以必须记录WAL日志的写入顺序。而LSN就是负责给每条产生的WAL日志记录唯一的编号
WAL日志LSN编号规则:高32/低32位
WAL文件名称为16进制的24个字符组成,每8个字符一组

#查看当前LSN postgres=# select pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 0/3000060 #查看当前LSN对应的WAL日志文件 #WAL日志文件中的最后8位的logseg前6位始终是0.最后两位是LSN的低32位的前两位。如logseg中的最后两位是03,LSN低32位的前两位也是03 postgres=# select pg_walfile_name(pg_current_wal_lsn()); pg_walfile_name -------------------------- 000000010000000000000003 #查看当前WAL日志偏移量,LSN在WAL日志文件中的偏移量即低32位中后24位对应的十进制值,如上面000060对应的10进制即下面的96 postgres=# select pg_walfile_name_offset(pg_current_wal_lsn()); pg_walfile_name_offset ------------------------------- (000000010000000000000003,96) #切换WAL日志,默认WAL文件达到16M,自动切换另一个WAL postgres=#select pg_switch_wal();
5.总结日志记录的内容、分类, 优先级别
日志记录的内容包括:
- 历史事件:时间,地点,人物,事件
- 日志级别:事件的关键性程度,loglevel
系统日志分类:
facility:从功能或者程序上对日志进行归类
#内置分类 auth,authpriv,cron,daemon,ftp,kern,mail,news,security(auth),user,syslog #自定义分类 local0-local7
priority优先级别,从低到高排序
debug,info,notice,warn,error,crit,alter,emerg(panic)
6.总结/var/log/目录下常用日志文件作用。
- /var/log/secure:系统安全日志,文本格式,应周期性分析
- /var/log/btmp:当前系统上,用户的失败尝试登录相关的日志信息二进制格式,lastb命令进行查看
- /var/log/wtmp:当前系统上,用户正常的了信息的相关日志信息,二进制格式,last命令可以查看
- /var/log/lastlog:每个用户最近一次的登录信息,二进制格式,lastlog命令查看
- /var/log/dmesg:centos7之前版本系统引导过程中的日志信息,文本格式,开机后的硬件变化将不再记录,也可以通过专用命令dmesg查看,可持续记录硬件变化的情况
- /var/log/boot.log:系统启动的相关信息,文本格式
- /var/log/messages:系统中大部分的信息
- /var/log/anaconda:anaconda日志
7.总结journalctl命令的选项及示例
日志的配置文件:/etc/systemd/journald.conf
journalctl命令格式:journalctl [options...] [matches...]
范例
#查看所有日志(默认情况下,只保存本次启动的日志) journalctl #查看内核日志(不显示应用日志) journalctl -k #查看系统本次启动的日志 journalctl -b journalctl -b -0 #查看上次启动日志 journalctl -b -1 #查看指定时间的日志 journalctl --since=“2024-01-28 10:30:10” journalctl --since "20 min age" journalctl --since 09:00 --until "1 hour age"
#显示尾部的最新10行日志
journalctl -n
#显示尾部的指定行数的日志
journalctl -n 20
#实时滚动显示最新日志
journalctl -f
#查看指定服务的日志
journalctl /usr/lib/systemd/systemd
#查看指定进程的日志
journalctl _PID=1
#查看某个路径的脚本的日志
journalctl /usr/bin/bash
#查看指定用户的日志
journalctl _UID=33 --since today
#查看某个Unit的日志
journalctl -u nginx.service
#实时滚动显示某个Unit的最新日志
journalctl -u nginx.service -f
#日志默认分页输出,--no-pager 改为正常的标准输出
journalctl --no-pager
#日志管理journalctl
#以JSON格式多行输出,可读性更好
journalctl -b -u nginx.service -o json-pretty
#显示日志占据的磁盘空间
journalctl --disk-usage
#指定日志文件占据的最大空间
journalctl --vacuum-size=1G
#指定日志文件保存多久
journalctl --vacuum-time=1years
8.总结DAS, NAS, SAN区别,使用场景
DAS:直连式存储,是最常见的一直存储方式,DAS存储设备主要是磁盘阵列,磁盘簇
NAS:网络附加存储,是文件级的存储方法,主要用来进行文件共享
SAN:存储区域网络,通过光纤通道或以太网交换机连接存储阵列和服务器主机
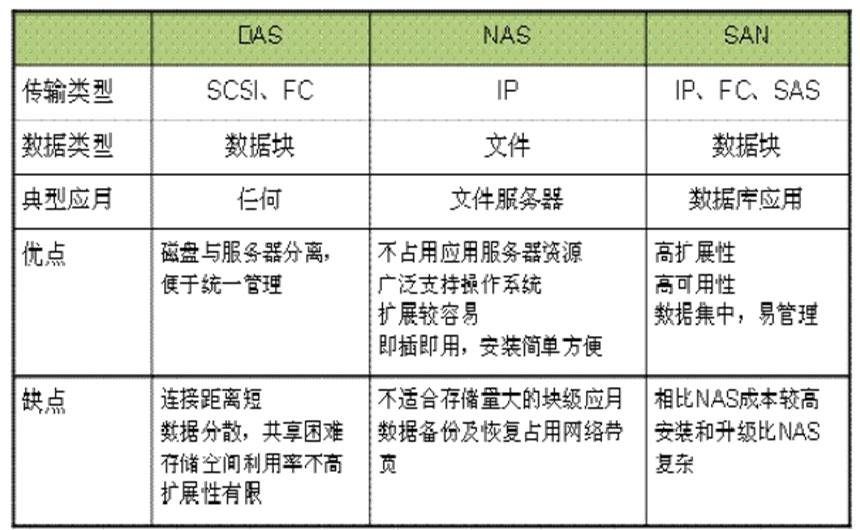
三种存储适用的应用场景
- DAS虽然比较古老。但还是很适用于那些数据量不大,对磁盘访问速度要求较高的中小企业
- NAS多用于文件服务器,用来存储非机构化数据,虽然受限于以太网的速度,但是部署灵活,成本低
- SAN则适用于大型应用或数据库系统,缺点是成本高,较为复杂
9.实时同步技术 inotify+rsync sersync
工作原理:要利用监控服务(inotify),监控同步数据服务器目录中信息的变化;发现目录中数据产生变化,就利用rsync服务推送到备份服务器上
inotify:异步的文件系统事件监控机制,利用事件驱动机制,而无须通过诸如cron等的轮询机制来获取事件,Linux内核从2.6.1起支持inotify,通过inotify可以监控文件系统中添加、删除、修改、移动等各种事件
查看内核是否支持inotify,有下面的文件,说明服务器内核支持inotify
[16:53:47 root@rocky8 log]#ls -l /proc/sys/fs/inotify total 0 -rw-r--r-- 1 root root 0 Jan 30 18:03 max_queued_events -rw-r--r-- 1 root root 0 Jan 30 18:03 max_user_instances -rw-r--r-- 1 root root 0 Jan 30 18:03 max_user_watches
inotify内核参数:
- max_queued_events:inotify事件队列最大长度,如值太小会出现Event queue overflow错误,默认值16384,生产建议调大,比如:327679
- max_user_instances:每个用户创建inotify实例最大值,默认值:128
- max_user_watches:可以监控的文件总数量,默认值:8129,建议调大,比如100000
[root@rocky8 log]#vim /etc/sysctl.conf [root@rocky8 log]#sysctl -p net.ipv4.ip_forward = 1 fs.inotify.max_queued_events = 327679 fs.inotify.max_user_watches = 100000 [root@rocky8 log]#cat /proc/sys/fs/inotify/* 327679 128 100000
rsync服务:
软件包:rsync,rsync-daemon
服务文件:/usr/lib/systemd/system/rsyncd.service
配置文件:/etc/rsyncd.conf
端口:873/tcp
rsync三种格式:
#local:本地文件系统实现同步 rsync [option.. ] src ... [dest] #access via remote shell: 本地主机使用远程shell和远程主机通信 pull : rsync [option.. ] [user@]host:src ... [dest] push: rsync [option.. ] src ... [user@]host:dest #access via rsync daemon:本地主机通过网络套接字连接远程主机上的rsync daemon pull rsync [option.. ] rsync://[user@]host[:port]/src ... [dest] push: rsync [option.. ] src ... rsync://[user@]host[:port]/dest
rsync常见选项:
-v:显示rsync过程中详细信息 -P:显示文件传输的进度信息 -n:仅测试传输,不实际传输 -a:归档模式,表示递归传输并保持文件属性 -r:递归到目录中去 -t:保持time属性。强烈建议任何时候都加上“-t”,否则目标文件mtime会设置为系统时间 -o:保持owner属性 -g:保持group属性 -p:保持扑尔敏是属性(权限,不包括特殊权限) -l:如果文件是软链接文件,则拷贝软链接本身而非软链接所指向的对象 -z:传输时进行压缩提高效率 -R:使用相对路径,意味着将命令中指定的全路径而非路径最尾部的文件名发送给服务端,包括它们的属性 -u:仅在源mtime比目标已存在文件的mtime新时才拷贝。注意,该选项是接受端判断,不会影响删除行为 -d:以不递归的方式拷贝命令本身。默认递归时,如果源为“dir1/file1”,则不会拷贝dir1目录。使用该选项将拷贝dir1,但不拷贝file1 --max-size:限制rsync传输的最大文件大小。如:--max-size=1m --exclude:指定排除规则来排除不需要传输的文件 --delete:以SRC为主,对DEST进行同步,多则删之,少则补之。注意“--delete”是在接受端执行的,所以它是在exclude、include规则生效之后执行的 -b:对目标上已存在的文件做一个备份,备份的文件名后默认使用“~”做后缀 --backup-dir:指定备份文件的保存路径。不指定时默认和待备份文件保存在同一个目录下
-e:指定要使用的远程shell程序,默认ssh
--port:连接daemon时使用的端口,默认873端口
--password-file:daemon模式是的密码文件,可以从中读取密码实现非交互式,是rsync模块的认证密码
-W:rsync将不再使用增量传输,而是全量传输
--existing:要求只更新目标端已存在的文件,目标端不存在的文件不传输。注意,使用相对路径时如果上层目录不存在也不会传输
--ignore-existing:要求只更新目标端不存在的文件
--remove-source-files:要求删除源端已经成功传输的文件
inotify+rsync 使用方式
- inotify对同步数据目录信息的监控
- rsync完成对数据的同步
- 利用脚本进行结合
#!/bin/bash SRC='/data/www/' DEST='rsyncuser@192.168.180.128::backup' rpm -q inotify-tools &> /dev/null || yum -y install inotify-tools rpm -q rsync &> /dev/null || yum -y install rsync inotifywait -mrq --exclude=".*\.swp" --timefmt '%Y-%m-%d %H:%M:%S' --format '%T %w %f' -e create,delete,moved_to,close_write,attrib ${SRC} |while read DATE TIME DIR FILE;do FILEPATH=${DIR}${FILE} rsync -az --delete --password-file=/etc/rsync.pas $SRC $DEST && echo "At ${TIME} on ${DATE}, file $FILEPATH was backuped up via rsync" >> /var/log/changelist.log done
sersync的优点:
- sersync是使用c++编写,而且对Linux系统文件系统产生的临时文件和重复的文件操作进行过滤,所以结合rsync同步的时候,节省了运行时耗和网络资源。因此更快。
- sersync配置简单,其中提供了静态编译好的二进制文件和xml配置文件,直接使用即可
- sersync使用多线程进行同步,尤其在同步大文件时,能够保证多个服务器实时保持同步状态
- sersync有出错处理机制,通过失败队列对出错的文件重新同步,如果仍旧失败,则按设定时长对同步失败的文件重新同步
- sersync不仅可以实现实时同步,另外还自带crontab功能,只需在xml配置文件中开启,既可以按要求隔一段时间整体同步一次,而无需额外配置crontab功能
- sersync可以二次开发
#在数据服务器上安装
wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/sersync/sersync2.5.4_64bit_binary_stable_final.tar.gz
tar -xf sersync2.5.4_64bit_binary_stable_final.tar.gz
cp -a GNU-Linux-x86 /usr/local/sersync
echo 'PATH=/usr/local/sersync:$PATH'> /etc/profile.d/sersync.sh
source /etc/profile.d/sersync.sh
#安装rsync客户端工具
rpm -a rsync &> /dev/null|| dnf -y install rsync10.总结 Redis 常见指令和数据类型
Redis常用命令
- info
[11:33:32 root@rocky8 ~]#redis-cli info server
# Server
redis_version:5.0.3
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:9529b692c0384fb7
redis_mode:standalone
os:Linux 4.18.0-477.10.1.el8_8.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:8.4.1
process_id:95467
run_id:9c7a6d3d5143d4a3fb8ab5c1f72c76179aace7f1
tcp_port:6379
uptime_in_seconds:3897
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:10963609
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
[11:33:45 root@rocky8 ~]#redis-cli info cluster
# Cluster
cluster_enabled:0- select 切换数据库,在集群模式下不支持多个数据库
select 0 select 16 - bgsave 手动在后台执行RDB持久化操作
- dbsize 返回当前库下的所有key数量
- flushdb 清空当前库中所有的key,此命令慎用
- flushall q清空当前Redis服务器中所有的数据库中的key
- keys
set key value #设置key-value
get key #获取key-value
del key #删除key-value
setnx setxx #根据key是否存在,设置key-value
Incr decr #计数
mget mset #批量操作key-value
mset key1 value1 key2 value2
set name wang ex 100 #设置key的生存时间为100s
ttl key #查看key的 剩余生存时间
persist key #取消key的期限lpush key value [value ...] #最左边插入
rpush key value [value ...] #最右边插入
#如果key 不存在,一个空列表会被创建并执行lpush操作,当key存在但不是列表类型时,返回一个错误
llen list1 #获取列表长度(元素个数)
lindex list1 0 #获取0编号元素
lindex list1 -1 #获取最后一个元素
lrange list1 0 -1 #获取所有元素
lset list1 2 java #修改列表指定索引值
lpop list1 #删除第一个元素
rpop list1 #删除最后一个元素
LTRIM list1 1 2 #只保留1,2号元素set 集合 无序,无重复,集合间操作
SADD set1 v1 #创建集合
sadd set1 v2 v3 #只能追加不存在的数据,不能追加已存在的数据
smembers set1 #获取集合中所有的元素
srem set1 v2
sinter set1 set2 #取集合的交集,可以实现共同的朋友
sunion set1 set2 #取集合的并集
sdiff set1 set2 #取集合的差集,可以实现我的朋友的朋友zadd zset1 1 v1 #创建有序集合,分数1可以重复
zadd course 90 linux 99 go 60 python 50 cluod
zrange course 0 -1 #正序排序后按score从小到大显示集合中所有元素
zrevrange course 0 -1 #倒序排序后显示集合内所有key,score 从大到小显示
zrevrange course 0 -1 withscores #倒序排序后显示集合内所有key和得分情况
zcard course
zcard zset1 #查看集合的成员个数
zrank course Python #查询指定数据的排名
zscore couerse cloud #获取分数
zrem course linux #删除元素Linux#创建哈希
HSET hash field value
hset 9527 name zhouxingxing age 20
hgetall 9527 #查看所有字段值
hset 9527 gender male #增加字段
hget 9527 name #查看hash的指定field的value
hdel 9527 age #删除hash的指定field/value
hkeys 9527 #查看hash所有field
hvals 9527 #查看hash所有value
del 9527 #删除hash
 浙公网安备 33010602011771号
浙公网安备 33010602011771号