
力扣609(java&python)-在系统中查找重复文件(中等)
给你一个目录信息列表 paths ,包括目录路径,以及该目录中的所有文件及其内容,请你按路径返回文件系统中的所有重复文件。答案可按 任意顺序 返回。
一组重复的文件至少包括 两个 具有完全相同内容的文件。
输入 列表中的单个目录信息字符串的格式如下:
"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"
这意味着,在目录 root/d1/d2/.../dm 下,有 n 个文件 ( f1.txt, f2.txt ... fn.txt ) 的内容分别是 ( f1_content, f2_content ... fn_content ) 。注意:n >= 1 且 m >= 0 。如果 m = 0 ,则表示该目录是根目录。
输出 是由 重复文件路径组 构成的列表。其中每个组由所有具有相同内容文件的文件路径组成。文件路径是具有下列格式的字符串:
"directory_path/file_name.txt"
示例 1:
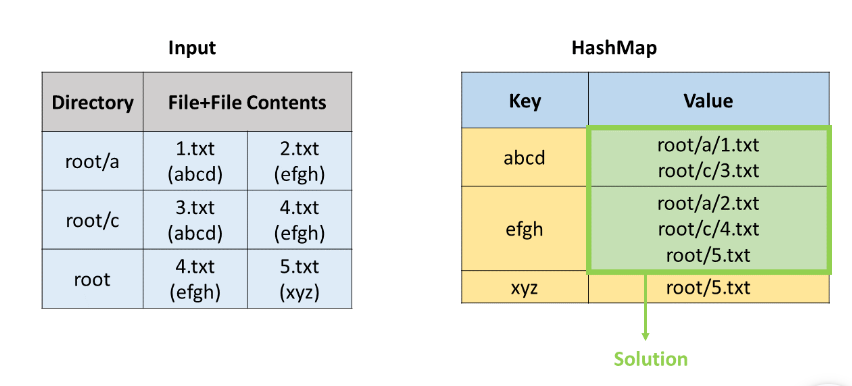
输入:paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)","root 4.txt(efgh)"]
输出:[["root/a/2.txt","root/c/d/4.txt","root/4.txt"],["root/a/1.txt","root/c/3.txt"]]
示例 2:
输入:paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)"]
输出:[["root/a/2.txt","root/c/d/4.txt"],["root/a/1.txt","root/c/3.txt"]]
提示:
1 <= paths.length <= 2 * 104
1 <= paths[i].length <= 3000
1 <= sum(paths[i].length) <= 5 * 105
paths[i] 由英文字母、数字、字符 '/'、'.'、'('、')' 和 ' ' 组成
你可以假设在同一目录中没有任何文件或目录共享相同的名称。
你可以假设每个给定的目录信息代表一个唯一的目录。目录路径和文件信息用单个空格分隔。
进阶:
假设您有一个真正的文件系统,您将如何搜索文件?广度搜索还是宽度搜索?
如果文件内容非常大(GB级别),您将如何修改您的解决方案?
如果每次只能读取 1 kb 的文件,您将如何修改解决方案?
修改后的解决方案的时间复杂度是多少?其中最耗时的部分和消耗内存的部分是什么?如何优化?
如何确保您发现的重复文件不是误报?
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/find-duplicate-file-in-system
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解题思路:
哈希表:先将paths中的目录路径、文件名和文件内容分开,再创建一个哈希表以key-内容,value-文件目录和文件名形式来存储。然后就开始遍历每一个文件,并把它加入哈希映射中。遍历结束后,再遍历哈希映射,如果一个键对应的值列表的长度大于 1,说明我们找到了重复文件,可以把这个列表加入到答案中。
java代码:
1 class Solution { 2 public List<List<String>> findDuplicate(String[] paths) { 3 //存放结果 4 List < List <String>> res = new ArrayList<>(); 5 //key-文件内容, value-路径和文件名 6 Map<String, List<String>> map = new HashMap<>(); 7 for(String path : paths){ 8 //以空格为分割符分割出路径和文件 9 String[] pa = path.split(" "); 10 for(int i = 1; i < pa.length; i++){ 11 //以左括号为分隔符分出内容 12 String[] name_content = pa[i].split("\\("); 13 //将文件名和内容分开 14 name_content[1] = name_content[1].replace(")", ""); 15 //获取当前map的value,没有的话要新建 16 List<String> list = map.getOrDefault(name_content[1], new ArrayList<String>()); 17 //将路径和文件名存入list 18 list.add(pa[0] + "/" + name_content[0]); 19 //把当前的路径和文件内容放入map中 20 map.put(name_content[1], list); 21 } 22 } 23 //遍历map中的key,如果value长度大于1,则说明有重复 24 for(String key : map.keySet()){ 25 if(map.get(key).size() > 1){ 26 res.add(map.get(key)); 27 } 28 29 } 30 return res; 31 } 32 }
python3代码:
1 class Solution: 2 def findDuplicate(self, paths: List[str]) -> List[List[str]]: 3 map = {} 4 res = [] 5 for path in paths: 6 # 以空格分割 7 pa = path.split(" ") 8 for i in range(1,len(pa)): 9 name_content = pa[i].split("(") 10 name_content[1] = name_content[1].replace(")","") 11 # 拼接出目录和文件名 12 list = pa[0] + "/" + name_content[0] 13 # 如果当前内容存在map中,则加入路径 14 if name_content[1] in map: 15 map[name_content[1]].append(list) 16 else: 17 map[name_content[1]] = [list] 18 for key in map.keys(): 19 if len(map[key]) > 1: 20 res.append(map[key]) 21 return res

 浙公网安备 33010602011771号
浙公网安备 33010602011771号