
KMP算法
Knuth-Morris-Pratt子字符串查找算法
这个算法还是在之前课程学习严蔚敏老师的《数据结构》这本书见过的,后续做题看到这个解法,又不知道原理了,这里记录一下自己理解的部分,如果有不对的地方,欢迎各位老师批评指正!
1.作用
KMP算法的主要使用在字符串的匹配上,即在一个已知字符串中查找子串的位置,也叫做串的模式匹配。例如:比如主串s=“aabaabaaf”,子串t=“aabaaf”。需要找到子串t 在主串s 中的位置。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个getnext()函数来得到子串的最长公共前缀与后缀的长度的next数组,且这个next数组的数值只与子串有关!
next数组的含义:代表当前字符之前的字符串中,有多长的相同前缀后缀。例如next[i] = k,代表 i 之前的字符串中有最大长度为k的相同前缀后缀。
2.前缀表和后缀表
例如:“ababb”
前缀表:不包含最后一个字母: "a", "ab", "aba", "abab"
后缀表:不包含第一个字母:"b", "bb", "abb", "babb"
3.最长公共前后缀
对于P= p0p1...pj-1pj,寻找模式串P中长度最大且相等的前缀和后缀。如存在p0p1...pk-1pk = pj-kpj-k+1...pj-1pj,那么在包含pj的模式串中有最大长度为K+1的相同前缀后缀。
例如:字符串“aabaaf”,求出最长公共前后缀数组为 [0,1,0,1,2,0]
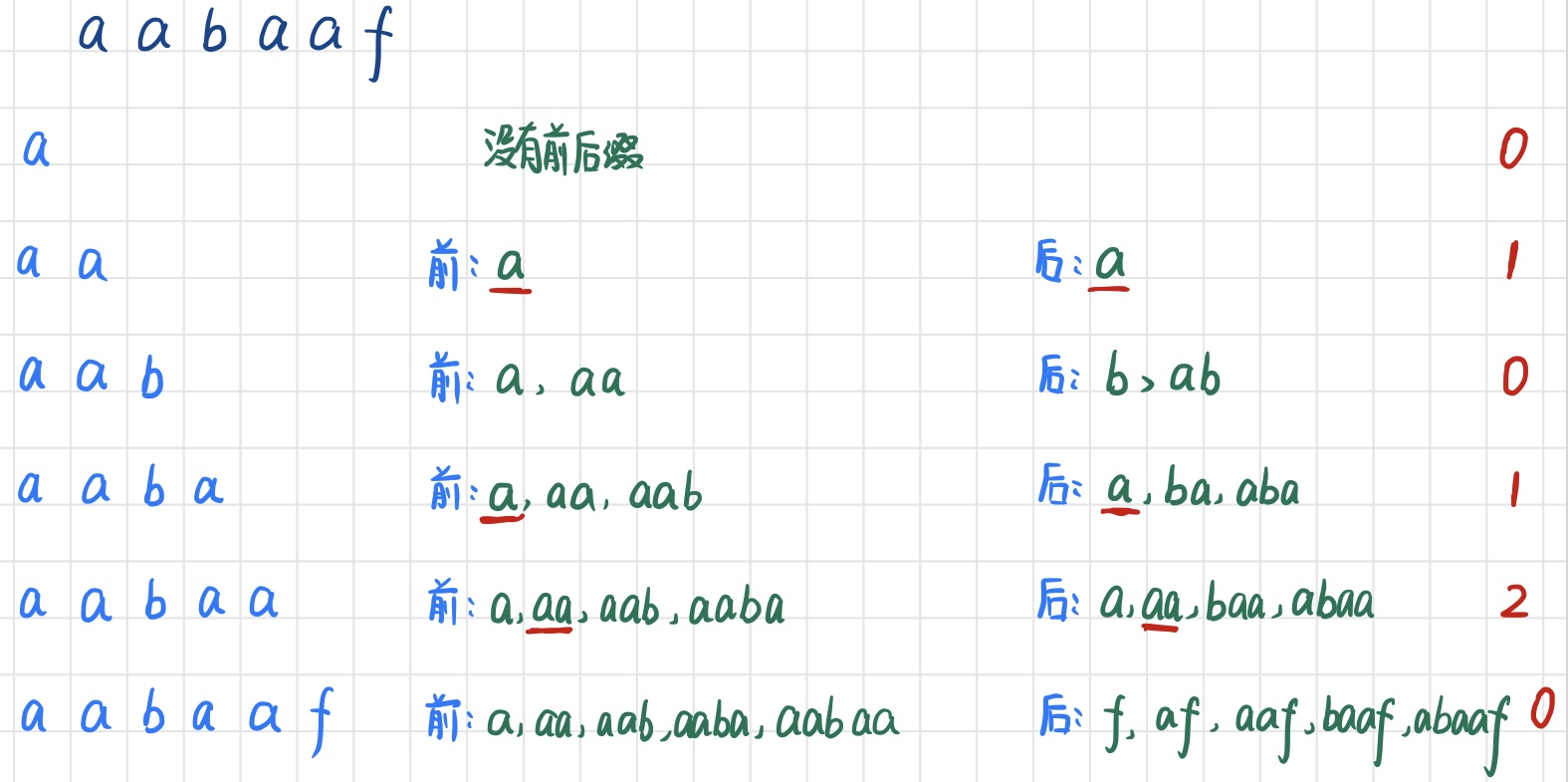
解释:对于字符串aabaa来说,有长度相同的前缀后缀aa。(k+1 = 2, k = 1)
4.最长公共前后缀表转next数组:(三种写法)
求next的公式:

看了各种博客,发现根据最长公共前后缀求next数组一共有以下三种方式:

这里详细介绍第二种:
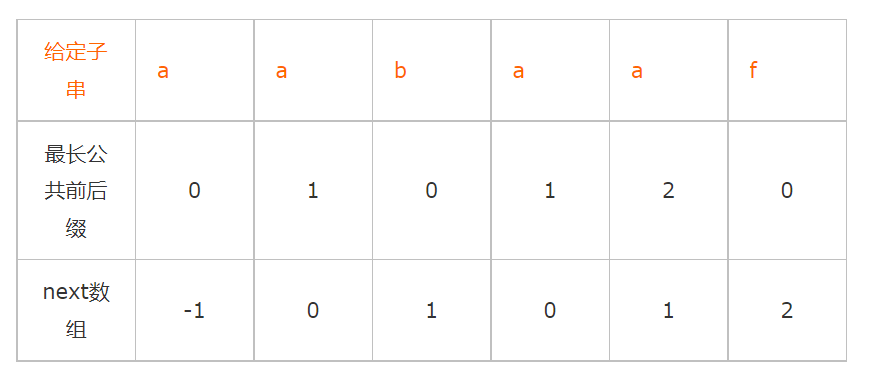
next数组考虑的是除当前字符外的最长的相同前缀后缀。通过求出的最长公共前后缀数组,经过变形:将数组整体向右移一位,然后初值设为 -1。例如上面第二种:[-1,0,1,0,1,2]
解释:对于aaba来说,第4个a字符之前的字符串(aab)就没有相同的前缀后缀,故第4个字符对应的next值就为0;对于aabaa来说,第5个a字符之前的字符串(aaba)相同的前缀后缀为a,故第5个字符对应的next值就为1;对于aabaaf来说,第6个f 字符之前的字符串(aabaa)相同的前缀后缀为aa,故第6个字符对应的next值就为2。
则给定的子串为:aabaaf,它的最大长度及next数组如下表所示:
还可以根据:已知的next [0, ..., j],求出next [j + 1],这里介绍一下任课老师教的求解方法,核心就是:始终判断前一个字符与它next值所对应的字符是否相同,一直向前判断,这么说很抽象,看下面的例子。
字符串T = “aabaaf”
第一步:初始值 next[0] = -1,其实next[1]也可以直接设为0
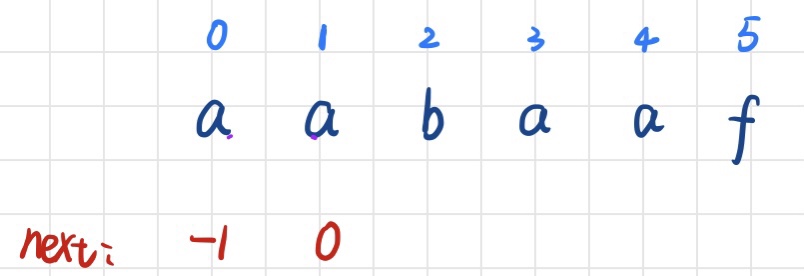
第二步:现在求的是 i= 2 时的next[2],就去看它的前一位 i= 1对应的字符a的next值所对应的字符是否一致,这时T[1] 与T[next[1]]相同,则直接在b的前一位的next值上加1就是当前next[2] = 0 + 1 = 1
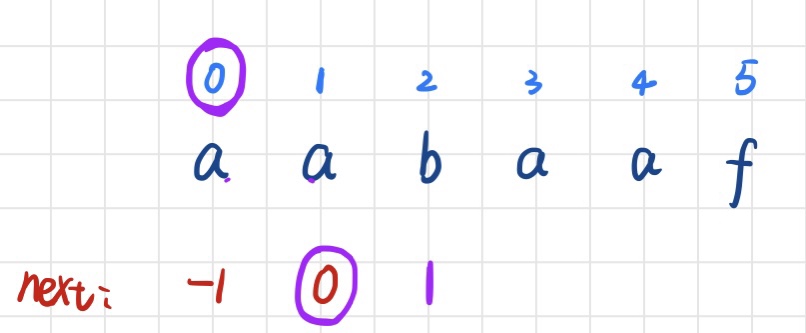
第三步:现在求的是 i=3 时的next[3],首先看 i=2所对应的next值为1,就去看位置1上的字符是否与b一致,显然a与b不一致,再继续看a对应的next值为0,继续判断b是否与0所对应的字符a一致,不一致,这时候已经判断到字符串最开始了,没法继续向前了,表示没找到,则当前next[3] = 0
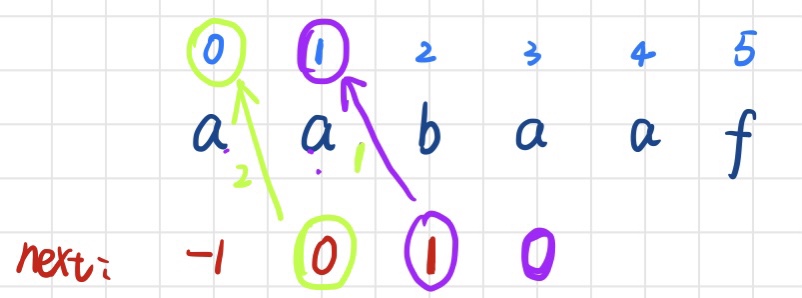
第四步:现在求的是 i=4 时的next[4],首先看 i=3所对应的next值为0,就去看位置0所对应的字符为a,,则这时T[3] 与T[next[3]]相同,则直接在a的前一位的next值上加1就是当前next[4] = 0 + 1 = 1
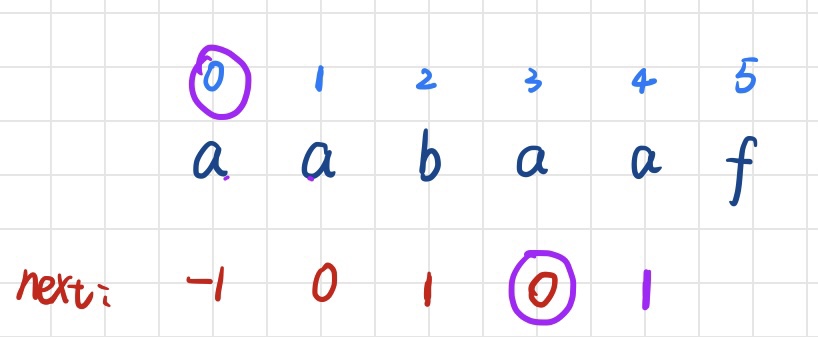
第五步:现在求的是 i=5 时的next[5],首先看 i=4所对应的next值为1,就去看位置1所对应的字符为a,,则这时T[4] 与T[next[4]]相同,则直接在 f 的前一位的next值上加1就是当前next[5] = 1 + 1 = 2
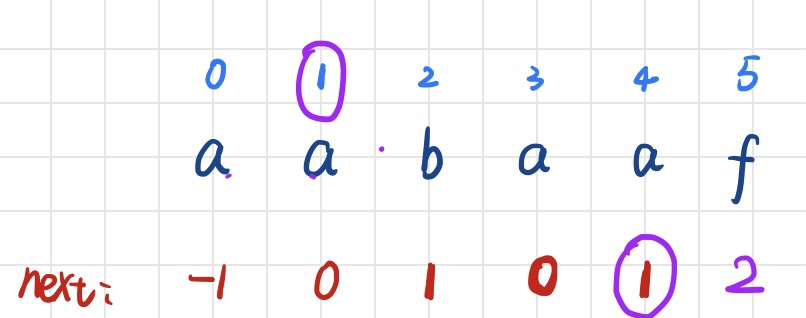
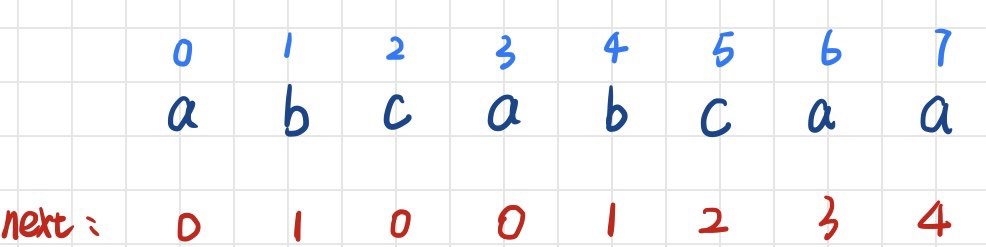
练习:试试手看:T= "abcabcaa" 求它的next数组?
实现代码:
1 public static int[] getNext(String t) { 2 int[] next = new int[t.length()]; 3 int i = 0; 4 int j = -1; 5 next[0] = -1; 6 while(i < t.length() - 1) { 7 if(j == -1 || t.charAt(i) == t.charAt(j)) { 8 i++; 9 j++; 10 next[i] = j; 11 }else { 12 j = next[j]; 13 } 14 } 15 return next; 16 } 17
这个是next为原样的代码(来自代码随想录):
1 void getNext(string s, int[] next){ 2 //初始化 3 int j = 0; 4 next[0] = 0; 5 for(int i = 1; i < s.length(); i++){ 6 //前后缀不相同的情况 7 while(j >0 && s.charAt(i) != s.charAt(j)){ 8 j = next[j-1]; 9 } 10 //前后缀相同的情况 11 if(s.charAt(i) == s.charAt(j)){ 12 j++; 13 } 14 //更新next数组 15 next[i] = j; 16 }
5.KMP的算法流程
假设主串S匹配到位置 i ,子串T匹配到位置 j
- 如果j = -1 或者 当前字符匹配成功(S[i] == T[j]),则令 i++, j++,继续匹配下一个字符;
- 如果j != -1 且当前字符匹配失败(S[i] != T[j]),则令i 不变,j = next[j]。即当匹配失败时,子串T向右移动的位数为:失配字符所在的位置 - 失配字符所对应的next的值(移动的实际位数 = j - next[j] 或者移动的位数 = 已匹配的字符数 - 不匹配字符对应的next值)
举个例子:
主串 S = “BBC ABCDAB ABCDABCDABDE”,子串 T = “ABCDABD”,匹配过程如下:
先求出子串的next数组:
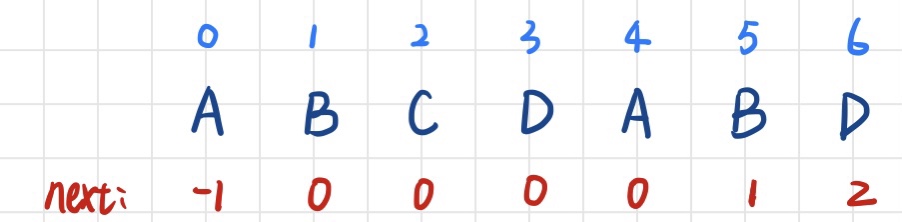
1.S[i] != T[j],B与A失配,移动位数 = 0 - (-1) = 1;

2.S[i] != T[j],B与A失配,移动位数 = 1 - 0 = 1;

3.继续上面的操作,一直到这里,S[i] == T[j],B与B匹配,i++, j++;

4.直到再次不匹配,S[i] != T[j],D与空格不匹配,移动位数 = j - next[j] = 6-2=已匹配的字符数 - 不匹配字符对应的next值=6-2 =4,所以移动4步;

5.向右移动4步后,S[10]跟T[2]继续匹配,S[i] != T[j],C与空格不匹配,移动位数 = j - next[j] = 2-0=已匹配的字符数 - 不匹配字符对应的next值=2-0 =2,向右移动2步;

6.A与空格失配,移动位数 = j - next[j] = 0-(-1)=1,向右移动1 位;

7.继续比较,D与C 失配,故向右移动的位数 = j - next[j] = 6-2=4;

8.经过上一步移动后,发现全部匹配成功了。

KMP代码:
1 int KmpSearch(String s, String t) 2 { 3 int i = 0; 4 int j = 0; 5 int sLen = s.length(); 6 int tLen = t.length(); 7 while (i < sLen && j < tLen) 8 { 9 //①如果j = -1,或者当前字符匹配成功(即S[i] == T[j]),都令i++,j++ 10 if (j == -1 || s[i] == t[j]) 11 { 12 i++; 13 j++; 14 } 15 else 16 { 17 //②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j] 18 //next[j]即为j所对应的next值 19 j = next[j]; 20 } 21 } 22 if (j == tLen) 23 return i - j; 24 else 25 return -1; 26 }
6.KMP算法的时间复杂度O(m+n):
如果某个字符匹配成功,主串的首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变(即 i 不回溯),子串会跳过匹配过的next [j]个字符。整个算法最坏的情况是,当模式串首字符位于i - j的位置时才匹配成功,算法结束。对于长度为m的主串和长度为n的子串,求next数组的时间复杂度为O(n),匹配过程的时间复杂度为O(m),KMP的整体时间复杂度为O(m + n)。
参考:@【v_JULY_v】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号