
haystack全文搜索框架
简介
Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),
该框架支持Solr,Elasticsearch,Whoosh, **Xapian搜索引擎它是一个可插拔的后端(很像Django的数据库层),所以几乎你所有写的代码都可以在不同搜索引擎之间便捷切换 # 特点
全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理
# 搜索引擎 haystack:django的一个包,可以方便地对model里面的内容进行索引、搜索,设计为支持whoosh,solr,Xapian,Elasticsearc四种全文检 索引擎后端,属于一种全文检索的框架 whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,程序不会莫名其妙的崩溃, 对于小型的站点,whoosh已经足够使用
# 分词 jieba:一款免费的中文分词包,如果觉得不好用可以使用一些收费产品
安装
pip install django-haystack
pip install whoosh
pip install jieba
修改配置信息
修改settings.py文件
# 注册 haystack
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'app01.apps.App01Config',
# 注册 haystack 'haystack' ]
# 配置搜索引擎,不同索引引擎,配置不同添加一个设置来指示站点配置文件正在使用的后端,以及其它的后端设置
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine', # 设置搜索引擎为 Whoosh
'PATH': os.path.join(os.path.dirname(__file__), 'whoosh_index'), # 设置path到你的Whoosh的索引的文件系统位置
},
}
# 自动更新索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
Solr 搜索引擎
HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.solr_backend.SolrEngine', 'URL': 'http://127.0.0.1:8983/solr' # ...or for multicore... # 'URL': 'http://127.0.0.1:8983/solr/mysite', }, }
Elasticsearch 搜索引擎
HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine', 'URL': 'http://127.0.0.1:9200/', 'INDEX_NAME': 'haystack', }, }
Whoosh 搜索引擎
#需要设置PATH到你的Whoosh索引的文件系统位置 import os HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine', 'PATH': os.path.join(os.path.dirname(__file__), 'whoosh_index'), }, } # 自动更新索引 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
Xapian 搜索引擎
#首先安装Xapian后端(http://github.com/notanumber/xapian-haystack/tree/master) #需要设置PATH到你的Xapian索引的文件系统位置。 import os HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'xapian_backend.XapianEngine', 'PATH': os.path.join(os.path.dirname(__file__), 'xapian_index'), }, }
对app做索引(设置对哪些表做索引)
针对某个app例如 app01做全文检索,则必须在app01的目录下面建立 search_indexes.py 文件,文件名不能修改
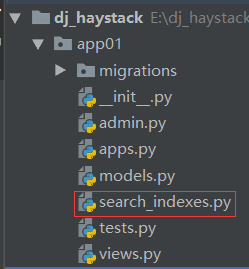
# 相当于给article表做索引
from haystack import indexes
from app01.models import Article
# 类名必须是:表模型Index
class ArticleIndex(indexes.SearchIndex, indexes.Indexable):
# 类名必须为需要检索的Model_name+Index,这里需要检索Article,所以创建ArticleIndex
text = indexes.CharField(document=True, use_template=True) # 创建一个text字段
# 其它字段
# desc = indexes.CharField(model_attr='desc')
# content = indexes.CharField(model_attr='content')
def get_model(self): # 重载get_model方法,必须要有!
return Article # 不同表,注意修改
def index_queryset(self, using=None):
return self.get_model().objects.all()
# 注意:
# 如果使用一个字段设置了document=True,则一般约定此字段名为text,这是在ArticleIndex类里面一贯的命名,以防止后台混乱,当然名字你也可以随便改,不过不建议改。
# use_template=True 这允许我们使用一个数据模板(而不是容易出错的级联)来构建文档搜索引擎索引
设置检索字段
在目录“templates/search/indexes/应用名称/”下创建“模型类名称_text.txt”文件
在templates文件夹下创建search,search文件夹下创建indexes,indexes文件夹下创建 "表名_text.txt" 文件 (检索哪些表,就创建几个文件)
# 这里检索三个字段,需要检索几个字段就写几个字段
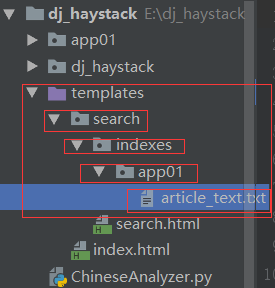
{{ object.title }}
{{ object.desc }}
{{ object.content }}
配置检索路由
from django.conf.urls import url, include from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^test/', views.test), url(r'^search/', include('haystack.urls')) # 全文检索的路由 ]
配置搜索模板
搜索模板默认建在 search文件夹里面,创建一个search.html的文件
<!DOCTYPE html> <html> <head> <title></title> <style> span.highlighted { color: red; } </style> </head> <body> {% load highlight %} {% if query %} <h3>搜索结果如下:</h3> {% for result in page.object_list %} {# 表示返回所有数据 #} {# <a href="{{ result.object.id }}/">{{ result.object.name }}</a><br/>#} <a href="/{{ result.object.id }}/">{% highlight result.object.name with query max_length 2%}</a><br/> {# <p>{{ result.object.content|safe }}</p>#} <p>{% highlight result.object.content with query max_length 100%}</p> {% empty %} <p>啥也没找到</p> {% endfor %} {% if page.has_previous or page.has_next %} <div> {% if page.has_previous %} <a href="?q={{ query }}&page={{ page.previous_page_number }}">{% endif %}« 上一页 {% if page.has_previous %}</a>{% endif %} | {% if page.has_next %}<a href="?q={{ query }}&page={{ page.next_page_number }}">{% endif %}下一页 » {% if page.has_next %}</a>{% endif %} </div> {% endif %} {% endif %} </body> </html>
注意配置好以后,重建索引
你会得到有多少模型进行了处理并放进索引的统计
执行命令:python3 manage.py rebuild_index
使用jieba分词
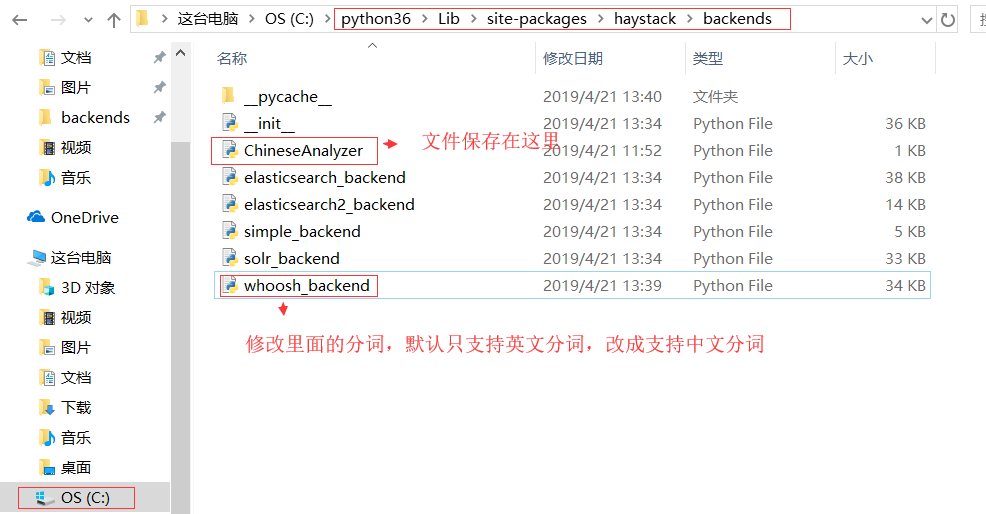
django项目根路径下创建 ChineseAnalyzer.py 文件
建好将其保存 安装haystack的路径下
import jieba from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer): def __call__(self, value, positions=False, chars=False, keeporiginal=False, removestops=True, start_pos=0, start_char=0, mode='', **kwargs): t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs) seglist = jieba.cut(value, cut_all=True) for w in seglist: t.original = t.text = w t.boost = 1.0 if positions: t.pos = start_pos + value.find(w) if chars: t.startchar = start_char + value.find(w) t.endchar = start_char + value.find(w) + len(w) yield t def ChineseAnalyzer(): return ChineseTokenizer()
修改配置whoosh_backend文件,改成可以中文分词
#注意:复制出来的文件名,末尾会有一个空格,记得要删除这个空格 from .ChineseAnalyzer import ChineseAnalyzer 将 analyzer=StemmingAnalyzer() 改为 analyzer=ChineseAnalyzer()
创建搜索栏
跟全文搜索的路由连接
<form method='get' action="/search/" target="_blank"> <input type="text" name="q"> <input type="submit" value="查询"> </form>
其他配置
增加其他变量
from haystack.views import SearchView from .models import * class MySeachView(SearchView): def extra_context(self): # 重载extra_context来添加额外的context内容 context = super(MySeachView,self).extra_context() # 调用父类的extra_context的方法,得到一个字典 side_list = Topic.objects.filter(kind='major').order_by('add_date')[:8] context['side_list'] = side_list # 往字典里添加值 return context # 返回字典 #路由修改 url(r'^search/', search_views.MySeachView(), name='haystack_search'), # 路由改成从自己方法这进入父类
高亮显示
{% highlight result.summary with query %}
# 这里可以限制最终{{ result.summary }}被高亮处理后的长度
{% highlight result.summary with query max_length 40 %}
#html中
<style>
span.highlighted {
color: red;
}
</style>
