(Sqlserver)sql求连续问题
题目一:
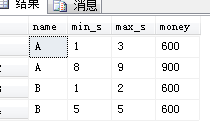
create table etltable( name varchar(20) , seq int, money int); create table etltarget ( name varchar(20), min_s int, max_s int, sum_money int); insert into etltable values ('A',1,100), ('A',2,200), ('A',3,300), ('A',8,400), ('A',9,500), ('B',1,100), ('B',2,500), ('B',5,600); 目标表结果应该是这样 A 1 3 600 A 8 9 900 B 1 2 600 B 5 5 600 解答: select name, min(seq) as min_s, max(seq) as max_s, sum(money) as money from ( select *, seq-row_number() over (partition by name order by name) as rn2--连续的差值会相同 from etltable ) a group by name,rn2--连续的差值相同,按照这个分组即可 order by name
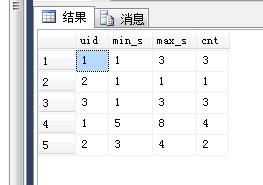
题目二: with aa as ( select 1 uid, '2015-6-1 8:20:00' as login_time union all select 1 uid, '2015-6-2 7:20:05' as login_time union all select 1 uid, '2015-6-3 21:20:30' as login_time union all select 2 uid, '2015-6-1 8:10:00' as login_time union all select 2 uid, '2015-6-3 8:20:00' as login_time union all select 2 uid, '2015-6-4 18:20:00' as login_time union all select 1 uid, '2015-6-5 9:20:00' as login_time union all select 1 uid, '2015-6-6 16:20:00' as login_time union all select 3 uid, '2015-6-1 8:20:00' as login_time union all select 1 uid, '2015-6-7 12:20:00' as login_time union all select 1 uid, '2015-6-8 23:20:00' as login_time union all select 3 uid, '2015-6-2 8:20:00' as login_time union all select 3 uid, '2015-6-3 2:20:00' as login_time ) select uid,min(ds) as min_s,max(ds) as max_s,sum(1) cnt from ( select * , day(login_time) ds, day(login_time)-row_number() over (partition by uid order by login_time) as rn from aa ) a group by uid,rn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号