消息队列专题《二》——消息幂等
《一》MQ的消息幂等原理讲解
1.1.MQ核心框架
无论是消费者,还是生产者,都是消息队列的客户端。至于持久化,实际操作中一般就是数据库(不排除文件存储),总之要能使数据落盘,便于后续问题排查。
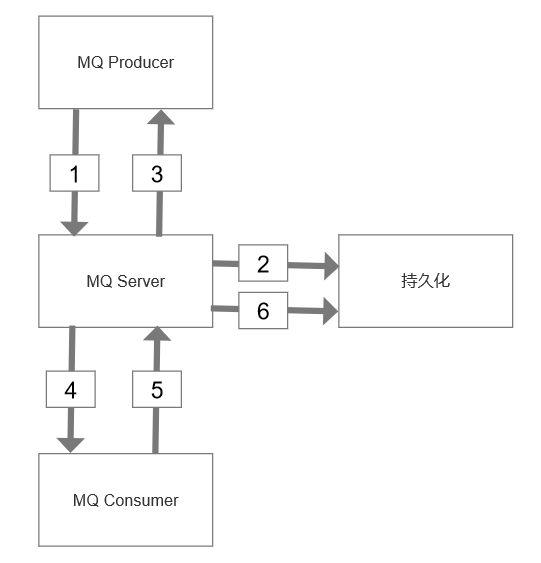
MQ核心架构,它由生产者、服务端、持久化存储、消费者四大部分组成。
MQ如何保证消息必达?MQ消息必达,架构上有两个核心设计点:
(1)消息落地——无论是消息队列还是缓存等模块,都没有数据库靠谱。
(2)消息超时、重传、确认——其实就是应答模式
MQ消息重传,是否可能导致重复的消息?
必须有可能。学过计算机网络的小朋友知道吧
为保证消息的可达性,超时、重传、确认机制可能导致MQ、或者业务方收到重复的消息,从而对业务产生影响。
参考业务场景:
购买会员卡,上游支付系统负责给用户扣款,下游系统负责给用户发卡,通过MQ异步通知。
不管是上半场的ACK丢失,导致MQ收到重复的消息,还是下半场ACK丢失,导致购卡系统收到重复的购卡通知,都可能出现,上游扣了一次钱,下游发了多张卡。
为了避免对业务的影响,MQ如何保证幂等性?
MQ的幂等性,由两部分构成:
(1)MQ发送端,到MQ-server的幂等性(上半场);
(2)MQ-server,到MQ接收端的幂等性(下半场); 
1.2.MQ消息发送上半场
即上图中的步骤1-3:
(1)发送端MQ-client将消息发给服务端MQ-server;
(2)服务端MQ-server将消息落地;
(3)服务端MQ-server回ACK给发送端MQ-client;
如果3丢失,发送端MQ-client超时后会重发消息,可能导致服务端MQ-server收到重复消息。
此时重发是MQ-client发起的,消息的处理是MQ-server,为了避免步骤2落地重复的消息,对每条消息,MQ系统内部必须生成一个inner-msg-id,作为去重和幂等的依据,这个内部消息ID的特性是:
(1)全局唯一,inner-msg-id是发送方客户端生成的,是mq中间件内部自行搞定;
(2)MQ生成,具备业务无关性,对消息发送方和消息接收方屏蔽;
有了这个inner-msg-id,就能保证上半场重发,也只有1条消息落到MQ-server的DB中,实现上半场幂等。
1.3.MQ消息发送下半场
即上图中的步骤4-6:
(1)服务端MQ-server将消息发给接收端MQ-client;
(2)接收端MQ-client回ACK给服务端;
(3)服务端MQ-server将落地消息删除;
需要强调的是,接收端MQ-client回ACK给服务端MQ-server,是消息消费业务方的主动调用行为,不能由MQ-client自动发起,因为MQ系统不知道消费方什么时候真正消费成功。如果5丢失,服务端MQ-server超时后会重发消息,可能导致MQ-client收到重复的消息。
此时重发是MQ-server发起的,消息的处理是消息消费业务方,消息重发势必导致业务方重复消费(上例中的一次付款,重复发卡),为了保证业务幂等性,业务消息体中,必须有一个biz-id,作为去重和幂等的依据,这个业务ID的特性是:
(1)对于同一个业务场景,全局唯一;
(2)由业务消息发送方生成,业务相关,对MQ透明;
(3)由业务消息消费方负责判重,以保证幂等;
最常见的业务ID有:支付ID,订单ID,帖子ID等。 具体到支付购卡场景,发送方必须将支付ID放到消息体中,消费方必须对同一个支付ID进行判重,保证购卡的幂等。
有了这个业务ID,才能够保证下半场消息消费业务方即使收到重复消息,也只有1条消息被消费,保证了幂等。
1.4.总结
首先,上半场幂等。
MQ-client生成inner-msg-id,保证上半场幂等。这个ID全局唯一,业务无关,由MQ保证。
然后,下半场幂等。
业务发送方带入biz-id,业务接收方去重保证幂等。这个ID对单业务唯一,业务相关,对MQ透明。
因此,幂等性,不仅对MQ有要求,对业务上下游也有要求。
备注:上半场的inner-msg-id能不能由业务方在客户端里面生成呢?MQ不解析消息体,不理解消息体的内容
《二》kafka样例
本着“送佛送到西救人救到底”的优良传统,我来以Kafka为例讲解一下消息幂等的具体实践
概念普及
下面我们来简单了解一下消息传递语义,以及kafka的消息传递机制。
首先我们要了解的是message delivery semantic 也就是消息传递语义。
这是一个通用的概念,也就是消息传递过程中消息传递的保证性。
分为三种:
最多一次(at most once): 消息可能丢失也可能被处理,但最多只会被处理一次。
可能丢失 不会重复
至少一次(at least once): 消息不会丢失,但可能被处理多次。
可能重复 不会丢失
精确传递一次(exactly once): 消息被处理且只会被处理一次。
不丢失 不重复 就一次
而kafka其实有两次消息传递,一次生产者发送消息给kafka,一次消费者去kafka消费消息。
两次传递都会影响最终结果,
两次都是精确一次,最终结果才是精确一次。
两次中有一次会丢失消息,或者有一次会重复,那么最终的结果就是可能丢失或者重复的。
2.1.Produce端消息传递


Properties properties = new Properties(); properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092"); properties.put("acks", "all"); properties.put("retries", 0); properties.put("batch.size", 16384); properties.put("linger.ms", 1); properties.put("buffer.memory", 33554432); properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties); for (int i = 1; i <= 600; i++) { kafkaProducer.send(new ProducerRecord<String, String>("z_test_20190430", "testkafka0613"+i)); System.out.println("testkafka"+i); } kafkaProducer.close();
其中指定了一个参数acks 可以有三个值选择:
0: producer完全不管broker的处理结果,回调也就没有用了,并不能保证消息成功发送,但是这种吞吐量最高
-1或者all: leader broker会等消息写入 并且ISR都写入后 才会响应,这种只要ISR有副本存活就肯定不会丢失,但吞吐量最低。
1: 默认的值 leader broker自己写入后就响应,不会等待ISR其他的副本写入,只要leader broker存活就不会丢失,即保证了不丢失,也保证了吞吐量。
所以设置为0时,实现了at most once,而且从这边看只要保证集群稳定的情况下,不设置为0,消息不会丢失。
但是还有一种情况就是消息成功写入,而这个时候由于网络问题producer没有收到写入成功的响应,producer就会开启重试的操作,直到网络恢复,消息就发送了多次。这就是at least once了。
kafka producer 的参数acks 的默认值为1,所以默认的producer级别是at least once。并不能exactly once。
2.2.Consumer端消息传递
consumer是靠offset保证消息传递的。
consumer消费的代码如下:
Properties props = new Properties(); props.put("bootstrap.servers", "kafka01:9092,kafka02:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("auto.offset.reset","earliest"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("foo", "bar")); try{ while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } } }finally{ consumer.close(); }
其中有一个参数是 enable.auto.commit
若设置为true consumer在消费之前提交位移 就实现了at most once
若是消费后提交 就实现了 at least once 默认的配置就是这个。
kafka consumer的参数enable.auto.commit的默认值为true ,所以默认的consumer级别是at least once。也并不能exactly once。
2.3.精确一次
通过了解producer端与consumer端的设置,我们发现kafka在两端的默认配置都是at least once,可能重复,通过配置也不能做到exactly once,好像kafka的消息一定会丢失或者重复的,
是不是没有办法做到exactly once了呢?
确实在kafka 0.11.0.0版本之前producer端确实是不可能的,
但是在kafka 0.11.0.0版本之后,kafka正式推出了idempotent producer。
也就是幂等的producer还有对事务的支持。
kafka 0.11.0.0版本引入了idempotent producer机制,在这个机制中同一消息可能被producer发送多次,但是在broker端只会写入一次,他为每一条消息编号去重,而且对kafka开销影响不大。
参考我的上一篇文章,消息队列专题《一》——削峰填谷,broker里面有一个自己的唯一id。
如何设置开启呢? 需要设置producer端的新参数 enable.idempotent 为true。
而多分区的情况,我们需要保证原子性的写入多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚。
这时候就需要使用事务,在producer端设置 transcational.id为一个指定字符串。
这样幂等producer只能保证单分区上无重复消息;事务可以保证多分区写入消息的完整性。
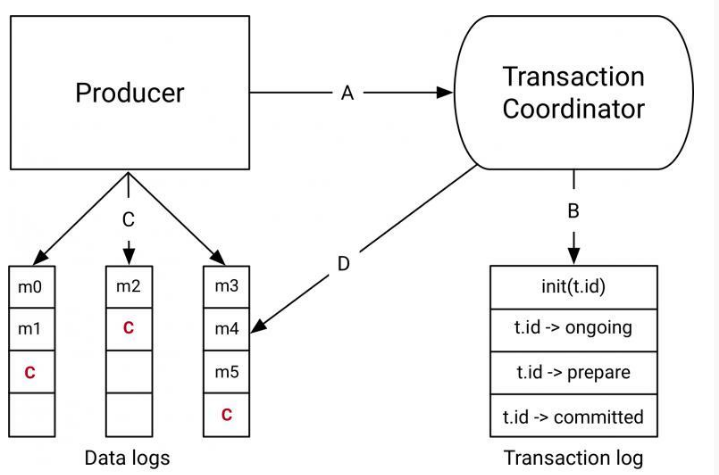
这样producer端实现了exactly once,那么consumer端呢?
consumer端由于可能无法消费事务中所有消息,并且消息可能被删除,所以事务并不能解决consumer端exactly once的问题,我们可能还是需要自己处理这方面的逻辑。比如自己管理offset的提交,不要自动提交,也是可以实现exactly once的。
还有一个选择就是使用kafka自己的流处理引擎,也就是Kafka Streams,
设置processing.guarantee=exactly_once,就可以轻松实现exactly once了。
---------------------------------------------------
作者:杨兮臣
本博客所有文章仅用于学习、研究和交流目的,欢迎非商业性质转载。
博主的文章没有高度、深度和广度,只是凑字数。由于博主的水平不高,不足和错误之处在所难免,希望大家能够批评指出。
博主是利用闲暇时间,把自己毕生所学整理一下,感谢行业的技术大咖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号