Pytorch分布式训练,其他GPU进程占用GPU0的原因
问题
最近跑师兄21年的论文代码,代码里使用了Pytorch分布式训练,在单机8卡的情况下,运行代码,出现如下问题。
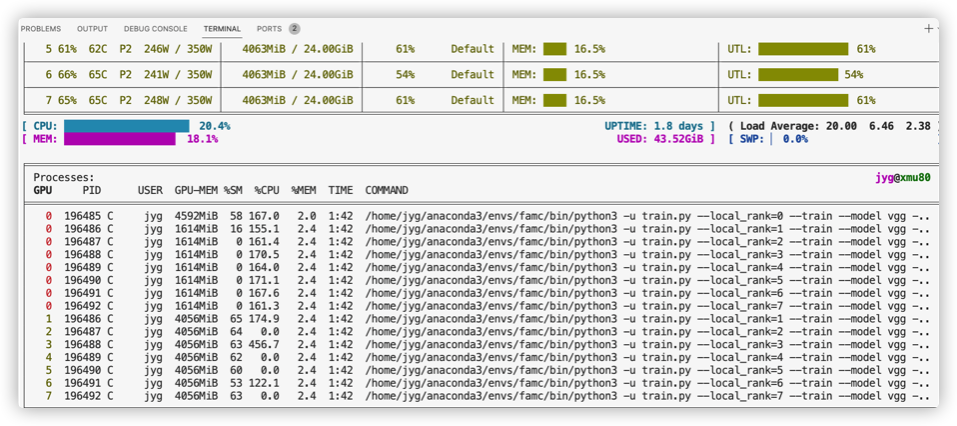
也就是说GPU(1..7)上的进程占用了GPU0,这导致GPU0占的显存太多,以至于我的batchsize不能和原论文保持一致。
解决方法
我一点一点进行debug。
首先,在数据加载部分,由于没有将local_rank和world_size传入get_cifar_iter函数,导致后续使用DALI创建pipeline时使用了默认的local_rank=0,因此会在GPU0上多出该GPU下的进程
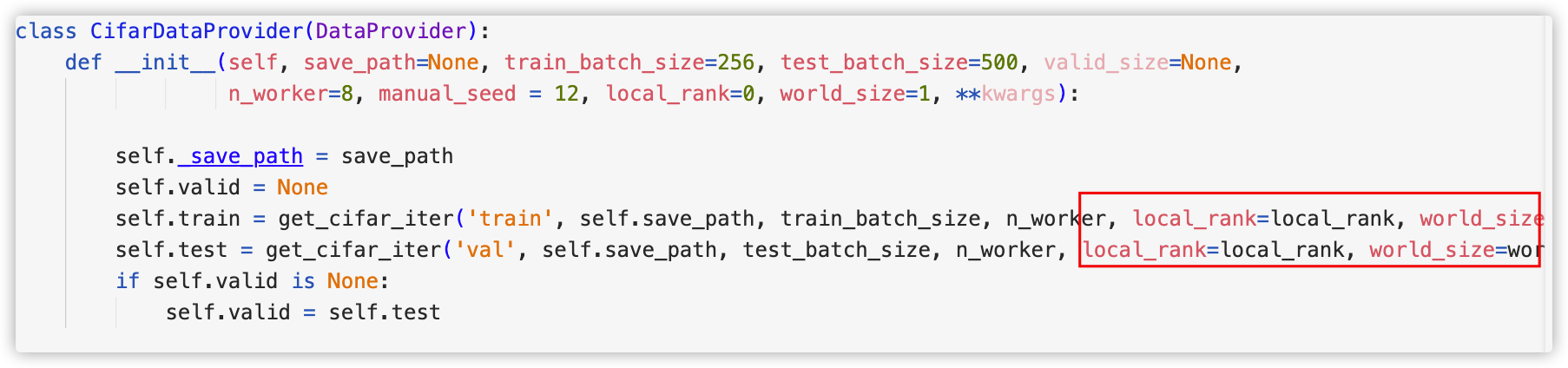
其次,在使用torch.load加载模型权重时,没有设置map_location,于是会默认加载到GPU0上,下图我选择将模型权重加载到cpu。虽然,这会使训练速度变慢,但为了和论文的batchsize保持一致也不得不这样做了。-.-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号