抢占GPU的脚本
前言
同样的,这篇博客也源自于我在做组内2030项目所产生的结果。当时,5个硕士生需要进行类似的微调工作,偶尔还会有博士生使用服务器上的GPU,但服务器上仅有8块GPU。
因此,如何快速抢占到 \(n\) 块GPU,从而高效完成手里的工作,便是一个很重要的问题啦~^ _ ^
问题
我首先在网上看了下现有的抢GPU的脚本,但发现简单的脚本要么只能抢1块GPU,要么是一个复杂项目操作起来较麻烦。
于是便萌生了自己写个Python脚本,这样以后凡是涉及到需要抢GPU的场景,我都可以通过运行该脚本抢占到 \(n\) 块GPU后,便开始我的模型训练或是其他。
这样一种一劳永逸的工作,何乐而不为呢?
闲话少叙,下面开始介绍实现方法。
解决方法
我主要利用Python多进程编程,通过占用GPU内存,从而达到占用GPU的目的。关于代码的解释以及整个完成过程详见我的个人博客,以下主要介绍如何使用该脚本。
我的Python版本为3.11,执行命令如下
python grab_gpu.py --n 3 --otime 30 --spath ./train.sh
其中n表示需要占用的GPU个数,otime表示占用时间,spath表示一旦释放GPU后,我们需要执行的脚本。
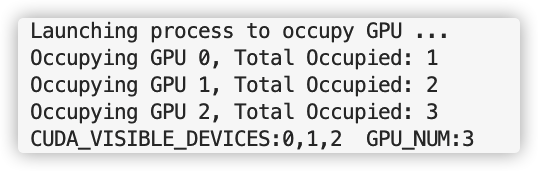
运行结果如下:
完整代码如下
import os
import subprocess
import time
import argparse
from multiprocessing import Process, Value, Lock, Array
def get_gpu_mem(gpu_id):
gpu_query = subprocess.check_output(['nvidia-smi', '--query-gpu=memory.used', '--format=csv,nounits,noheader'])
gpu_memory = [int(x) for x in gpu_query.decode('utf-8').split('\n')[:-1]]
return gpu_memory[gpu_id]
def get_free_gpus()->list:
gpu_query = subprocess.check_output(['nvidia-smi', '--query-gpu=memory.used', '--format=csv,nounits,noheader'])
gpu_memory = [int(x) for x in gpu_query.decode('utf-8').split('\n')[:-1]]
free_gpus = [i for i, mem in enumerate(gpu_memory) if mem < 100]
return free_gpus
def occupy_gpu(gpu_id:int, n, occupy_num, ocpy_gpus, lock, a_dim=140000):
with lock:
if get_gpu_mem(gpu_id) < 100 and occupy_num.value < n:
import torch
a = torch.ones((a_dim,a_dim)).cuda(gpu_id)
ocpy_gpus[occupy_num.value]= gpu_id
occupy_num.value += 1
print(f"Occupying GPU {gpu_id}, Total Occupied: {occupy_num.value}")
while True:
time.sleep(10)
def occupy_all_gpus(n:int, occupy_num, ocpy_gpus, interval=10):
print("Launching process to occupy GPU ...")
lock = Lock()
processes = [] #List to store the processes
while occupy_num.value < n:
free_gpus = get_free_gpus()
will_occupy_num = min(n, max(0,len(free_gpus)))
for i in range(will_occupy_num):
if occupy_num.value < n:
p = Process(target=occupy_gpu, args=(free_gpus[i], n, occupy_num, ocpy_gpus, lock))
p.start()
processes.append(p)
time.sleep(interval) # enough time to occupy gpus and update nvidia-smi
return processes, ocpy_gpus
def run_my_program(n, desired_script, processes, ocpy_gpus, occupy_num):
for p in processes:
p.terminate()
ocpy_gpus_list = list(ocpy_gpus[:occupy_num.value])
cuda_visible_devices = ",".join(map(str, ocpy_gpus_list))
os.environ['CUDA_VISIBLE_DEVICES'] = cuda_visible_devices
subprocess.run([desired_script, str(n)])
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Arguments for Occupy GPUs")
parser.add_argument(
"--n", type=int, default=2, help="Number of GPUs to occupy"
)
parser.add_argument(
"--otime", type=int, default=10, help="Time of occupying gpu"
)
parser.add_argument(
"--spath", type=str, default='./train.sh', help="the execute script path"
)
args = parser.parse_args()
n = args.n
occupy_time = args.otime
desired_script = args.spath
occupy_num = Value('i', 0) # Shared variable to count occupied GPUs
ocpy_gpus = Array('i', [-1 for _ in range(8)])# Shared array to store occupied gpu
processes,ocpy_gpus = occupy_all_gpus(n, occupy_num, ocpy_gpus)
time.sleep(occupy_time)
run_my_program(n, desired_script, processes, ocpy_gpus, occupy_num)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号