
[基础] Loss function(一)
Loss function = Loss term(误差项) + Regularization term(正则项),我们先来研究误差项;首先,所谓误差项,当然是误差的越少越好,由于不存在负误差,所以为0是极限,而误差得越多当然也越不好
1. Gold function,理想中的效果
正样本,损失为0;为负样本,损失为1
2. Hinge function,应用于SVM
线性划分,f = max(0, 1 - m(x))
m(x) > 0,正样本,正得越厉害,损失越少;m(x) < 0,负样本,负得越厉害,损失越多
3. Log function,应用于Logistic regression
看到Log就想到最大似然估计,的确是的。与生成模型不同的是
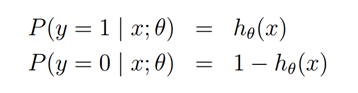
对,是后验概率,有个标签。然后就是经典方程
![]()
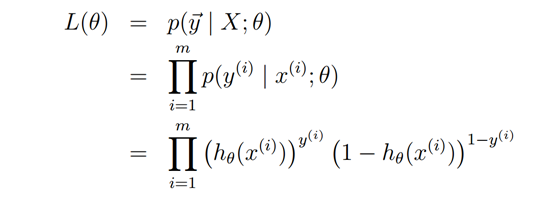
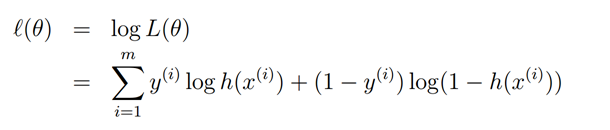
还是挺对称的
4. Squared loss,用于线性回归
l(x) = (m(x) - 1)^2
5. Exponential loss,用于boosting
l(x) = exp(-m(x))
用一个经典图可以看出几种Loss function的优劣了
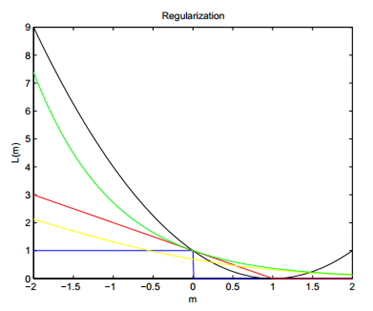
Square Loss有点猎奇...不过用作线性分类应用还是挺好的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号