

图形学之Unity渲染管线流程
Unity中的渲染管线流程
下图是《Unity Shader 入门精要》一书中的渲染流程图;
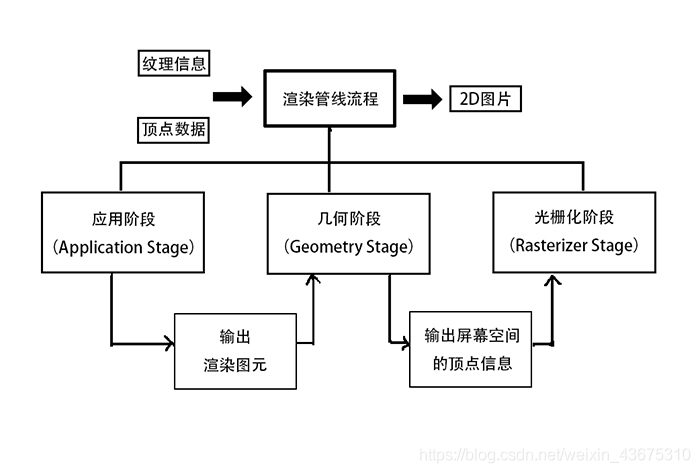
ApplicationStage阶段:准备场景信息(视景体,摄像机参数)、粗粒度剔除、定义每个模型的渲染命令(材质,shader)——由开发者定义,不做讨论;
GemetryStage阶段:顶点着色器、曲面细分着色器、几何着色器、裁剪、屏幕映射;
RasterizerStage阶段:三角形设置遍历,片元着色器、逐片元操作;
每个阶段具体操作如下图(虚线框是可选阶段):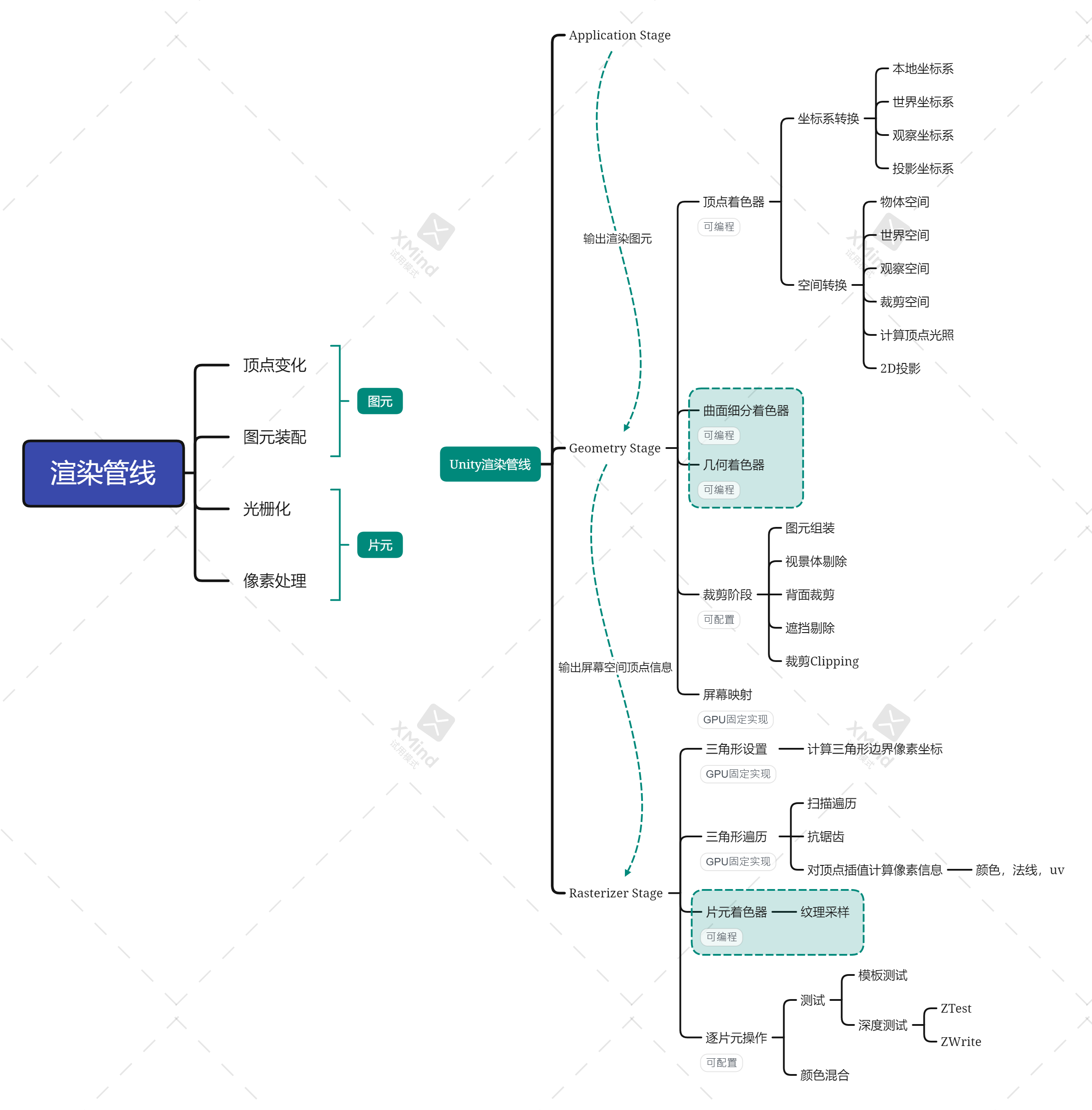
模型空间——矩阵变换——齐次裁剪空间——透视除法——NDC标准设备坐标——屏幕映射
齐次裁剪空间是视景体空间(台体);
CVV:标准视体-也就是NDC坐标系对应的空间;
透视除法:顶点坐标除以w分量,将当前z深度所在的截面缩放为(2,2,2)的截面坐标;所以w分量记录了z深度信息;
硬件做透视除法获得NDC归一化设备坐标——再经过屏幕映射获得屏幕坐标系下顶点坐标;
Unity使用OpenGL的NDC,z分量在[-1,1];
OpenGL和DirectX差异
NDC空间——OpenGL为[-1,1],DirectX为[0,1],深度z范围不同;
窗口坐标系——DirectX左上角原点,OpenGL左下角原点;
投影平面——DirectX投影平面就是视景体近截面,OpenGL有视平面;
左右手坐标系——DirectX左手,OpenGL右手,叉乘顺序;
问题:
为什么片元不叫像素?
片元是很多状态的集合,记录了该像素的屏幕坐标,深度信息,法线,UV等;
DrawCall为什么会影响性能?
DrawCall是CPU向GPU添加渲染命令的过程,过程会由CPU向GPU发送数据(模型信息),DrawCall的次数越多CPU消耗性能就越大,DrawCall次数过多会导致每一帧CPU来不及发送全部数据给GPU渲染;
GPU有一个命令缓存区(Command Buffer),CPU的渲染命令都会存储在这里,GPU从命令缓存区依次执行渲染命令;
两种渲染命令:渲染模型(CPU提交模型信息也就是DrawCall)和改变渲染状态(着色器纹理状态改变,更耗时);
一般情况都是GPU渲染完成等待CPU发渲染命令;
Life is too short for so much sorrow.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了