视频实例分割 | Target-Aware Adaptive Tracking for Unsupervised Video Object Segmentation

本文介绍了一种视频实例分割的无监督学习方法。
paper地址:https://davischallenge.org/challenge2020/papers/DAVIS-Unsupervised-Challenge-2nd-Team.pdf
工作动机
相比于一般的语义分割任务,视频实例分割要更具有挑战性,因为视频中需要将分割出的物体在帧与帧之间联系起来。一般的做法是先用分割网络将实例分割出来,为了实现跨帧联系,可以利用ReID来匹配各个实例。然而这种做法存在以下两个方面的局限性:
- ReID网络只关注物体的总体形象,很少关注物体的细粒度特征,因此鲁棒性不高。
- 需要大量的数据来训练segmentation与ReID两个网络。
本文即提出了一种改进的算法。
模型介绍
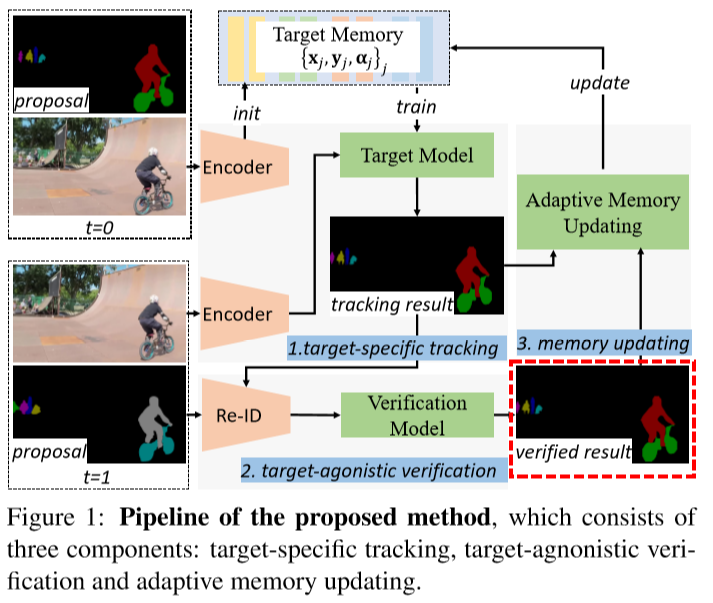
模型主要由4个部分组成:目标特异性跟踪、目标无关的验证、自适应memory更新,以及一个分割网络。
目标特异性跟踪
模型首先建立了一个目标外观特异性的模型,来将目标与背景干扰区分开。模型用了一个两层完全卷积神经网络来实例化这一部分,即D(x; w) = w2 ∗ (w1 ∗ x),其中x为图像的特征,w为网络的参数。给定训练集M,网络可以通过对损失函数L(w; M) = Σj(αj|D(xj; w - yj)|^2) + Σk(λk|wk|^2)进行优化,来进行在线学习。
与半监督学习不同的是,这里没有ground-truth,因此模型很容易出现漂移。为了弥补,模型使用HTC(HTC的参考链接:https://blog.csdn.net/qq_42191914/article/details/105267166)来生成ground-truth,并进行数据增强,来训练初始模型。
目标无关的验证
这一步是为了验证目标yj与追踪轨迹T是否前后一致,同时从proposal集中找到更好的候选目标。首先对于每个目标o,计算其匹配分数:s(o, T) = (cos(o, yj) + cos(o, y0)) * 1(IoU(o, yj) > 0.5),其中cos为两个ReID embedding的cosine相似度,IoU为Intersection over Union,1()为示性函数。在这里,首先需要检查o与yj的重合程度,用来截断ReID的相似部分。为了可靠性,将o与最近和最远的追踪目标进行比较,从而使模型在长期上能够保持一致。
通过这一方法,可以得到匹配分数最高的一个proposal,如果这个匹配分数高于某个阈值,则用其替换掉当前的追踪结果。
除此之外,如果某个物体与所有的追踪目标的相似度都为0,并且IoU小于0.1,则将其标记为一个新的显著性物体。
自适应memory更新
在验证完追踪结果之后,可以获得一个新的样本{xj, yj, αj},首先样本的权重被赋值为αj = α(j-1)/(1-η),其中α0=η。如果匹配分数高于阈值,则再将权重翻倍,让模型更加关注这一个对象,同时更新memory。如果匹配分数不高于阈值,则每8帧更新memory。
分割网络
通过以上网络可以得到一个粗糙的分割结果,因此需要用一个分割网络来得到更精细的分割结果。
实验
使用Resnet-101作为backbone,在DAVIS20与Youtube-VOS上进行训练,th_prop=0.3,th_reid=0.8,结果如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号