


语音识别技术简介
1 自动语音识别简介
语音识别技术,也可以称为自动语音识别(Automatic Speech Recognition,ASR),其任务是把人所发出的语音中词汇内容转换为计算机可读入的文本。语音识别技术是一种综合性的技术,它涉及到多个学科领域,如发声机理和听觉机理、信号处理、概率论和信息论、模式识别以及人工智能等等。
目前,主流的大词汇量语音识别系统中通常采用基于统计模型的识别技术,典型的基于统计模型的语音识别系统通常有如下几个基本组成模块:
-
信号处理及特征提取模块。该模块的主要任务是从输入的语音信号中提取特征,用于声学模型的建模以及解码过程。但在提取特征之前也需要负责对语音信号进行降噪等处理,以提高系统的鲁棒性。
-
统计声学模型。通常的语音识别系统大都使用隐马尔科夫模型对词,音节、音素等基本的声学单元进行建模,生成声学模型。
-
语言模型。语言模型对系统所需识别的语言在单词层面上进行建模。语言模型包括正则语言,上下文无关文法的各种语言模型,但是语言的语法通常很复杂,语法文件中的语法规则会很多,并且需要繁重的人工劳动来完成语法规则的编写,所以但目前大多数语音识别系统普遍采用统计语言模型,其中大都是基于统计的N元语法(N-gram)模型及其变体。
-
发音词典。发音词典包含系统所能处理的单词的集合,并标明了其发音。通过发音词典得到声学模型的建模单元和语言模型建模单元间的映射关系,从而把声学模型和语言模型连接起来,组成一个搜索的状态空间用于解码器进行解码工作。
-
解码器。解码器是语音识别系统的核心之一,该模块负责读取输入的语音信号的特征序列,在由声学模型、语言模型及发音词典生成的状态空间中,解码出以最大概率输出该信号的词串。
以下再具体介绍语音识别中几个主要的模块:声学模型、发音词典、语言模型以及解码器。
1.1 声学模型
声学模型(acoustic model)是自动语音识别系统的模型中最底层的部分,同时也是自动语音识别系统中最关键的组成单元,声学模型建模的好坏会直接从根本上影响语音识别系统的识别效果和鲁棒性。声学模型实验概率统计的模型对带有声学信息的语音基本单元建立模型,描述其统计特性。通过对声学模型的建模,可以较有效地衡量语音的特征矢量序列和每一个发音模板之间的相似度,可以有助于判断该段语音的声学信息,即语音的内容。语者的语音内容都是由一些基本的语音单元组成,这些基本的语音单元可以是句子、词组、词、音节(syllable)、子音节(Sub-syllable)或者音素等。可见可选择建模的语音单元有不少,通常应该根据具体的应用场景来选择建模的语音单元。在小词汇量的语音识别系统当中通常选用单词作为一个语音单元来建立声学模型,但是当词汇量增多时,需要训练和存储大量的语音数据,很容易出现训练数据不充分或者某些建模单元数据的缺失,导致过拟合问题,影响模型的准确性,甚至缺失某些单词的训练数据,无法对其建模。所以后来出现了使用音节或者子音节建立声学模型的方法。由于一种语言中音节或者子音节比较有限,一般情况下不会出现训练数据不充分或者缺失问题。在词汇量较大的语音识别系统中,这种建模方法要比对单词建模的识别率高。
由上述可知,具体建模的语音单元的选择通常由语音识别系统的词汇量大小、训练语音数据的多少以及系统要求的性能等具体因素来定。通常情况下,建模单元的选择应该尽量满足如下两方面的要求,1)鲁棒性:即每一个模型都有充足的样本数来进行模型训练,得到该模型的参数;2)一致性:要求建模单元应该尽可能相对稳定,即在不同的环境下其统计特性变化比较小。鲁棒性和一致性是相互矛盾、不可同时满足的,在具体的应用中需要依照应用需求来对两方面进行权衡。为了保持建模单元的一致性,希望建模单元代表的信息层面更高,如音节的稳定性要比子音节或者音素高。但建模单元增大会造成模型数量增加,在训练语音数据不增加的情况下,会导致模型的鲁棒性降低。但是另一方面,为了提高鲁棒性,总希望更少的模型数目,从而增加每个模型的训练样本数,这需要信息层面更低的建模单元,如音素就比音节代表的信息层面更低,且数量更少。而减小建模单元又会使得它在连续语音中由于上下文的不同而变化增大,从而影响声学模型的稳定性。所以说对于建模单元的选择,需要在具体的应用中依照具体应用需求来权衡,一般来说,对于中小词汇量的语音识别系统,模型数目不多,通常可以满足鲁棒性,所以建模单元可以大一些,比如词或者词组;而对于大词汇量的语音识别系统,通常会选择子音节或者音素作建模单元,可以提高系统的鲁棒性,并采样其它一些技术手段来尽量满足一致性的要求。
在大词汇量连续语音识别(large-vocabulary continuous speech recognition,LVCSR)中,通常会选择音素作为建模单元,而选择音素的建模通常有两种不同的方式,分别是对音素建立上下文无关模型(Context Independent)以及上下文相关模型(Context Dependent)。上下文无关模型是不考虑音素语境的上下文,即具体语句中该音素的前一个以及后一个音素发音对该音素的影响,对每一个基本的音素进行建模。通常使用HMM模型对音素进行建模,但是在连续语音中,由于语境的变化以及上下文发音的影响,建模单元在不同上下文中的统计特性有时会有很大的区别,仅仅使用上下文无关模型会导致建模不够准确,所以为了提高音素模型的准确性,就需要考虑上下文发音对该建模单元的影响,从而产生上下文相关模型的建模方法。上下文相关模型是考虑到不同上下文对音素发音的影响,来对音素进行建模。常用的建模方法有两种,即分别对双音素(biphone)和三音素(triphone)建模。常用的是三音素,三音素是考虑到该音素具体语境中的前一个音素和后一个音素发音的影响来建立模型的。例如单词ZERO的发音是Z IY R OW。其中R的三音素是IY-R-OW。可以看出上下文相关模型的建模数量要比上下文无关模型要多很多。为了确保上下文相关模型训练的准确性和鲁棒性,就需要更大的语音库作为支持。但是一般情况下,语音库很难满足下文相关模型建模的需求。比如说三音素,语音库中的语聊难以覆盖所有三音素的情况,或者对于某些三音素来说会有数据稀疏的问题,若基本音素有50个,则三音素会有50*50*50=125000个,则平均每个状态上的采样就会很少,很可能由于样本稀疏,训练时造成过拟合问题。所以从语音库方面,确保模型训练的准确性和鲁棒性很难实现,需要寻求别的解决办法。
为了解决过拟合问题,可以通过对状态做聚类,绑定同类状态,从而减少训练的总状态数目,避免过拟合问题的发生,提高系统的鲁棒性。Sphinx系统里面使用的是决策树的方法完成的状态绑定。
1.2 语言模型
由于语音信号的时变性、噪声和其它一些不稳定因素,单纯靠声学模型无法达到较高的语音识别的准确率。在人类语言中,每一句话的单词直接有密切的联系,这些单词层面的信息可以减少声学模型上的搜索范围,有效地提高识别的准确性,要完成这项任务语言模型是必不可少的,它提供了语言中词之间的上下文信息以及语义信息。
在早期的语音识别系统中,使用语法规则来得到语言模型。虽然这种方法在某些场景下效果不错,但是由于一般语言的语法会很复杂,导致语法文件中的语法规则会很多,并且需要人工编写,工作量太大,且不同语言间语法规则需要重写,模型不可通用。所以随后统计语言模型被提出,该模型可以通过该语言的文本语料利用机器来训练得到该语言的语言模型,该方法的适应性很强。
随着统计语言处理方法的发展,统计语言模型成为语音识别中语言处理的主流技术,其中统计语言模型有很多种,如N-Gram语言模型、马尔可夫N元模型(Markov N-gram)、指数模型( Exponential Models)、决策树模型(Decision Tree Models)等。而N元语言模型是最常被使用的统计语言模型,特别是二元语言模型(bigram)、三元语言模型(trigram)。
以三元语言模型为例,设wi是文本中的任意一个词,如果已知它在该文本中的前两个词wi-2wi-1,便可以用条件概率P(wi | wi-2wi-1)来预测wi出现的概率。这就是N元语言模型的概念。用变量W代表文本中一个任意的词序列,即W=w1w2...wn,则统计语言模型就是用来计算W在该语言模型下中出现的概率P(W)。利用概率的乘积公式,P(W)可展开为:
![]() (3-1)
(3-1)
为了预测词wn的出现概率,必须知道它前面所有词串即w1w2...wn-1的出现概率。从计算上来看,这种方法需要计算的概率太多,导致模型太复杂。如果假设任意一个词wi的出现概率只同它前面的两个词有关,模型就可以得到极大的简化。这时的语言模型叫做三元语言模型,计算P(W)的公式变为式3-2。
 (3-2)
(3-2)
这些重要的概率参数可以通过大规模语料库来计算得到。对于三元语言模型,需要计算对应所有连续三个的词串,计算式3-3。
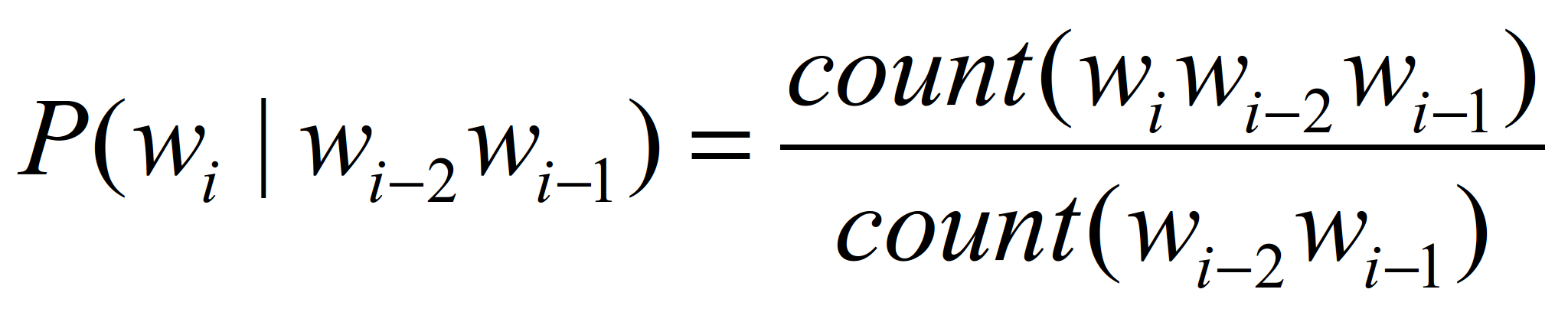 (3-3)
(3-3)
式中count(·) 表示某特定词串在整个语料库中出现的累计次数。一般常用的N元语言模型有3种,即unigram、bigram以及trigram,也就是N分别为1、2、3的情况。
1.3 发音词典
发音词典是存放所有单词的发音的词典,它的作用是用来连接声学模型和语言模型的。例如,一个句子可以分成若干个单词相连接,每个单词通过查询发音词典得到该单词发音的音素序列。相邻单词的转移概率可以通过语言模型获得,音素的概率模型可以通过声学模型获得。从而生成了这句话的一个概率模型。
1.4 解码器
解码器是自动语音识别系统的核心模块,其任务是对输入的语音信号,在由语句或者单词序列构成的空间当中,按照一定的优化准则,并且根据声学、语言模型及词典,生成一个用于搜索的状态空间,在该状态空间中索到最优的状态序列,即寻找能够以最大概率输出该信号的句子或者单词序列。
在大词汇量连续语音识别中的搜索算法可以按照搜索策略以及搜索空间扩展方式这两方面上进行分类。首先,按照搜索策略,搜索算法可以分为帧同步(Time-synchronous)的宽度优先搜索(Breadth First Search),比如帧同步Viterbi搜索算法,以及帧异步(Time-asynchronous)的深度优先搜索(Depth First Search),比如帧异步的堆栈搜索算法和A*算法。其次,按照搜索空间扩展的方式同样可以分为两种,一种方式是在解码之前静态扩展搜索空间,另一种是在解码时动态扩展搜索空间,Sphinx4语音识别软件就支持这两种扩展搜索空间的方式,它按照不同的语言模型来扩展搜索空间。当语言模型是基于语法文件时,由于搜索空间一般较小,Sphinx-4选择在解码之前静态扩展搜索空间;而当语言模型为trigram模型时,一般搜索空间很大,难以在内存中展开,或者内存开销太大,Sphinx-4选择在解码时动态扩展搜索空间。

