AcWing 205. 斐波那契
. 斐波那契
一、题目描述
在斐波那契数列中,。
给定整数 ,求 。
输入格式
输入包含多组测试用例。
每个测试用例占一行,包含一个整数 。
当输入用例 时,表示输入终止,且该用例无需处理。
输出格式
每个测试用例输出一个整数表示结果。
每个结果占一行。
数据范围
二、矩阵乘法
设 为 的矩阵, 为 的矩阵,设矩阵 为矩阵 与 的乘积,
其中矩阵 中的第 行第 列元素可以表示为:
如果没看懂上面的式子,没关系。通俗的讲,在矩阵乘法中,结果 矩阵的第 行第 列的数,就是由矩阵 第 行 个数与矩阵 第 列 个数分别 ①相乘 再 ②相加 得到的。
相关性质
乘法结合律:
单位矩阵:,其中的单位矩阵 符合:行数等于列数,对角线上的元素都是 ,其余都是
三、本题题解
如果有一道题目让你求斐波那契数列第 项的值,最简单的方法 莫过于直接 递推。但是如果 的范围达到了 级别,递推就不行了,稳稳 , 考虑 矩阵加速递推:
斐波那契数列( )大家应该都非常的熟悉了。在斐波那契数列当中,
我们知道,斐波那契数列有这样的定义:
那么如果我们有一个$2 × 2 f_{i − 1}$ 和。我们的目标是把第一行乘上一个矩阵变成和。那么应该怎么办呢?
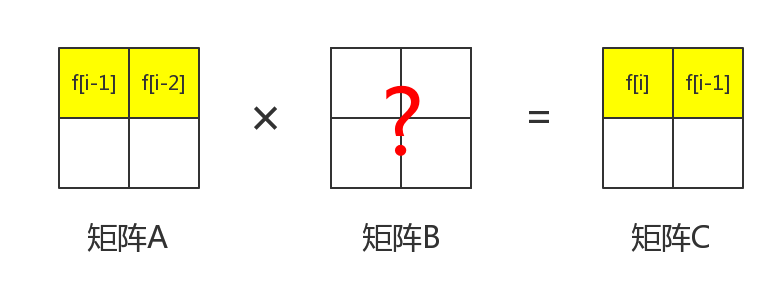
首先,矩阵和矩阵都含有 这一项。那么就先从这里下手。
我们知道,矩阵的在第行第列。那么,根据公式,可以得到
也就是说
那么很明显,我们可以得到。这样可以保证进行矩阵乘法之后 是。
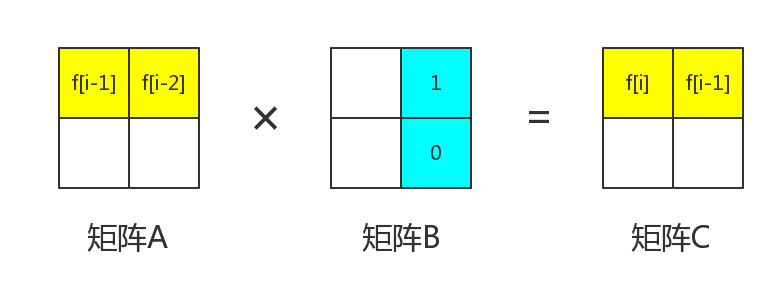
那么现在来看矩阵中的。我们要保证的是
也就是说
我们知道,。所以可以得到
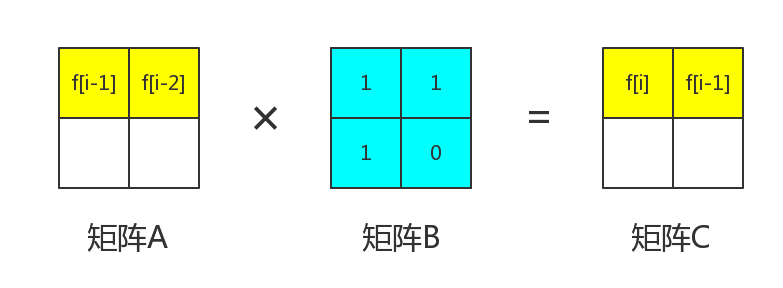
那么整个矩阵都被我们求出来了。
得到了 和 后,我们再将它乘一次矩阵,就可以得到和,又可以得到和,这样就可以得到了。
但是!
你以为就结束了?
这样的时间复杂度是,其中表示求斐波那契数列的第项,表示矩阵的长宽,还不如递推。而且递推可以得到到的所有斐波那契数,而矩阵乘法只能求第$n项。
其实还有个地方可以优化。
我们求的时候其实是将原矩阵乘了次矩阵的。也就是说
看到次方想到了什么?
可以用 快速幂!
我们用快速幂的思想求出,然后再乘上一个矩阵即可。
怎么用快速幂?
其实是一个道理。只不过把矩阵乘矩阵换成矩阵乘矩阵就可以了。
那么最终的时间复杂度为。还是很优秀的。
注意
矩阵乘法不满足交换律,所以一定不能写成 的第一行第一列元素。
-
对于 的情况,直接输出 即可,不需要执行矩阵快速幂。
-
为什么要乘上 矩阵的 次方而不是 次方呢?因为 是不需要进行矩阵乘法就能求的。也就是说,如果只进行一次乘法,就已经求出 了。如果还不是很理解为什么幂是 ,建议手算一下。
四、实现代码
#include <bits/stdc++.h>
using namespace std;
const int N = 10; //这个黄海实测,写成3也可以AC,考虑到矩阵乘法的维度,一般写成10,差不多的都可以过掉
const int MOD = 10000;
int base[N][N], res[N][N];
int t[N][N];
//矩阵乘法,为快速幂提供支撑
inline void mul(int C[][N], int A[][N], int B[][N]) {
memset(t, 0, sizeof t);
for (int k = 1; k <= 2; k++)
for (int i = 1; i <= 2; i++)
for (int j = 1; j <= 2; j++)
t[i][j] = (t[i][j] + (A[i][k] * B[k][j]) % MOD) % MOD;
memcpy(C, t, sizeof t);
}
//快速幂
void qmi(int k) {
memset(res, 0, sizeof res);
res[1][1] = res[1][2] = 1; //结果是一个横着走,一行两列的矩阵
// P * M 与 M * Q 的矩阵才能做矩阵乘积,背下来即可
//矩阵快速幂,就是乘k次 base矩阵,将结果保存到res中
//本质上就是利用二进制+log_2N的特点进行优化
while (k) {
//比如 1101
if (k & 1) mul(res, res, base); // res=res*b
mul(base, base, base); //上一轮的翻番base*=base
k >>= 1; //不断右移
}
}
int main() {
int n;
while (cin >> n) {
if (n == -1) break;
if (n == 0) {
puts("0");
continue;
}
if (n <= 2) {
puts("1");
continue;
}
// base矩阵
memset(base, 0, sizeof base);
/**
1 1
1 0
第一行第一列为1
第一行第二列为1
第二行第一列为1
第二行第二列为0 不需要设置,默认值
*/
base[1][1] = base[1][2] = base[2][1] = 1;
//快速幂
qmi(n - 2);
//结果
printf("%d\n", res[1][1]);
}
return 0;
}
五、思考题
https://blog.csdn.net/weixin_42638946/article/details/115872469
使用 快速幂优化 计算以下数列第 项 的值:
解:
思考 如何变化可以到达 ?
矩阵快速幂的一些题目
https://blog.csdn.net/ypeij/article/details/118785530


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2021-10-31 AcWing 125. 耍杂技的牛
2021-10-31 AcWing 148. 合并果子
2021-10-31 AcWing 907. 区间覆盖
2017-10-31 赤峰项目目前的mysql配置项目