P3808 【模板】AC 自动机(简单版)
【模板】 自动机(简单版)
AC自动机详细讲解
自动机真是个好东西!之前学被指针搞晕了,所以咕了许久都不敢开自动机,近期学完之后,发现自动机并不是很难,特别是对于,个人感觉自动机比要好理解一些,可能是因为我对树上的东西比较敏感(实际是因为我到现在都不会)。
很多人都说自动机是在树上作,我不否认这一种观点,因为这确实是这样,不过对于刚开始学自动机的同学们就一些误导性的理解(至少对我是这样的)。是建立在一个字符串上的,现在把搬到了树上,不是很麻烦吗?实际上自动机只是有的一种思想,实际上跟一个字符串的有着很大的不同。
所以看这篇,请放下,理解好,再来学习。
前置技能
- (很重要哦)
- 的思想(懂思想就可以了,不需要很熟练)
问题描述
给定个模式串和个文本串,求有多少个模式串在文本串里出现过。
注意:是出现过,就是出现多次只算一次。
默认这里每一个人都已经会了。
我们将个模式串建成一颗树,建树的方式和建完全一样。
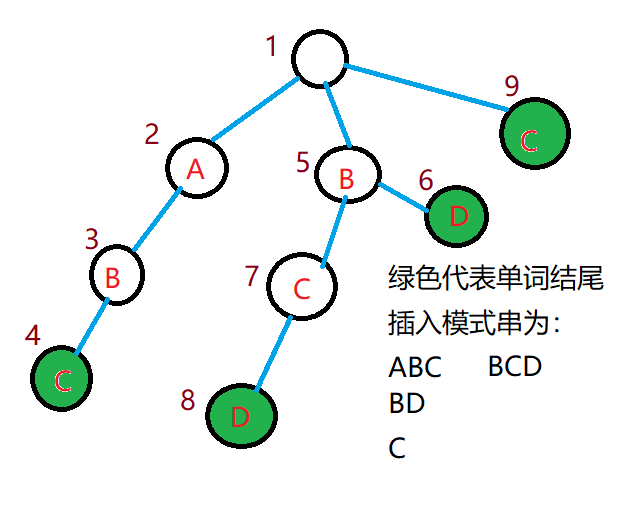
假如我们现在有文本串。
我们用文本串在上匹配,刚开始会经过号点,发现到,成功地匹配了一个模式串,然后就不能再继续匹配了,这时我们还要重新继续从根开始匹配吗?
不,这样的效率太慢了。这时我们就要借用的思想,从上的某个点继续开始匹配。
明显在这颗上,我们可以继续从号点开始匹配,然后匹配到。
那么我们怎么确定从那个点开始匹配呢?我们称匹配失败后继续从开始匹配,是的(失配指针)。
构建指针
的含义
指针的实质含义是什么呢?
如果一个点的指针指向。那么到的字符串是到的字符串的一个后缀。
举个例子:(例子来自上面的图)
到的字符串是
到的字符串是
是的一个后缀
所以的指针指向
同时我们发现, 也是的一个后缀。
所以指针指的的深度要尽量大。
重申一下指针的含义:((最长的(当前字符串的后缀))在上可以查找到)的末尾编号。
感觉读起来挺绕口的蛤。感性理解一下就好了,没什么卵用的。知道有什么用就行了。
求
首先我们可以确定,每一个点的指针指向的点的深度一定是比小的。(指的是后缀啊)
第一层的一定指的是。(比深度还浅的只有了)
设点的父亲的指针指的是,那么如果有和值相同的儿子,那么的就指向。这里可能比较难理解一点,建议画图理解,不过等会转换成代码就很好理解了。
由于我们在处理的情况必须要先处理好的情况,所以求我们使用来实现。
实现的一些细节
-
1、刚开始我们不是要初始化第一层的指针为,其实我们可以建一个虚节点号节点,将的所有儿子指向(编号为,记得初始化),然后的指向就了。效果是一样的。
-
2、如果不存在一个节点,那么我们可以将那个节点设为的((值和相同)的儿子)。保证存在性,就算是也可以成功返回到根,因为的所有儿子都是根。
-
3、无论存不存在和值相同的儿子,我们都可以将的指向。因为在处理的时候已经处理好了,如果出现这种情况,的值是第种情况,也是有实际值的,所以没有问题。
-
4、实现时不记父亲,我们直接让父亲更新儿子
void bfs() {
int hh = 0, tt = -1; //将队列的头和尾变量写在这里,可以有效防止多组测试数据的初始化问题
for (int i = 0; i < 26; i++)
if (tr[0][i]) q[++tt] = tr[0][i];
while (hh <= tt) {
int p = q[hh++];
for (int i = 0; i < 26; i++) {
int t = tr[p][i]; // p状态,通过i这条边,到达的新状态t; 也可以理解为是前缀
if (!t)
tr[p][i] = tr[ne[p]][i]; //节点 指向父节点失配指针的i这条边
else {
ne[t] = tr[ne[p]][i]; //失配指针指向父节点失配指针的i这条边
q[++tt] = t; //存在的要入队列
}
}
}
}
查询
求出了指针,查询就变得十分简单了。
为了避免重复计算,我们每经过一个点就打个标记为,下一次经过就不重复计算了。
同时,如果一个字符串匹配成功,那么他的也肯定可以匹配成功(后缀嘛),于是我们就把再统计答案,同样,的也可以匹配成功,以此类推……经过的点累加,标记为。
最后主要还是和的查询是一样的。
int res = 0;
for (int i = 0, j = 0; s[i]; i++) {
j = tr[j][s[i] - 'a']; //从j点出发,经t这条边,重复利用变量j,不断的移动游标j
//沿着失配指针不断向上,累加匹配值
for (int p = j; p && ~cnt[p]; p = ne[p]) res += cnt[p], cnt[p] = -1;
}
完整代码
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <iostream>
using namespace std;
const int N = 1000010;
int n; // n个模式串
char s[N]; //模式串
char T[N]; //文本串
// Trie树
int tr[N][26], idx;
int cnt[N];
void insert(char *s, int x) {
int p = 0;
for (int i = 0; s[i]; i++) {
int t = s[i] - 'a';
if (!tr[p][t]) tr[p][t] = ++idx;
p = tr[p][t];
}
cnt[p]++; //以p为结束节点的字符串个数+1,如果有重复的,这里++也是OK的~
}
// AC自动机
int q[N], ne[N];
void bfs() {
int hh = 0, tt = -1;
for (int i = 0; i < 26; i++)
if (tr[0][i]) q[++tt] = tr[0][i];
while (hh <= tt) {
int p = q[hh++];
for (int i = 0; i < 26; i++) {
int t = tr[p][i]; //此处直接优化为Trie图,没有采用原始的while向上递归处理的办法,记忆这个版本即可
if (!t)
tr[p][i] = tr[ne[p]][i];
else {
ne[t] = tr[ne[p]][i];
q[++tt] = t;
}
}
}
}
//查询字符串s中 n个模式串出现了几个
int query(char *s) {
int p = 0;
int res = 0;
for (int i = 0; s[i]; i++) {
p = tr[p][s[i] - 'a'];
for (int j = p; j; j = ne[j]) {
if (cnt[j] == -1) break;
res += cnt[j];
cnt[j] = -1;
}
}
return res;
}
int main() {
//加快读入
ios::sync_with_stdio(false), cin.tie(0);
cin >> n;
//构建Trie树
for (int i = 1; i <= n; i++) {
cin >> s;
insert(s, i);
}
//构建AC自动机
bfs();
//输入文本串
cin >> T;
//输出模式串出现的个数(注意:不是次数,是个数)
printf("%d\n", query(T));
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2018-05-12 C#解除文件锁定