AcWing 1285. 单词
. 单词
一、题目描述
某人读论文,一篇论文是由许多单词组成的。
但他发现一个单词会在论文中出现很多次,现在他想知道 每个单词分别在论文中出现多少次。
输入格式
第一行一个整数 ,表示有多少个单词。
接下来 行每行一个单词,单词中只包含小写字母。
输出格式
输出 个整数,每个整数占一行,第 行的数字表示第 个单词在文章中出现了多少次。
数据范围
,所有单词长度的总和不超过 。
输入样例:
3
a
aa
aaa
输出样例:
6
3
1
二、解题思路
对于图,其实最难理解的是它的指针,也就是当前单词的后缀可以匹配的最长前缀,当然这里写的是数组,意思是一样的。
类似于下面的这张图示:
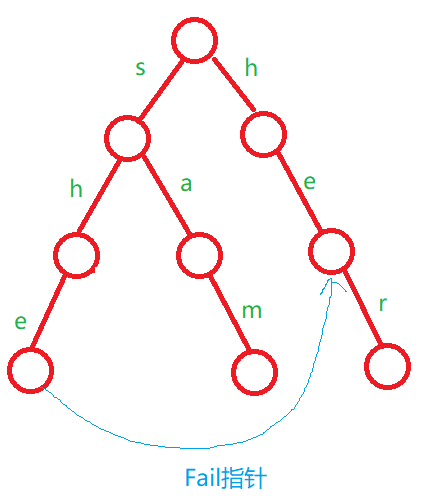
考虑完这个问题之后,我们用题目中的例子画一张图理解一下:

为什么可以这样呢,其实就是做了一个巧妙的转化,我们发现,要找所有单词中某个单词出现的次数,其实就是看在所有的前缀的后缀中某个单词出现的次数,这不就是数组的定义吗,问题也就解决了!
还有一点,我们所有 指针组成的边一定是一个 ,因为所有的 指针只能指向比自己层数更高的点。所以我们可以根据拓扑序来倒推,而我们用的是手写队列,就可以直接倒着遍历队列。
再来一个例子:

时间复杂度
时间复杂度是线性的,和所有单词的总长度有关,也就是。
三、实现代码
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <iostream>
using namespace std;
const int N = 1000010;
int n;
int tr[N][26], idx;
int f[N]; // 当前节点代表的字符串在整个trie中出现的次数,也用来记录递推结果
char s[N]; // 字符串
int id[210]; // 每个单词在trie中对应节点的编号,比如id[1]=2,表示第1个模式串,在trie树中是2号节点
void insert(char *s, int x) {
int p = 0;
for (int i = 0; s[i]; i++) {
int t = s[i] - 'a';
if (!tr[p][t]) tr[p][t] = ++idx;
p = tr[p][t];
f[p]++; //记录p节点代表的字符串在整个trie中出现的次数
}
id[x] = p; //记录x号单词在trie树中的节点编号
}
int q[N], ne[N];
void bfs() {
int hh = 0, tt = -1;
for (int i = 0; i < 26; i++)
if (tr[0][i]) q[++tt] = tr[0][i];
while (hh <= tt) {
int t = q[hh++];
for (int i = 0; i < 26; i++) {
if (!tr[t][i])
tr[t][i] = tr[ne[t]][i];
else {
ne[tr[t][i]] = tr[ne[t]][i];
q[++tt] = tr[t][i];
}
}
}
}
int main() {
//加快读入
ios::sync_with_stdio(false), cin.tie(0);
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> s;
insert(s, i);
}
// AC自动机
bfs();
//从下向上递推更新
for (int i = idx; i; i--) f[ne[q[i]]] += f[q[i]];
//输出
for (int i = 1; i <= n; i++) printf("%d\n", f[id[i]]);
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2018-05-12 C#解除文件锁定