AcWing 1172 祖孙询问
祖孙询问
一、题目描述
给定一棵包含 个节点的有根无向树,节点编号互不相同,但不一定是 。
有 个询问,每个询问给出了一对节点的编号 和 ,询问 与 的祖孙关系。
注:找出多对节点的祖孙关系,不是一对
输入格式
输入第一行包括一个整数 表示节点个数;
接下来 行每行一对整数 和 ,表示 和 之间有一条无向边。如果 是 ,那么 就是树的根;
第 行是一个整数 表示询问个数;
接下来 行,每行两个不同的正整数 和 ,表示一个询问。
输出格式
对于每一个询问,若 是 的祖先则输出 ,若 是 的祖先则输出 ,否则输出 。
数据范围
,
每个节点的编号
输入样例:
10
234 -1
12 234
13 234
14 234
15 234
16 234
17 234
18 234
19 234
233 19
5
234 233
233 12
233 13
233 15
233 19
输出样例:
1
0
0
0
2
二、最近公共祖先
( ),简称。
在一颗有根树中, 每个节点向上追溯都有一系列祖宗节点. 对于任意两个节点, 在它们祖宗节点的交集中离它们最近的节点称为它们的 最近公共祖先。
注意: 节点本身也可作为其祖先节点.
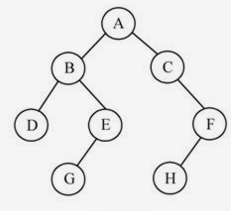
比如上图中的点和点的最近公共祖先节点就是点。下面介绍求解问题的两种基本方法:
向上标记法
我们自己是如何判断的呢?两只眼睛同时从点和点往上追溯,很快就可以定位到点。计算机向上回溯自然不是问题,但是并不能很快的判断出回溯过程中最先相交于哪一点,因此只能 异步 的执行节点的回溯。首先向上追溯到点、点,做好访问标记;然后点向上追溯到点,再往上到点发现已经做好标记了,于是点就是节点。这种求解的办法被称为 向上标记法 ,由其中一个节点向上走到根节点并做好标记,另一个节点再往上走的时候第一次遇见的已标记的节点就是最近公共祖先节点。向上标记法过程相当简单,书上说其复杂度是,即正比于树上节点的规模。其实该算法的复杂度用,也就是 树高 来衡量更加准确。
树上倍增法
向上标记法看似简单高效,求上图中和的固然很快,但是如果要 求多对节点 的呢?比如求、的,求、的,...,我们会发现点向上走的时候标记了其祖先节点,然后向上走又会标记一遍祖先节点,向上回溯的路径大都是相同的,这就 存在很大的冗余。
如果 同步 的向上回溯会怎样呢?预处理 下每个节点向上回溯任意步后的位置,记录下来,然后用某种算法快速的求出两个节点的。
最先遇见的困难就是节点和节点离他们的节点的 深度差不同。
如果 两个节点处于同一深度,比如和点,深度都是,我们完全可以 二分答案 了:先判断下和向上两步是不是到达了同一个节点,如果没到达,就向上四步。如果两个节点是处于同一深度的,我们在预处理节点向上走若干步的信息后,就可以在的时间内求出了。
当然既可以使用二分求解也可以使用 倍增求解,两个节点同时向上 走 ,,,,...步判断是否到达了同一点。那么我们在后面为什么要选择倍增而不是二分呢?这又是个问题。到这里我们其实已经不知不觉的理解了树上倍增法的第一个重要的步骤: 将两个节点调整到同一深度上。比如求和的,的深度是,的深度是,首先求出向上回溯到深度为的祖先节点,如果就是点,那么就是,否则继续求和的。此时就是求处于同一深度的两个节点的了,就十分方便了。所以 树上倍增法 无非就是先将深度大的节点调整到与深度小的节点同一深度(向上回溯),然后继续求。
再回到开头说的 预处理出所有节点向上回溯若干步的节点,这是十分没有必要的 。我们只需要 预处理出每个节点向上回溯的倍数步的节点 就可以满足我们所有的需要了。比如要回溯步,完全可以先走步,再走步,再走步,任何十进制整数肯定是可以转化为二进制表达的,,二进制拆分的思想足以让我们走到任意的地方。
为什么是先走步数最大的再逐步缩小步数,而不是先再再呢? 因为二进制拆分实现过程中并不需要我们真的去拆分,我们可以先尝试迈出一个很大的步数,比如,发现比大,于是迈出步,再尝试迈出步,发现又超过了,于是迈出步,最后迈出步,这是个不断尝试便于实现的倍增过程。调整到同一深度的两个节点需要再次使用倍增的方法求,比如先判断下两个节点向上回溯步的节点是不是同一个,是就说明不会在更高的位置了,于是重新判断向上回溯步的是不是同一个,如果不是,则说明还在上面,再对这个迈出步的两个节点继续向上回溯步,直至两个节点的父节点就是为止。
算法实现
:节点向上回溯步的节点标号
边界情况表示的 父节点。
数组的求解就是使用倍增法常用的动态规划公式了,要想求出向上走步的节点,只需要先求出向上走步的节点,然后再求向上走步的节点即可。状态转移方程:
预处理
可以在遍历树的过程中实现,同时记录下所有节点的深度。
void bfs(int root) {
//根结点的深度为1
depth[root] = 1;
queue<int> q;
q.push(root);
while (q.size()) {
int u = q.front();
q.pop();
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (!depth[v]) {
depth[v] = depth[u] + 1; //记录每个节点的深度
q.push(v);
f[v][0] = u; // f[v][0]表示v的父节点
//因为bfs的特性,所以在计算f[v][k]时,前序依赖数据
// f[v][k - 1],f[f[v][k - 1]][k - 1]肯定已经被填充过
for (int k = 1; k <= 20; k++)
f[v][k] = f[f[v][k - 1]][k - 1];
}
}
}
}
初始情况下将所有节点的深度设置为,所以一旦从可以走到并且的深度没有被标识过,就说明是的父节点,同时可以更新的深度了(无向图,防止走回头路)。我们知道遍历树的过程是层序遍历,遍历到时的祖先节点的信息都已经被预处理过了,所以此时
中的一定已经求出来了。
倍增代码
//最近公共祖先
int lca(int a, int b) {
// a保持深度更大,更下面
if (depth[a] < depth[b]) swap(a, b);
// 深度对齐
for (int k = 15; k >= 0; k--)
if (depth[f[a][k]] >= depth[b]) a = f[a][k];
//如果a,b是同一个点了,则LCA找到
if (a == b) return a;
//倍增查找,向结果逼近
for (int k = 15; k >= 0; k--)
if (f[a][k] != f[b][k])
a = f[a][k], b = f[b][k];
//返回结果
return f[a][0];
}
如果深度大于,就交换、节点 ,从而保持节点一直在下面。然后就是按照上面所说的 倍增 的操作二进制拆分调整到与同一深度,如果两点重合,就是点。否则,继续对、向上倍增求,最后的结果为什么是的父节点呢?这是因为倍增的终点就是和调整到节点的下一层。举个例子,比如和离有步,首先和都向上走步,然后想向上走步发现此时两点重合了,于是只走一步,此时倍增终止,和离恰好是一步之遥。
解释:
for (int k = 15; k >= 0; k--) if (f[a][k] != f[b][k]) a = f[a][k], b = f[b][k];这里的条件是不相等的才赋值吧?最后是不等的。也就是它俩的处在等、不等的临界点的,现在是不等,再多一点点就是等,而多一点点其实就是 ,即父节点。
五、实现代码
#include <bits/stdc++.h>
using namespace std;
const int N = 40010, M = 80010;
// 邻接表
int e[M], h[N], idx, ne[M];
void add(int a, int b) {
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
int n;
int depth[N]; // 每个节点的深度
int f[N][16]; // 设f[i][k]表示节点i向上回溯2^k步的节点标号
// 预处理
// 1、每个点的深度
// 2、记录节点i向上回溯2^k步的节点标号
void bfs(int root) {
queue<int> q; // 声明队列,准备从根开始对整棵树进行宽搜
q.push(root); // 根节点入队列
depth[root] = 1; // 根结点深度为1
while (q.size()) {
int u = q.front();
q.pop();
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (!depth[v]) { // 如果深度为0,表示没有访问过,防止走回头路
depth[v] = depth[u] + 1; // 记录每个节点的深度
f[v][0] = u; // f[j][0]表示j跳2^0=1到达的是它的父节点
q.push(v); // 下一次该j发挥作用了
/*举个栗子:
j 向上跳 2^0=1,2^1=2,2^2=4,2^3=8,2^4=16,2^5=32,...步,
分别记录这样跳到达的节点是什么编号,这样其实是按二进制思想记录的信息。
f[j][k] = f[f[j][k - 1]][k - 1] 采用了递推的思路,比如i向上想走8级,现在向上走了4级到达了j,也可以继续从j出发向上再走4次,是一回事, 但由于这样利用了已有结果会更快
因为bfs特性,在计算f[j][k]时,前序依赖数据已经被填充过,可以快速利用
*/
for (int k = 1; k <= 15; k++) f[v][k] = f[f[v][k - 1]][k - 1];
}
}
}
}
// 最近公共祖先
int lca(int a, int b) {
// a保持深度更大
if (depth[a] < depth[b]) swap(a, b);
// 对齐a,b,跳冒不跳,跳少再跳
for (int k = 15; k >= 0; k--)
if (depth[f[a][k]] >= depth[b]) a = f[a][k];
if (a == b) return a;
// 同级,跳冒不跳,跳少再跳
for (int k = 15; k >= 0; k--)
if (f[a][k] != f[b][k])
a = f[a][k], b = f[b][k];
// a的父节点,就是lca(a,b)
return f[a][0];
}
int main() {
memset(h, -1, sizeof h);
scanf("%d", &n);
int a, b, m, root;
for (int i = 0; i < n; i++) {
scanf("%d %d", &a, &b);
if (b == -1)
root = a; // 找到根节点
else
add(a, b), add(b, a); // 无向树
}
// 预处理,生成倍增的下2^k级跳位置数据f[i][k]
bfs(root);
scanf("%d", &m);
while (m--) {
scanf("%d %d", &a, &b);
int p = lca(a, b);
if (p == a)
puts("1");
else if (p == b)
puts("2");
else
puts("0");
}
return 0;
}
:为什么上面实现代码中用的上限是?
int res = 1;
for (int i = 1;; i++) {
res *= 2;
if (res > 4 * 1e4) {
printf("%d\n", i);
break;
}
}
结果输出是,题目中,当前节点占了一层,它的父节点表示是,所以,最多向上返层
如果不写成,写成会怎么样?
变大了,会跳到一个不存在的位置上去,代码显示跳到的是号位置,而我们知道,一般这样的题目,都是要求从,避开了号。
注意:如果真的想偷懒,不想仔细计算到底应该跳多少步,可以盲写成,但要注意的是除了要把代码中所有修改为外,还要记得把数组二维的大小改大,否则会,别问我怎么知道的~
f[19][0]=234 f[19][1]=0 f[19][2]=0 f[19][3]=0 f[19][4]=0 f[19][5]=0 f[19][6]=0 f[19][7]=0 f[19][8]=0 f[19][9]=0 f[19][10]=0 f[19][11]=0 f[19][12]=0 f[19][13]=0 f[19][14]=0 f[19][15]=0
f[18][0]=234 f[18][1]=0 f[18][2]=0 f[18][3]=0 f[18][4]=0 f[18][5]=0 f[18][6]=0 f[18][7]=0 f[18][8]=0 f[18][9]=0 f[18][10]=0 f[18][11]=0 f[18][12]=0 f[18][13]=0 f[18][14]=0 f[18][15]=0
f[17][0]=234 f[17][1]=0 f[17][2]=0 f[17][3]=0 f[17][4]=0 f[17][5]=0 f[17][6]=0 f[17][7]=0 f[17][8]=0 f[17][9]=0 f[17][10]=0 f[17][11]=0 f[17][12]=0 f[17][13]=0 f[17][14]=0 f[17][15]=0
f[16][0]=234 f[16][1]=0 f[16][2]=0 f[16][3]=0 f[16][4]=0 f[16][5]=0 f[16][6]=0 f[16][7]=0 f[16][8]=0 f[16][9]=0 f[16][10]=0 f[16][11]=0 f[16][12]=0 f[16][13]=0 f[16][14]=0 f[16][15]=0
f[15][0]=234 f[15][1]=0 f[15][2]=0 f[15][3]=0 f[15][4]=0 f[15][5]=0 f[15][6]=0 f[15][7]=0 f[15][8]=0 f[15][9]=0 f[15][10]=0 f[15][11]=0 f[15][12]=0 f[15][13]=0 f[15][14]=0 f[15][15]=0
f[14][0]=234 f[14][1]=0 f[14][2]=0 f[14][3]=0 f[14][4]=0 f[14][5]=0 f[14][6]=0 f[14][7]=0 f[14][8]=0 f[14][9]=0 f[14][10]=0 f[14][11]=0 f[14][12]=0 f[14][13]=0 f[14][14]=0 f[14][15]=0
f[13][0]=234 f[13][1]=0 f[13][2]=0 f[13][3]=0 f[13][4]=0 f[13][5]=0 f[13][6]=0 f[13][7]=0 f[13][8]=0 f[13][9]=0 f[13][10]=0 f[13][11]=0 f[13][12]=0 f[13][13]=0 f[13][14]=0 f[13][15]=0
f[12][0]=234 f[12][1]=0 f[12][2]=0 f[12][3]=0 f[12][4]=0 f[12][5]=0 f[12][6]=0 f[12][7]=0 f[12][8]=0 f[12][9]=0 f[12][10]=0 f[12][11]=0 f[12][12]=0 f[12][13]=0 f[12][14]=0 f[12][15]=0
f[233][0]=19 f[233][1]=234 f[233][2]=0 f[233][3]=0 f[233][4]=0 f[233][5]=0 f[233][6]=0 f[233][7]=0 f[233][8]=0 f[233][9]=0 f[233][10]=0 f[233][11]=0 f[233][12]=0 f[233][13]=0 f[233][14]=0 f[233][15]=0
总结
算法,本质就是一个二进制的拼凑组装大法,关键词如下:
- ① 深度
- ② 对齐
- ③ 倍增,二进制
- ④ 每个节点都记录信息
- ⑤ 尝试
- ⑥ 动态规划
- ⑦ 差一步到


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2019-03-29 需要下一步学习的方向
2012-03-29 未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0”提供程序。