
scrapy爬取数据的基本流程及url地址拼接
说明:初学者,整理后方便能及时完善,冗余之处请多提建议,感谢!
了解内容:
Scrapy :抓取数据的爬虫框架
异步与非阻塞的区别
异步:指的是整个过程,中间如果是非阻塞的,那就是异步过程;
非阻塞:关注拿到结果之前的状态 (如果拿到结果前在等待,是阻塞,反之,是非阻塞)
理解:
Scrapy 基本工作流程(简单--->复杂)
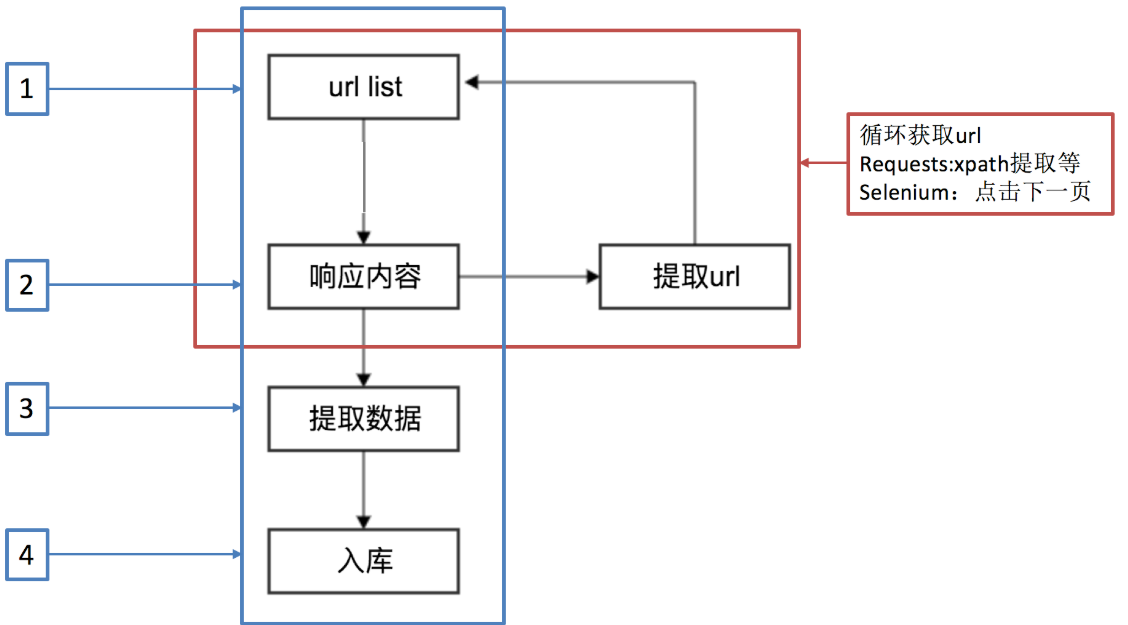
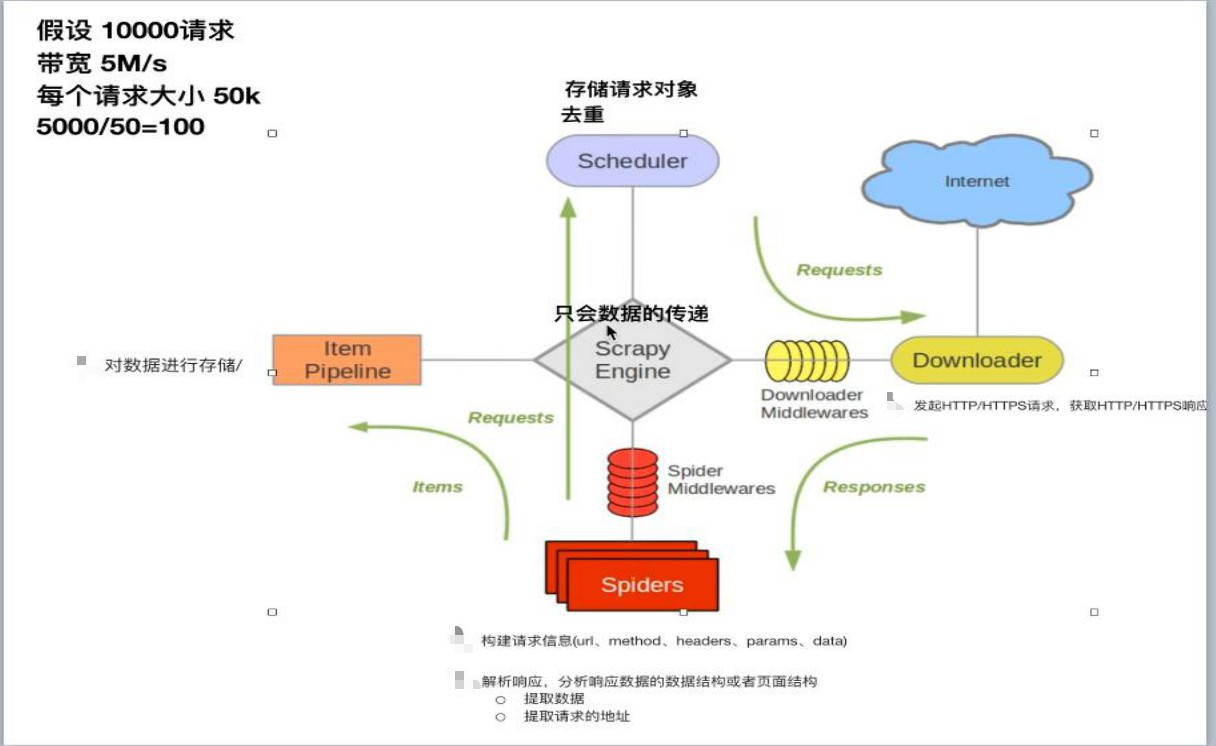
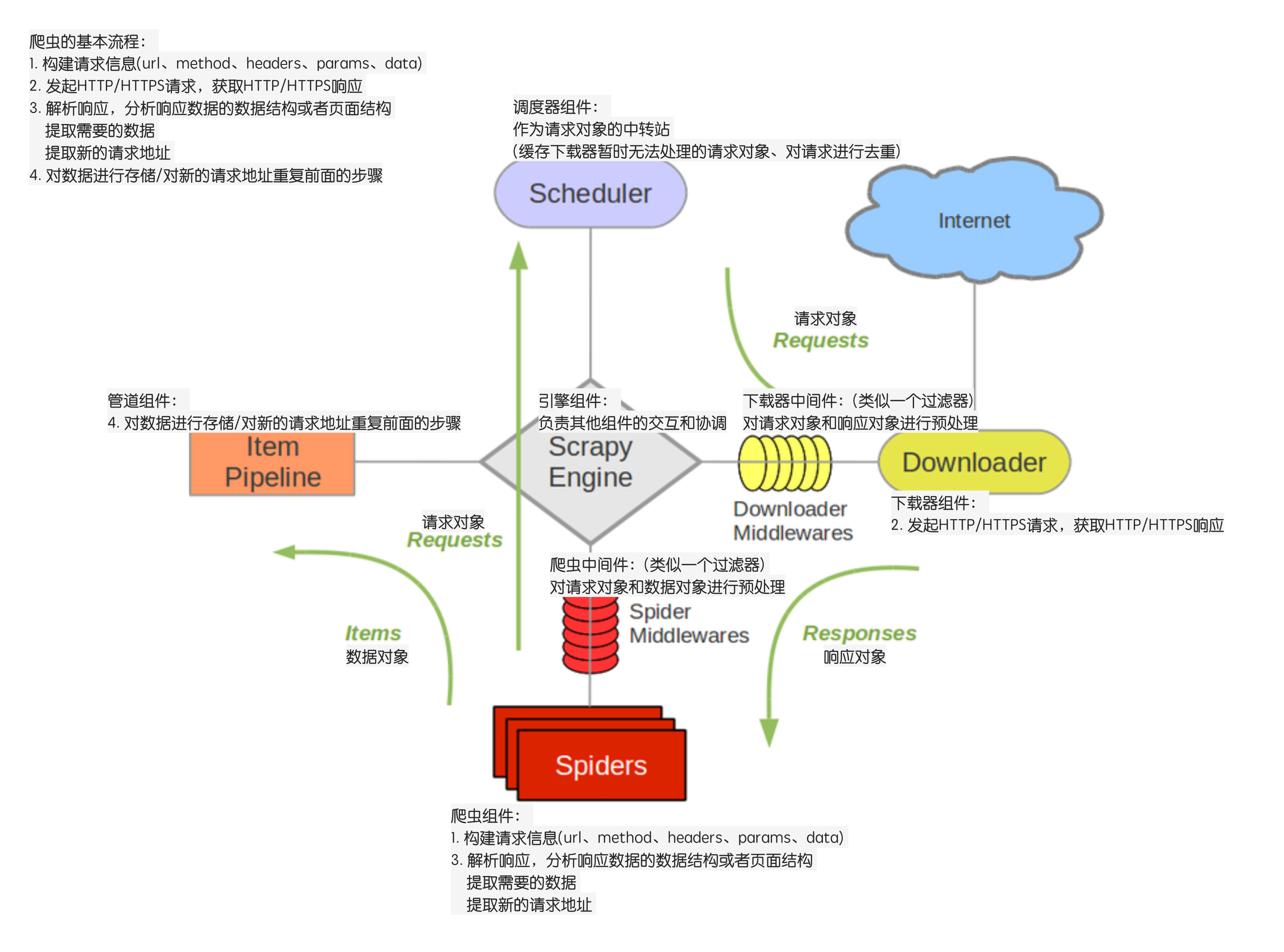
每个模块间不通讯,模块之间通过引擎进行数据传输

基本使用
一、创建spider
scrapy项目流程
---创建项目
---scrapy startproject xxxx
---创建爬虫
---cd 项目目录下
---scrapy genspider aaa allowed_domains"”
scrapy genspider first_spider jpdd.com
first_spider 爬虫名字
jpdd.com 限制爬取数据的范围
--完善spider
---提取数据,提取url地址构成request对象
xpath extract_first()\extract() response.meta yield scrapy.Requeest
--完善管道
--运行爬虫
--- cd 项目目录
---scrapy crawl first_spider
注意:避免爬虫名和项目名重复 ;
不管在终端还是pycharm 都要切换到当前目录下 cd myspider
allowed_domains : 限定爬取的范围
二、完善spider
---- 对数据的提取
1、 Scray 中的parse 做什么用途?
---处理start_urls 中的url地址的响应
2 、yiele 生成器的使用
好处:遍历函数的返回值的时候,挨个把数据读到内存,不会造成内存的瞬间占用过高
通过yield传递数据给管道,(类似转发)
yield能够传递的对象只能是:BaseItem, Request, dict, None
3 、使用.extract()把response.xpath()提取的数据转化为字符串列表
.extract() 返回一个含有字符串的列表,没有返回空列表
.extract_first() 提取列表中的第一个字符串,如果不存在,返回None
----例:
yield的使用:使用多个yield 来传递需要的数据
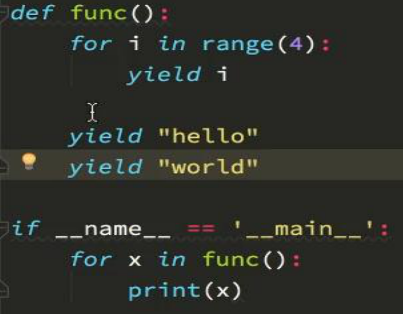

上面的代码应该改成:yield item
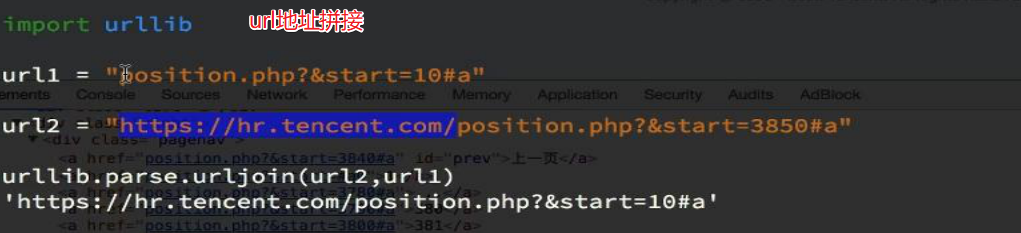
4、 根据Response返回的url地址,对next_url的url地址进行拼接,构造请求,有5种方式
第1种:手动字符串相加
第2种:urllib.parse.urljoin(baseurl,url) 后面的url会根据baseurl进行url地址的拼接
第3种:response.follow(url ,callback) 能够根据response的地址把url拼接完整,构造成Request对象,
但这个方法在python 1.0后的版本中才有
第4种(推荐):response.urljoin(next_url) 更简洁、好用
第5种:scrapy.Request(url,callback,meta,dont_filter)
---例:
# 第一种:手动拼接下一页url
#主站链接 用来拼接 base_site = 'https://www.jpdd.com' def parse(self,response): book_urls = response.xpath('//table[@class="p-list"]//a/@href').extract() for book_url in book_urls: url = self.base_site + book_url yield scrapy.Request(url, callback=self.getInfo) #获取下一页 next_page_url = self.base_site + response.xpath( '//table[@class="p-name"]//a[contains(text(),"下一页")]/@href' ).extract()[0] yield scrapy.Request(next_page_url, callback=self.parse)
使用urllib实现url地址拼接的原理:
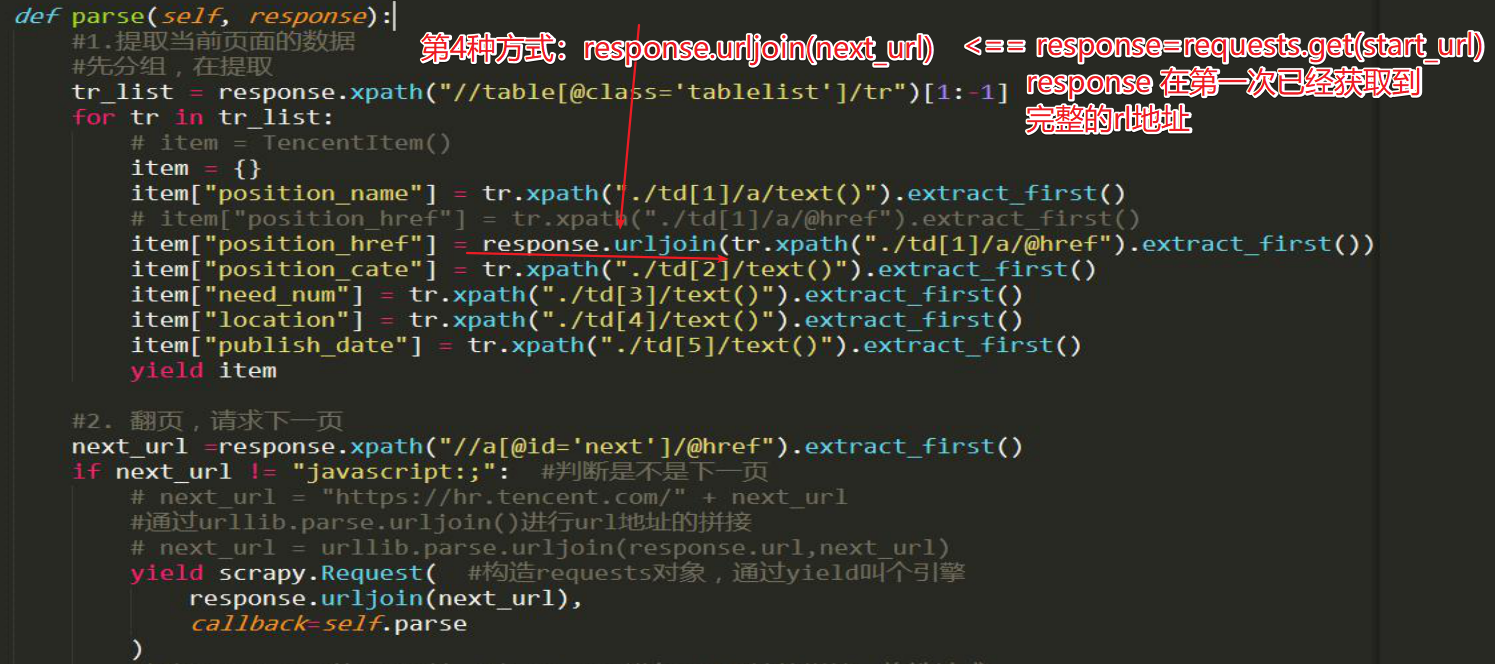
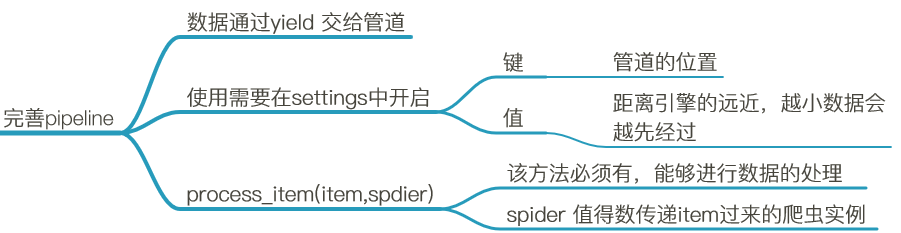
三、完善管道
管道的设置也是以键值的形式
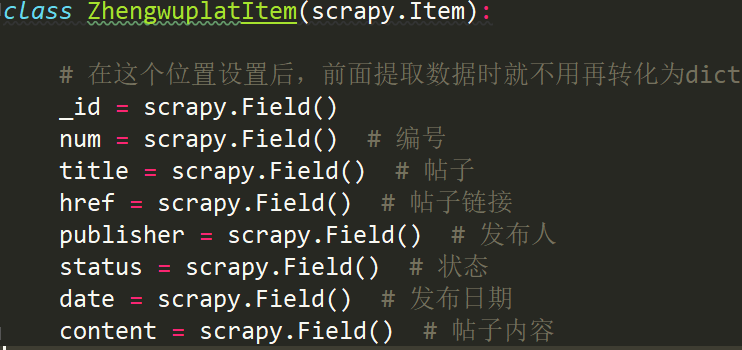
数据保存:可以是具体的item,也可以保存在文件中,如下2种方式
第一种:
第二种:


------数字越小,表示离引擎越近,数据越先经过处理,反之 。
-------使用多个管道时,前面的管道中要记得return xx 不然后面的管道接收不到前面的数据,会返回none
四、item的使用
为什么要单独定义item?
定义item即提前规划好哪些字段需要抓取,scrapy.Field()仅仅是提前占坑,通过item.py能够让别人清楚自己的爬虫是在抓取什么数据;
同时来提示哪些字段是需要抓取的,没有定义的字段不能使用,防止手误;
item不能直接存入mongodb中,需要转化为字典后再存储。
Item使用之前需要先导入并且实例化,之后的使用方法和使用字典相同
from yanguan.items import YanguanItem
item = YanguanItem() #实例化
补充:
构造翻页请求
meta 自身是个字典
Scrapy.Request() ===>相当于构造了一个requests对象
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
参数说明:
括号中的参数为可选参数
callback:表示当前的url的响应交给哪个函数去处理
meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
dont_filter:默认会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
感受成长的力量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号