五、MySQL系列之高级知识(五)
本篇 主要介绍MySQL的高级知识---视图、事件、索引等相关知识;
一、视图
在学习视图时我们需要什么是视图,视图有哪些好处以及视图的相关操作;
1.1 什么是视图?
关于视图通俗来讲就是一条select语句查询的结果集,本质而言就是一张虚表,与我们常说的快捷方式或者说软连接十分相似,它不存储具体的数据,而若基本表数据发生了改变,视图也会跟着改变。
1.2 视图的作用:
视图是一条select语句的结果集,故:
1、提高了重用性,类似一个函数,让我们想查询某些数据时,不需要每次敲复杂的select语句;
2、对数据库重构,却不影响程序的运行。即若不创建视图时,当我们修改基本表结构时,与Python交互时可能会出现问题。
3、提高了安全性。即通过视图我给不同用户呈现不同的数据。
4、让数据更加清晰,可读性更好
1.3 视图的相关操作
1、定义视图
语句: create view 视图名称 as select语句;
-- 定义视图 create view v_goods_info as select g.*,c.name from goods as g left join goods_cates as c on g.cate_id=c.id;
2、查看视图
视图时一张虚拟的表,故查看表所有的视图也会列出来;即 show tables ;
3、使用视图
视图的主要用途便是用于查询,而不是修改,注当修改多表定义的视图时,会容易报错;例如:
-- 查看视图 select * from v_goods_info; -- 修改视图时 update v_goods_info set name="皮皮虾我们走二代" where id=24; -- 报错 :ERROR 1288 (HY000): The target table v_goods_info of the UPDATE is not updatable
4、删除视图
drop view 视图名称
-- 删除视图 drop view v_goods_info
二、事务
同样对事务的学习我们也从什么是事务、事务有什么特性以及事务是如何操作的进行了解学习;
2.1 什么是事务?
所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行。它是一个不可分割的单位;
类似于银行转钱:假如用户A给用户B转200块钱,那么如果用户A给用户B转了钱之后,银行或者用户B出现了故障,导致用户A转了钱但是用户B没收到钱;这时就需要使用到事务,即:
用户A转钱和用户B收钱这两件事情要么都执行,要么都不执行;这样便会减少金钱纠葛了吧。
2.2 事务的四大特性:简称----ACID
即 原子性、一致性、隔离性、持久性;
原子性(Atomicity):即一个事务必须视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功要么全部失败滚回。
一致性(Consistency):数据库总是从一个一致性状态转换到另外一个一致性的转态;即用户A转出钱和用户B收到钱是一致的;
隔离性(Isolation):一个事务在进行操作时会被上锁,其他的用户无法在其提交前进行修改;
持久性(Durability):一旦事务被提交,则其所有的修改会永久的保存到数据库。例如用户A给用户B转的钱钱就退不回来了。
2.3 事务如何操作
1、开启事务 --begin 或者 start transaction;
2、提交事务 -- commit;
3、滚回事务 -- rollback;
-- 比如有以上四个用户,让用户2给用户1转钱 -- 开启事务 start transaction; -- 用户2扣钱 update money set num=num-100 where id=2; -- 用户1收钱 update money set num=num+100 where id=1; -- 提交或者滚回 commit; --或者 rollback;
三 、索引
3.1 索引是什么?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的应用指针;
3.2 索引的目的
提升查询效率,通常在实际开发过程中,查询的次数要远远大于修改,故提高查询效率十分关键;
通俗来讲:索引就像相当于一个字典的目录,若我们要查找一个字的时候,若从头到尾一路翻过去找则会超级麻烦,这时候了有了目录就方便且快速得多;索引也是同样的道理,可以大大提升查询效率,但是会占用一定的内存空间;
3.3 索引的原理
数据库的索引使用的 B-tree的查询方式。如下:
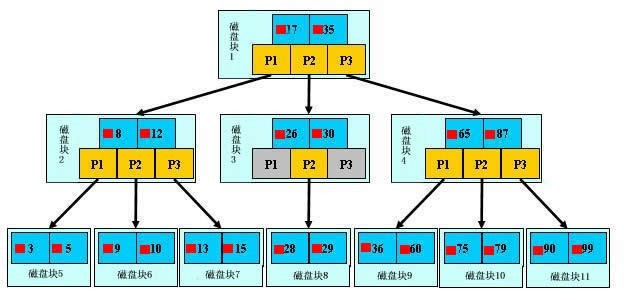
即:
数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段……这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。
3.3 索引的操作
1、查看索引 -- show index from 表名
2、创建索引 -- create index 索引名称 on 表名(字段名称(长度))
3、删除所有 -- drop index 索引名称 on 名称
小demo:


-- 创建一个表text_index create table text_index ( num int unsigned not null );
# 通过python 想表中插入十万条数据 from pymysql import connect def main(): # 创建Connection连接 conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8') # 获得Cursor对象 cursor = conn.cursor() # 插入10万次数据 for i in range(100000): cursor.execute("insert into test_index values('ha-%d')" % i) # 提交数据 conn.commit() if __name__ == "__main__": main()
-- 开启运行时间监测: set profiling=1; -- 查找第1万条数据ha-99999 select * from test_index where title='ha-99999'; -- 查看执行的时间: show profiles; -- 为表title_index的title列创建索引: create index title_index on test_index(title(10)); -- 执行查询语句: select * from test_index where title='ha-99999'; -- 再次查看执行的时间 show profiles;
从上述执行结果可以看出来:添加索引查询会大大建立查询时间,但是创建索引本身也会消耗一定的时间;
注:1、建立太多的索引将会影响更新和插入的速度,因为它需要同样更新每个索引文件。
2、建立索引会占用磁盘空间;
over~~~ 下篇介绍关于数据库权限设置和数据的备份~~~~~
本文来自博客园,作者:Little_five,转载请注明原文链接:https://www.cnblogs.com/littlefivebolg/p/9389888.html
