第十五篇:多任务系列之进程(二)
本篇主要介绍关于多进程的相关知识,同时需对进程与线程之间的关系和区别及应用进行了解,其实包含 multiprocessing模块下的 Process类、进行进程间通信的 Queue类以及进程池 Pool类的学习,最后实现一个实例 模拟文件夹copy器;
一、什么是进程?
首先我们在了解进程之前,我们需要了解一下什么是程序?
程序:
其实就是一堆躺在操作系统下的二进制文件,是静态的;例如 wechar.exe文件,在我们没点击它时,就是一个静态的可执行文件。
进程:
进程就是跑起来的程序,即代码 + 操作系统根据其需求为其分配的资源称之为进程;例如:当一个 Wechat.exe文件我们点击运行时,操作系统会为其调配其所需资源,则运行该程序就是一个进程;进程是操作系统分配资源的基本单位。
需要注意的是:同一个程序执行两次,那就是两个进程;例如 打开腾讯视频--》一个可以播放西游记,一个可以播放红楼梦;
进程的状态:
在现实工作中,任务的数量要远远大于CPU的数量,所以要想实现真正意义上的并行几乎是不可能的,所以大多数情况下都是并发(伪并行),故当运行多个进程时,有的程序处于等待的状态、有的程序处于运行的状态,则进程就可以分为以下几种状态:
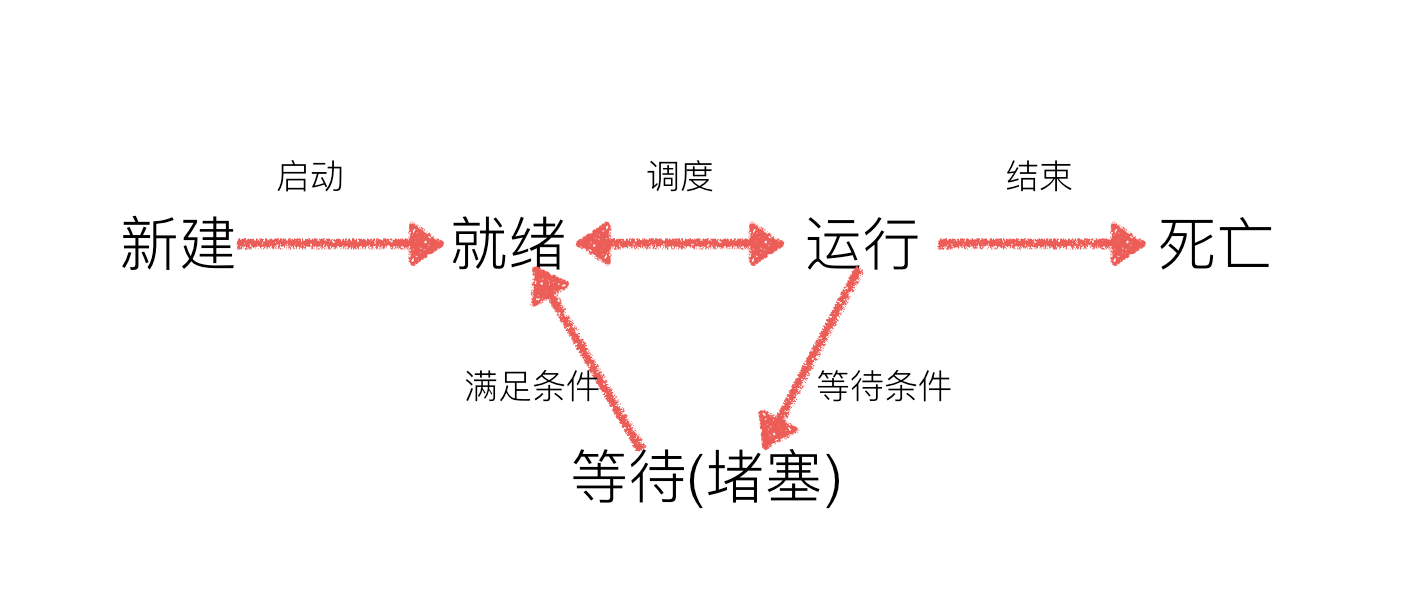
三种状态:
就绪:所有准备工作均完成,等待着操作系统分配CPU进行执行;
运行:正在被CPU执行的程序
堵塞:即待某些条件满足,例如一个程序sleep,此时就处于等待态。
二、多进程的创建过程:、
我们创建多进程主要通过模块 multiprocessing 下的Process类来创建进程对象,通过进程对象来实现创建进程的效果,不多说直接看示例,例如:
#!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing,time def sing(name): for i in range(10000): print("%s is singing --->%s"%(name,i)) # time.sleep(0.5) def dance(name): for i in range(10000): print("%s is dancing ---> %s"%(name,i)) # time.sleep(0.5) def main(): # 1、创建进程对象,传入工作函数,以及工作函数所需参数 p1 = multiprocessing.Process(target=sing,args=("alex",)) p2 =multiprocessing.Process(target=dance,args=("liudehua",)) # 2、启动进程 p1.start() p2.start() print("This is main process...") # 3、主进程等子进程运行完才关闭 p1.join() p2.join() if __name__=="__main__": main()
从上述例子中可以看出:进程的创建过程与线程的创建过程几乎相同,除了使用模块不相同,其他的几乎类似。那么既然有了线程为什么还要有进程呢?接下来我们就了解一下进程和线程的区别。
三、线程和进程的区别及应用场景
首先我们需要知道无论是线程还是进程均可以实现多任务的效果,但是一个进程必然有一个线程,同时一个进程也可以有多个线程,例如:一个WeChat可以打开多个聊天窗口,与不同的人进行聊天。其关系如下图:
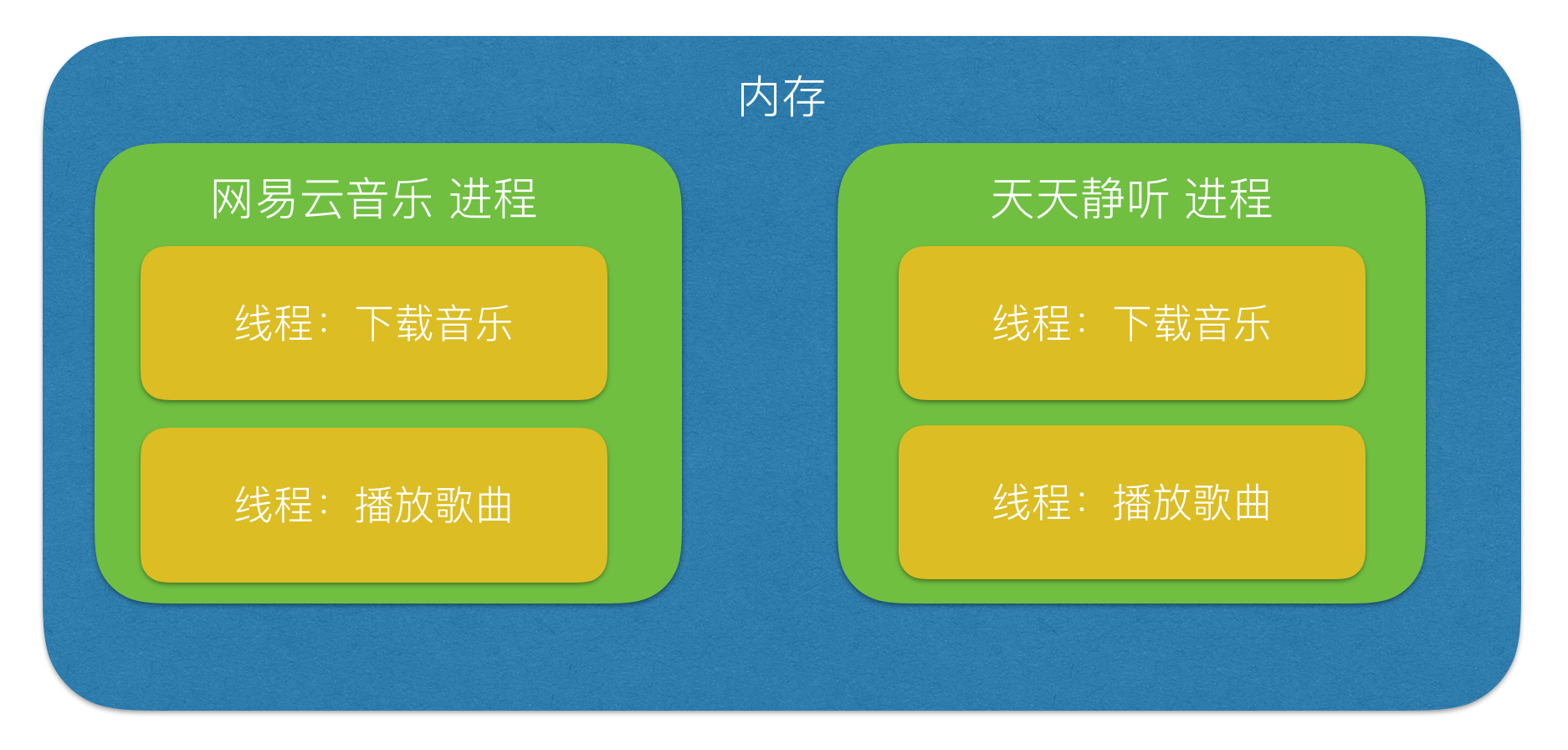
从上面的图我们可以很明确的看出进程与线程之间的关系和区别:
1、一个程序至少有一个进程(当然也可以有多个进程,例如:一个QQ可以同时登入两个用户;),一个进程至少有一个线程(当然也可由多个线程,例如:一个QQ可以同时与两个人进行聊天。)
2、线程无法独立存在,只能依附在进程内执行,即在QQ没有运行的情况下QQ聊天是无法实现的。
3、一个进程的运行需要调配的资源要多得多,但是进程要稳定许多,即一个进程的关闭不会影响另外一个进程的运行,即关闭网易云音乐队天天静听的执行没有任何影响;但是一个主线程的关闭必然会导致所有的子线程死亡,稳定性不如进程。
4、线程可以共享全局变量,而进程间无法全局变量的共享;(要想实现进程间的通信需使用队列等,在后面介绍。)
5、进程是操作系统进行资源管理的基本单位,而线程是对操作系统的分配下来的资源调用的基本单位。
其实我们也可以将进程和线程比喻成:车间流水线的工作(进程) 和 流水线上工人的工作(线程):

个人理解:
可以将进程比如成流水线的运行,即在该流水线的运行需要各种资源(即进程的运行需要操作系统调配资源),以及许多工人,这些工人在不停的工作(线程),他们对该流水线上的资源是共享的(线程间共享全局变量),同时若想提高流水线的运行速度,则可以为流水线增加一些工人(多线程),而同时若想提高车间的生产能力,则可以通过增加多条流水线(多进程),但是每增加一条流水线,所需的成本也高一些(即进程需调配的资源增加),同时每个流水线上的资源是不共享的(即进程间不共享全局变量。)。
4、获取进程的PID和PPID
每个进程均会有进程号以及父进程号,在Linux中可以通过 ps - aux或者top命令查看当前进程,kill命令+pid杀死进程,而在Windows中可以通过在cmd终端中 tasklist命令查看进程,通过taskkill +pid 杀死进程;那么我们如何在获取进程号呢?
#!/usr/bin/env python # -*- coding:utf-8 -*- #!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing,time,os def sing(name): """唱歌""" for i in range(3): print("%s is singing --->%s"%(name,i)) time.sleep(0.5) print("---in sing process-- pid:%s, ppid:%s ."%(os.getpid(),os.getppid())) # 查看运行sing函数的子进程的pid和ppid def dance(name): for i in range(3): print("%s is dancing ---> %s"%(name,i)) time.sleep(0.5) print("---in dance process-- pid:%s, ppid:%s ." % (os.getpid(), os.getppid())) # 查看运行dance函数的子进程的pid和 ppid def main(): # 1、创建进程对象,传入工作函数,以及工作函数所需参数 p1 = multiprocessing.Process(target=sing,args=("alex",)) p2 =multiprocessing.Process(target=dance,args=("liudehua",)) # 2、启动进程 p1.start() p2.start() print("This is main process...") print("---in main process-- pid:%s, ppid:%s ." % (os.getpid(), os.getppid())) time.sleep(0.5) p1.terminate() #杀死子进程 # 3、主进程等子进程运行完才关闭 p1.join() p2.join() if __name__=="__main__": main()
注:从运行结果得知:子进程的父进程就是主进程,而主进程的父进程其实为为当前集成开发IDE的运行进程PID。
关于进程的运行顺序:
主进程最先运行,而子进程的运行顺序完全由操作系统所决定。
孤儿进程:
当主进程被杀死的时候,子进程是不会死亡的,这种进程被称为孤儿进程;而除了一个pid为1的进程外,其他的进程均有父进程,这时这些孤儿进程会被收养到孤儿院,根据孤儿进程的ppid我们可以得知该孤儿院为 进程ID为2041的upstart进程。
僵尸进程:
当子进程被杀死时,父进程不会为该子进程收尸即不会对其所占资源进行回收,则该子进程被称为僵尸进程,这类僵尸进程是对系统的运行时不利的,故我们通常通过join()方法来避免僵尸进程的出现。
5、Queue实现进程间的通信
首先,我们需要知道进程间不共享全局变量,例如:网易云音乐无法播放酷狗中的音乐,接下来我们从一个例子中验证:
#!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing,time # 创建全局变量 name =["alex","little-five","amanda"] def work1(): # work1修改全局变量 name.append("hello") print(name) def work2(): # work2查看全局变量 print("in the work2:--> ",name) def main(): p1 = multiprocessing.Process(target=work1) p2 = multiprocessing.Process(target=work2) p1.start() time.sleep(1) # 休眠1s,保证进程p1先运行 p2.start() print("in main process : ",name) p1.join() p2.join() if __name__=="__main__": main()
从输出结果可以得出 : 进程间不共享全局变量,即即使主进程与子进程间也不共享全局变量。这是由于:
进程每创建子线程时,老版本内核会相当于将主进程的资源和代码copy一份,但每个子线程运行的代码位置不同,但是新版本则不会拷贝代码而是代码共享,而当某个进程要修改代码时,则是相应的代码进行拷贝即写时拷贝。
注:在线程中我们有互斥锁,而进程用于不存在全局变量共享问题,则就不需要互斥锁,而是利用Queue来实现进程间的通信。
那么我们怎么实现进程间的通信呢?
#!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing def recv_msg(q): """数据的接收""" names =["alex","wupeiqi","linghaifeng"] for name in names: q.put(name) #将每个名字传入队列 def analysis_msg(q): """数据的分析""" new_names =list() while not q.empty(): new_name=q.get() # 获取队列中的名字 new_names.append(new_name) print(list(map(lambda x:x.title(),new_names))) #通过map 函数对列表进行处理 q=multiprocessing.Queue() # 创建队列对象 def main(): p1 = multiprocessing.Process(target=recv_msg,args=(q,)) #我们将队列作为工作函数的参数传入进程 p2 = multiprocessing.Process(target=analysis_msg,args=(q,)) p1.start() p2.start() p1.join() p2.join() if __name__=="__main__": main()
注:其实队列就像一根水管,即先入先出,后入后出,数据从水管的一边传入从另一边输出,通过队列来实现进程间的数据传递,实现进程间的通信。
6、 进程池
在学习进程池之前,我们需要了解为什么我们需要学习进程池:
我们知道通过一个进程我们可以实现一个复杂的任务,但是当我们有许多个任务即成千上万的任务或者这些任务要重复执行时,这时候我们就需要用到进程池。下面我们看一下进程池的用法:
#!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing,time,os def cal(num):
"""计算""" n =0 for i in range(num): n+=1 time.sleep(0.2) print("01-the result is -->%s ,PID: %s ."%(n,os.getpid())) def worker(lis): """计算map函数运行时间""" start_time = time.time() new_list=list(map(lambda x:x.title(),lis )) time.sleep(1) end_time =time.time() print("02--close_time -->%s,PID:%s ,"%(end_time-start_time,os.getpid())) def main(): po = multiprocessing.Pool(3) # 定义进程池,规定进程池中最大的进程数为3 for i in range(100): # 让上面的两个任务重复执行100次 po.apply_async(cal,args=(100,)) # 每次循环结束均会有子进程去执行任务 po.apply_async(worker,args=(["alex","little-five","hello"],)) print("---start----") po.close() # 关闭进程池 po.join() # 等待子进程全部执行完,必须放在close之后 print("---end-----") if __name__ == "__main__": main()
那么进程池的实现机制是怎么样的呢?
始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。若任务数量十分多的时候,这些任务会被操作系统加载到一个内存中,被进程池中的进程循环执行。
7、实例:,模拟文件夹copy器
#!/usr/bin/env python # -*- coding:utf-8 -*- import os,multiprocessing,time def copy_file(queue,source_folder,new_folder,file_name): """将源文件内文件数据读取出来 写入新文件夹内的文件中""" source_file_path = source_folder + "/" + file_name f1 = open(source_file_path,"rb") file_data = f1.read() f1.close() new_file_path = new_folder + "/" + file_name f2 = open(new_file_path,"wb") f2.write(file_data) f2.close() # 每copy一个文件,将文件名传入队列,告诉主进程已完成一个文件的拷贝 queue.put(file_name) def main(): # 1、获取源文件夹文件名 while True: source_folder_name = input("请输入源文件夹名称:--》") if os.path.exists(source_folder_name): break # 2、创建目标文件夹 new_folder_name = source_folder_name + "-copy" try: os.mkdir(new_folder_name) except Exception as e: pass # 3、获取源文件的文件 file_list = os.listdir(source_folder_name) # 创建队列来实现主线程和子线程间的通信 q = multiprocessing.Manager().Queue() # 4、通过进程池来实现原文件数据的读取和写入新文件(文件数量较多,故采用进程池) po = multiprocessing.Pool(5) for file_name in file_list: #没一个文件的成品copy用进程池中的一个进程来实现 po.apply_async(copy_file,args=(q,source_folder_name,new_folder_name,file_name)) po.close() po.join() # 实现进度条的效果 source_len = len(file_list) # 获取源文件列表的长度 while True: time.sleep(0.2) over_copy_filename = q.get() # 获取已完成copy文件的文件名 # new_file_list = os.listdir(new_folder) if over_copy_filename in file_list: # 如果该文件已完成copy,则移除从源文件列表中移除该文件名 file_list.remove(over_copy_filename) len_tax = len(file_list)/source_len print(" \r 进度为:--》%0.2f %%" % (100 * (1 - len_tax)), end="") if len_tax == 0: print("\n copying file is over ..") break if __name__ =="__main__": main()
本文来自博客园,作者:Little_five,转载请注明原文链接:https://www.cnblogs.com/littlefivebolg/p/9298606.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号