re模块
关于re模块的介绍我们主要学习其元字符的用法、以及其模块下的几种方法(重点有findall/search/macth/split等,当然还有/sub/subn/finditer/compile等)等
定义:就本质而言,re(正则表达式)是一种小型的、高度专业化的编程语言,它内嵌在Python语言中,主要用于字符串的模糊匹配。
一、元字符
通常字符的匹配,有两种方式:
普通字符:大多数字符和字母都会和自身匹配,这种可以称为精准匹配。例如:
>>> import re >>> re.findall("amanda","helloamandaworld") #普通字符匹配 ["amanda"]
元字符:可以规定满足一定的条件下即可对字符串进行匹配,这种可以称为模糊匹配。其有以下几种元字符:
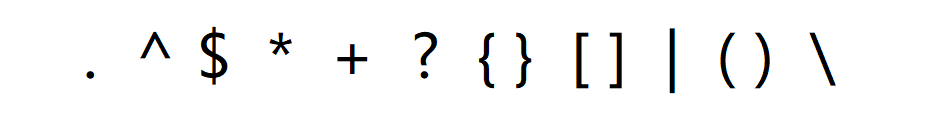
而每种方法的用途如下:

示例:
import re #. -->通配符,除\n以外的任意字符 >>> re.findall("a.","amanda") ['am', 'an'] #返回的是a以及a以后的一位 >>> re.findall("a..","amanda") ['ama'] #返回的是a以及a以后的两位 #^ -->从字符串开头开始匹配 >>> re.findall("^a.","amanda") ['am'] #$ -->从字符串末尾开始匹配 >>> re.findall("a..x$","helloalex") ['alex'] #* -->该字符重复匹配0或者0次以上 >>> re.findall("alex*","helloalexxxx") ['alexxxx'] #+ -->该字符重复匹配1或者1次以上 >>> re.findall("alex+","helloalexxxx") ['alexxxx'] #* 与 + 的区别:两者均为贪婪匹配 >>> re.findall("alex+","helloale") [] >>> re.findall("alex*","helloale") ['ale'] #? -->该字符串匹配0次或者1次 >>> re.findall("alex?","helloalexxxx") ['alex'] #{} -->可指定该元素重复匹配多少次或者之间 >>> re.findall("alex{1,3}","helloalexxx") ['alexxx'] #x重复匹配1-3次 #注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配,例如: >>> re.findall("alex+","helloalexxx") ['alexxx'] #贪婪匹配 >>> re.findall("alex+?","helloalexxx") ['alex'] #惰性匹配 #---------------------------------------------------------------------------------- #[] -->字符集,字符集内无特殊字符(^ - \除外),字符集内元素为或的意思 >>> re.findall("a[bcl]lx","helloablx") #匹配字符集内某个元素 ['ablx'] >>> re.findall("a[*+%]ex","helloa*ex") ['a*ex'] #1、字符集内特殊字符---- - >>> re.findall("a[a-z]ex","helloalexx") ['alex'] #2、字符集内特殊字符---- ^ ,非 >>> re.findall("[^ab]","abcdadc") ['c', 'd', 'd', 'c'] >>> re.findall("\([^()]*\)","12+8*(5*(3+2)+12)") ['(3+2)'] #匹配运算的最先运算的值 #3、字符集内特殊字符--- \,转义符 >>> re.findall("[\d]","hello123") ['1', '2', '3'] >>> re.findall("\d+","alex33little-five22amanda23") ['33', '22', '23'] #---------------------------------------------------------------------------------- #元字符之分组------ () >>> re.findall("(alex)?","alexalex") ['alex', 'alex', ''] >>> re.findall("alex+","alexxx") ['alexxx'] #---------------------------------------------------------------------- #元字符之管道符 ----- |(或) >>> re.findall("ab|ac|ad","adhelloac") ['ad', 'ac'] >>> re.findall("av|\d","avhello123") ['av', '1', '2', '3']
元字符之转义符 ---- \
\ -->转义符,反斜杠后边跟元字符去除特殊功能,比如 \. 。
反斜杠后边跟普通字符实现特殊功能,比如 \d 。
|
\d 匹配任何十进制数;它相当于类 [0-9]。 \D 匹配任何非数字字符;它相当于类 [^0-9]。 \s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。 \S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。 \w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。 \W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_] \b 匹配一个特殊字符边界,比如空格 ,&,#等 |
例如:
# \d -- 匹配任何十进制数;它相当于类 [0-9]。 >>> re.findall("\d+","amanda23little-five22alex33") ['23', '22', '33'] #\D 匹配任何非数字字符;它相当于类 [^0-9]。 >>> re.findall("\D+","amanda23little-five22alex33") ['amanda', 'little-five', 'alex'] #\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。 >>> re.findall("\s+","hello\n\t world") ['\n\t '] #\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。 >>> re.findall("\S+","hello\n\t world") ['hello', 'world'] #\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。 >>> re.findall("\w+","alex$hello%world") ['alex', 'hello', 'world'] #\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_] >>> re.findall("\W+","alex$hello%world") ['$', '%'] #\b 匹配一个特殊字符边界,比如空格 ,&,#等 >>> re.findall(r"I\b","I am little-five") ['I'] #------------------------------------------------------------------- #关于被匹配字符串中存在转义符 >>> re.findall("\\\\d","little\dfive") ['\\d'] #注其原理如下图:


二、re模块下的方法
re模块下的方法有 search、findall、match、split、sub、subn、compile、finditer等方法。
>>> import re #1、findall()---> #返回所有满足匹配条件的结果,放在列表里 >>> re.findall("\D+","amanda23little-five22") ['amanda', 'little-five'] #2、search() -->#函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象, #该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 >>> re.search("\D+","amanda23little-five22") <_sre.SRE_Match object; span=(0, 6), match='amanda'> >>> res.group() 'amanda' #3、split--->先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 >>> re.split("[ac]","abcd") ['', 'b', 'd'] #4、match -->从头开始匹配,返回一个包含匹配信息的对象 >>> re.match("h.{4}","helloworld") <_sre.SRE_Match object; span=(0, 5), match='hello'> #5、sub -->匹配替换 >>> re.sub("\d","-","little5five") 'little-five' >>> re.subn("\d","-","little5five xiao5wu",0) ('little-five xiao-wu', 2) #返回替换结果和替换次数 #6、类似findall,但是返回是对象 >>>res=re.finditer("\D","little5five xiao5wu") <callable_iterator object at 0x0000021D84E89198> >>> ret=next(res) <_sre.SRE_Match object; span=(0, 1), match='l'> >>> ret=next(res) >>> ret.group() 'l'
取消优先级:
import re ret=re.findall('www.(baidu|sina).com','www.oldboy.com') print(ret)#['sina] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret=re.findall('www.(?:baidu|sina).com','www.oldboy.com') print(ret)#['www.sina.com']
本文来自博客园,作者:Little_five,转载请注明原文链接:https://www.cnblogs.com/littlefivebolg/articles/9183835.html
