Selenium爬取MOOC网课程信息
近期在写一份关于大数据相关的作业,需要搜索近年来市面上关于大数据的书籍信息和课程信息。其中一位同学负责在当当网上爬取书籍信息,我就负责爬取MOOC网的课程信息。
刚开始的时候,以为MOOC网作为一个公益性网站,安全性不会那么高,因此会比较好爬。然而我还是太天真了,网站上一大批JavaScript让我不知所措。好在经过一段时间的探索,终于能够成功爬取了。
1. 网站分析
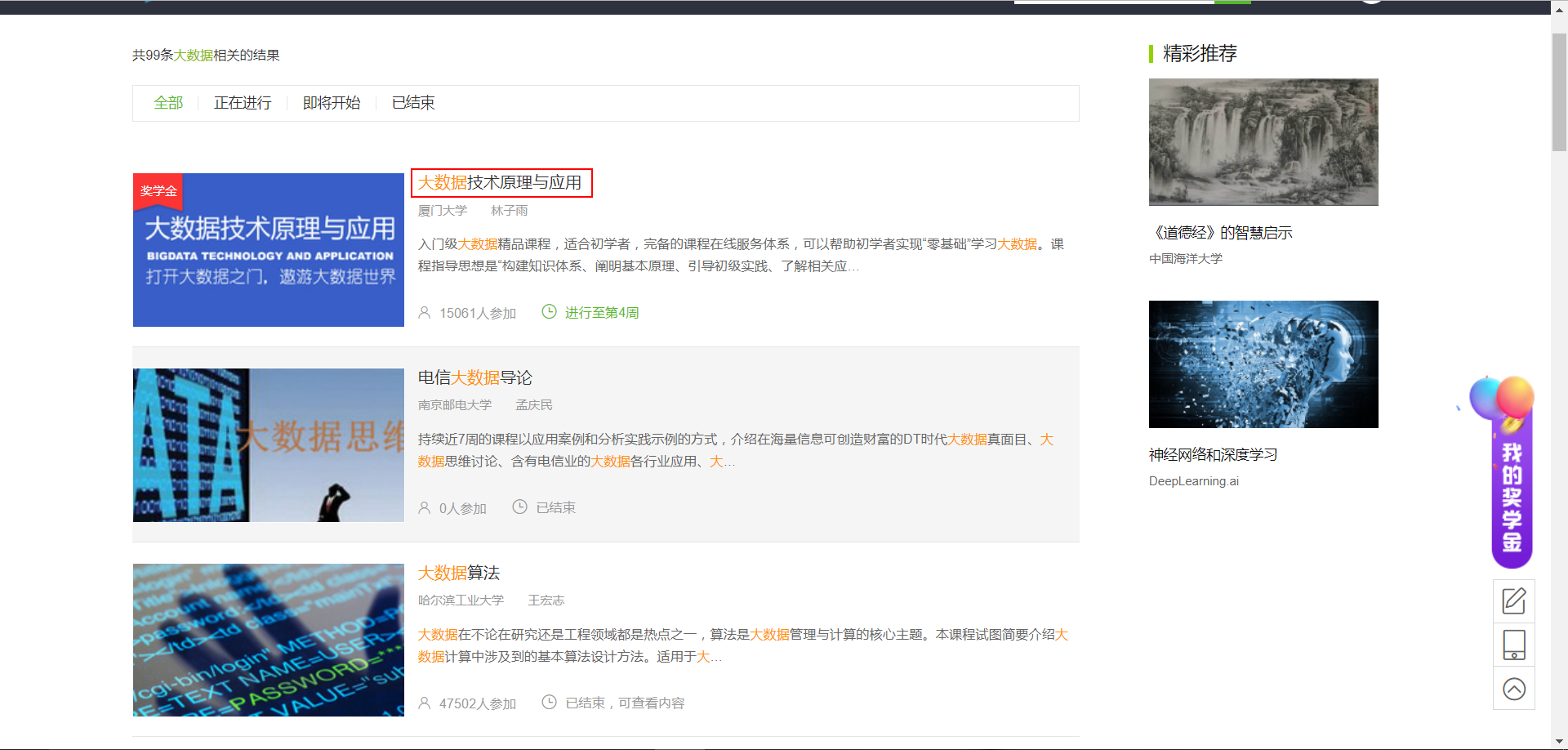
打开MOOC官网,在搜索框输入“大数据”关键词,发现返回了99条数据(当时的情况),也就是说,有99个关于大数据的课程。
但是,只有课程列表是不行的。就像爬取淘宝网站的时候,获取到了商品列表,还需要进入到商品的详情页面,然后抓取我们需要的信息。在这里,我们同样需要这样的方法。
但是,通过Google浏览器的检查功能可以发现,你几乎无法在课程页面获取什么东西——因为几乎都是动态变化的。我试图获取每个课程上面的超链接,然后进入到具体的详情页面,但是很显然直接使用requests方法是不行的。
后来经过同学指点发现此处需要通过post方法,获取到response,返回的response里面才具有我们需要的详情页面的信息(其实也就是每个课程的id,通过该id可以构造详情页面)
2. 代码设计
2.1 获取课程id
经过上面的分析,我首先找到了商品id存储的页面,如下图所示,我发现当我点击下一页的时候,会多出图中红色方框部分的网址,说明该网址是我请求的response,点击preview查看预览也印证了我的猜测。
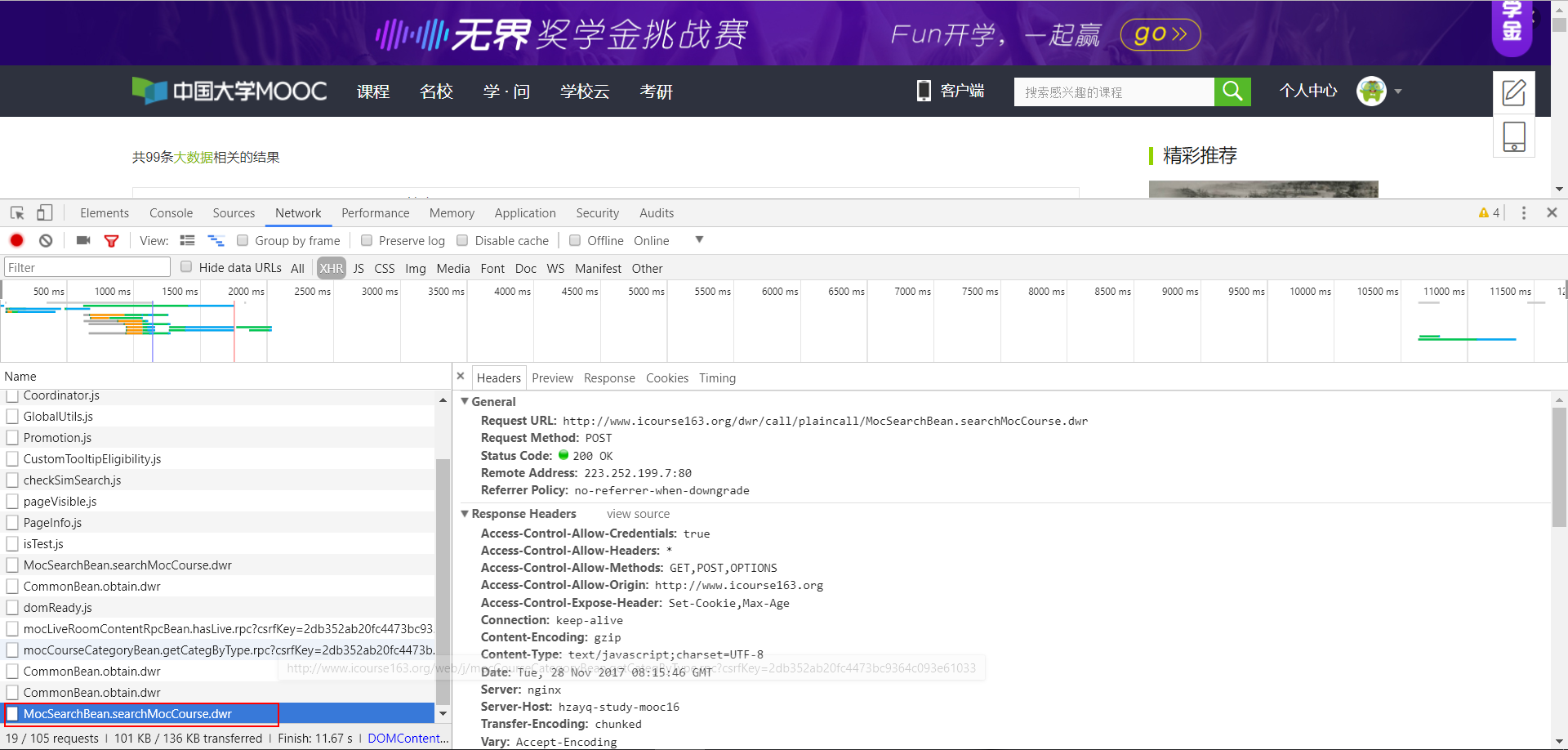
问题搞清楚了,下面使用requests包的post函数发送请求,然后分析获取到的response。
import requests
import urllib.parse as up
#准备进行搜索的关键词
keywords = ['大数据','机器学习','数据挖掘','数据科学','人工智能']
#转换成URL编码
def quote(x):
return up.quote(x)
#转换编码
keywords = list(map(quote,keywords))
#URL前缀
startUrl = "http://www.icourse163.org/search.htm?search="
#构造URL
urls = []
for kws in keywords:
urls.append(startUrl+kws)
#post的URL
jsurl = "http://www.icourse163.org/dwr/call/plaincall/MocSearchBean.searchMocCourse.dwr"
#请求头
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip,deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection":"keep-alive",
"Content-Length":"522",
"Content-Type":"text/plain",
"Host":"www.icourse163.org",
"Origin":"http://www.icourse163.org"
#Refere是我们查询的时候对应的URL,也需要根据不同的关键词进行调整
#"Referer":"http://www.icourse163.org/search.htm?search=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0"
}
#发送的数据
payload = {
"callCount":"1",
"scriptSessionId":"${scriptSessionId}190",
"httpSessionId":"907805e60a6540c4a268164e9e89ac4c",
"c0-scriptName":"MocSearchBean",
"c0-methodName":"searchMocCourse",
"c0-id":"0",
#c0-e1的string是我们查询的关键词,需要根据不同的关键词进行更改
#"c0-e1":"string:%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0",
#c0-e2的number表示获取的是第几页数据,需要动态变化
#"c0-e2":"number:1",
"c0-e3":"boolean:true",
"c0-e4":"null:null",
"c0-e5":"number:0",
"c0-e6":"number:30",
"c0-e7":"number:20",
"c0-param0":"Object_Object:{keyword:reference:c0-e1,pageIndex:reference:c0-e2,highlight:reference:c0-e3,categoryId:reference:c0-e4,orderBy:reference:c0-e5,stats:reference:c0-e6,pageSize:reference:c0-e7}",
"batchId":"1511830181483"
}
#构造一个空字典,用于存储课程列表中每一门课程的id
courses = {}
#分析response
for i in range(0,len(urls)):
headers["Referer"] = urls[i]
string = "string:" + keywords[i]
payload["c0-e1"] = string
for j in range(1,20): #大致查询了一下,课程数量不会超过20页
page = "number:" + str(j)
payload["c0-e2"] = page
#目前为止,上面请求的部分已经做完
response = requests.post(data=payload,url=jsurl,headers = headers)
courseid = re.findall(pattern=r'courseId=([0-9]{0,20})',string=response.text)
if(len(courseid) == 0):
break;
else:
kw = up.unquote(keywords[i])
if not kw in courses.keys():
courses[kw] = courseid
else:
courses[kw].extend(courseid)
2.2 获取详情
上面已经获取到了课程的id,我们只需要使用该id构造课程详情页的URL就行了。
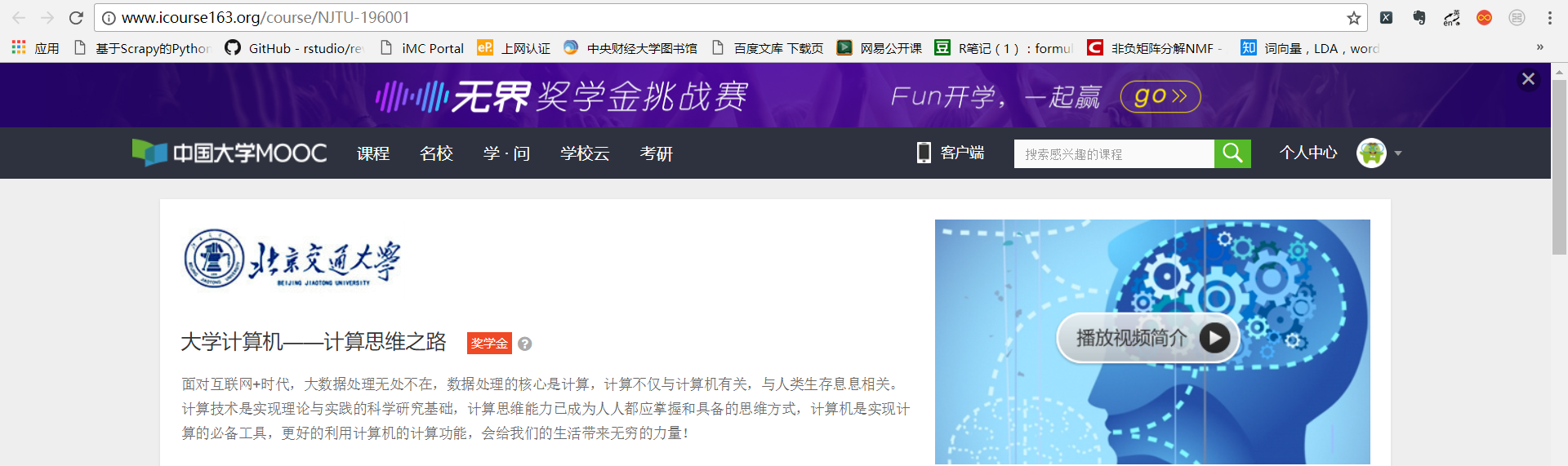
上图展示了课程详情页的URL信息,总结可以发现,前面的部分"http://www.icourse163.org/course/“ 都是一样的,只有后面的大学简称和id是变化的。而且大学简称可以使用任何非空值……利用上面的信息,构造好需要的URL,然后就可以使用selenium进行爬取了。
#使用无头浏览器phantomjs获取页面信息
browser = webdriver.PhantomJS('C:/phantomjs/bin/phantomjs.exe')
#data用来存储我们获取到的数据
data = None
data = pd.DataFrame({"course_name":"","start_times":"","lasting":"","start_date":"","end_date":"",
"rollnum":"","coursehrs":"","outline":"","key_word":""},index=["0"])
#data frame的行索引
index = 0
for k in courses.keys(): #k是键
for v in courses[k]: #v是值
#page是构造的课程详情页URL
page = "http://www.icourse163.org/course/ABC-" + str(v)
#get数据
browser.get(page)
#每个页面之间停顿3秒,否则有可能还没有渲染成功,获取不到数据
#这应该是一种隐式等待
time.sleep(3)
#info是我们需要的一系列信息,根据id(j-center)返回
info = browser.find_element_by_id('j-center').text
info = re.sub(re.compile("\n"),"",info)
info = re.sub(re.compile(r'[0-9]{2}:[0-9]{2}'),"",string=info)
#1.课程名称
course_name = browser.find_element_by_tag_name('h1').text
#2.第几次开课
start_times = re.search(pattern="第([0-9])次开课",string=info)
if not start_times is None:
start_times = start_times.group(1)
else:
start_times = "NA"
#3.持续时长
lasting = re.search(pattern="课程已进行至([0-9]{0,2}\/[0-9]{0,2})周",string=info)
if not lasting is None:
lasting = lasting.group(1)
else:
lasting = "NA"
#4.开始日期
start_date = re.search(pattern= r"开课:([0-9]{0,4}[年]{0,1}[0-9]{0,2}月[0-9]{0,2}日)",string=info)
if not start_date is None:
start_date = start_date.group(1)
else:
start_date = "NA"
#5.结束日期
end_date = re.search(pattern = r"结束:([0-9]{0,4}[年]{0,1}[0-9]{0,2}月[0-9]{0,2}日)",string=info)
if not end_date is None:
end_date = end_date.group(1)
else:
end_date = "NA"
#6.参与人数
rollnum = re.search(pattern = r"([0-9]{0,9})人参加",string = info)
if not rollnum is None:
rollnum = rollnum.group(1)
else:
rollnum = "NA"
#7.课程时长
coursehrs = re.search(pattern=r"课程时长(.*?)周",string=info)
if not coursehrs is None:
coursehrs = coursehrs.group(1)
else:
coursehrs = "NA"
#8.课程概述
outline = browser.find_element_by_id('j-rectxt2').text
if outline is None:
outline = "NA"
data.loc[index] = {"course_name":course_name,"start_times":start_times,"lasting":lasting,"start_date":start_date,
"end_date":end_date,"rollnum":rollnum,"coursehrs":coursehrs,"outline":outline,"key_word":k}
index = index + 1
print("已经获取第%d个课程数据!"%(index))
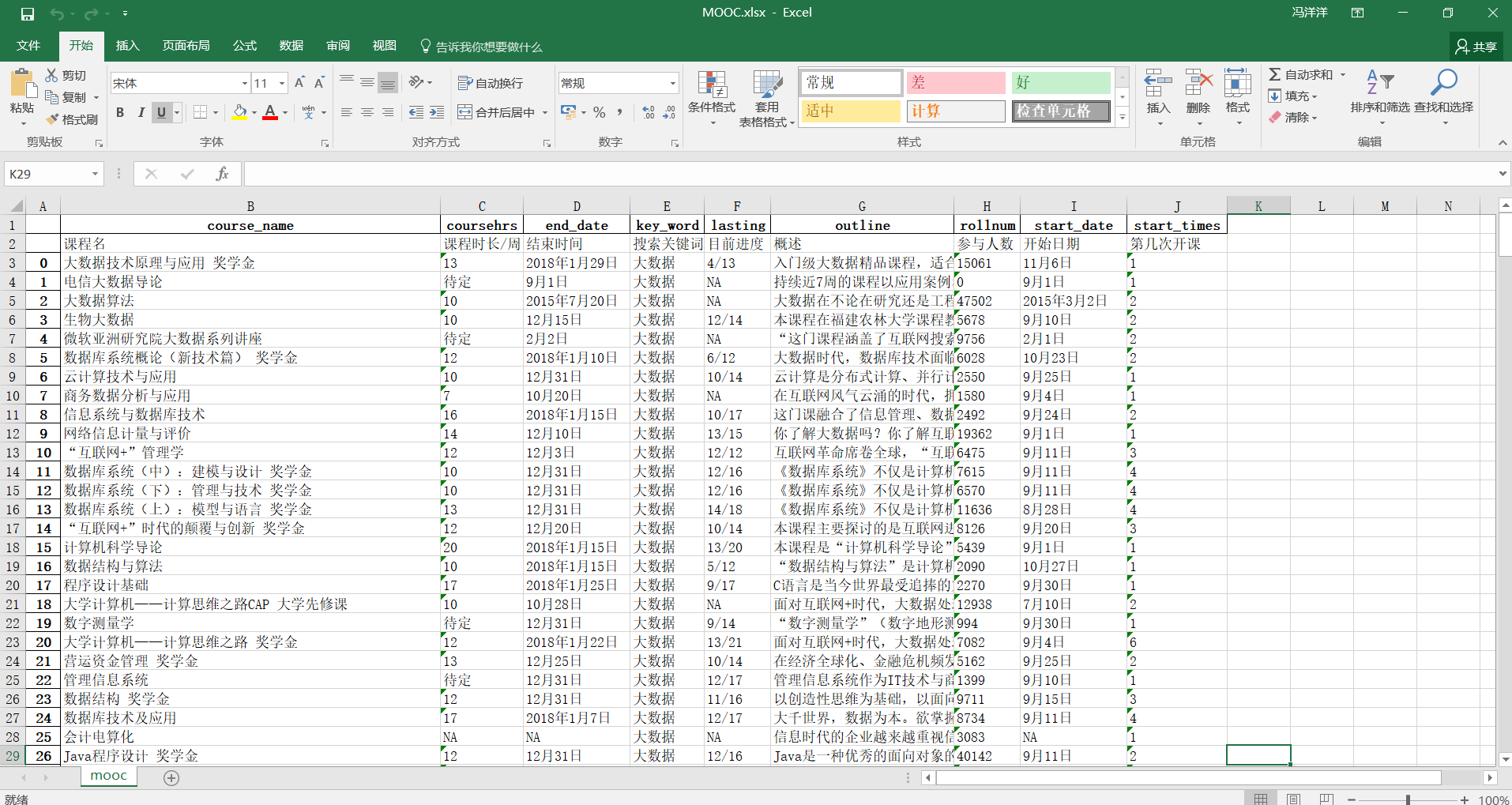
3. 结果展示
数据获取完毕以后,把存储在内存中的数据输出到Excel
from pandas import ExcelWriter
writer = ExcelWriter("MOOC.xlsx")
data.to_excel(writer,"mooc")
writer.save()
最终展示在Excel中的数据如下图: