R语言——一元线性回归
高尔顿被誉为现代回归的创始人,"回归效应"的发现源于高尔顿的豌豆遗传试验。在这个试验中,高尔顿发现,并非尺寸大的豌豆,其后代尺寸也大,尺寸小的豌豆,其后代尺寸也小。而是具有一种不同的趋势,即尺寸大的豌豆趋向于得到尺寸更小的子代,而尺寸小的豌豆趋向于得到尺寸更大的后代。高尔顿把这一现象称为"返祖",后来又称为"向平均值回归"。"回归效应"的应用非常广泛,生活中随处可见这样的例子。
1 变量之间的关系的度量
1.1变量间的关系
线性回归分析主要用于数值型数据之间的分析,因此要求所要分析的对象必须是数值型数据,即使不是数值型数据,也要想办法变成数值型数据,比如性别可以用0-1代替,成绩的优良中差可以用1-2-3-4表示等,当然这只是一种粗略的处理方法,当遇到分类型数据时,可以运用其他相应的方法处理,而不必非要使用线性回归。
变量之间往往具有两种关系,即确定的函数关系与不确定的相关关系。形如
 ,
,
则可以称为函数关系,这里y与x具有一一对应的关系,即x每取一个值,y有一个确定的值与之对应。而当x每取一个值时,y的值虽然不确定,但是总在一个确定的数的周围变动,则这种不确定的关系可以称之为相关关系。
1.2 相关分析
为了对变量之间的相关性进行描述与度量,提出了相关分析的概念。相关分析主要解决以下几个问题:
(1)变量之间是否存在关系?
(2)如果存在关系,是什么样的关系?
(3)关系强度如何?
(4)样本所表现的关系是否能够代表总体变量之间的关系?
在进行相关分析时,需要对总体做出如下两个假定:
(1)两个变量之间是线性关系
(2)两个变量都是随机变量
①利用散点图观察变量的关系





②相关系数的计算

按照上式计算出来的相关系数称为线性相关系数,也称为Pearson相关系数.
线性相关系数具有如下几个性质:
- r的取值范围在-1到1之间,且包含-1和1;
- r具有对称性,即
 ;
; - r的取值大小与原点和尺度无关;
- r仅仅是用来度量两个变量的线性关系强弱,不能用来度量非线性关系;
- 具有相关关系并不代表具有因果关系。
注:一般认为,因果关系是现象之间的引起与被引起的关系。引起一个现象的现象叫做原因,被一个现象引起的现象叫做结果。而同时变化并不意味着具有因果关系。比如,雷声和闪电往往同时出现,但是并不是雷声引起了闪电,也不是闪电引起了雷声,而是云层之间的摩擦发出的声音,并且形成了闪电。
一般来说,|r|>=0.8时,可视为高度相关;0.5<=|r|<0.8时,可视为中度相关;0.3<=|r|<0.5时,可视为低度相关;|r|<0.3时,认为不相关。
③相关关系的显著性检验
对相关系数进行显著性检验,往往假设r服从正态分布,因此,可以应用正态分布来检验。
第一步:提出假设。


第二步:计算检验统计量。

第三步:进行统计决策。
t的自由度为n-2,可查t分布表,如果|t|>|tα/2|,则可以拒绝原假设,认为两个变量之间存在显著地线性关系。
在R语言中,可以用cor.test()函数进行相关系数检验。
cor.test(x, y,
alternative = c("two.sided", "less", "greater"),
method = c("pearson", "kendall", "spearman"),
exact = NULL, conf.level = 0.95, continuity = FALSE, ...)
x,y:数值型向量或者数据框,x和y必须具有相同的长度
alternative:双边检验,左单侧检验还是右单侧检验
method:计算相关系数的方法
exact:逻辑值,是否计算精确的p值
conf.level:置信度或置信水平
有以下数据,展示的是某校研究生入学考试的初试分数、复试分数与总分,现在探究初试分数与复试分数的关系,看看是否具有相关性。
数据结构如下:
>#first代表初试分数,last代表复试分数,total代表总分
> str(score)
'data.frame': 47 obs. of 3 variables:
$ first: int 422 407 429 410 406 413 419 414 413 396 ...
$ last : num 91 91.3 88.2 90.7 91 ...
$ total: num 530 524 523 523 523 ...
> head(score)
first last total
1 422 90.96 530.0
2 407 91.30 524.0
3 429 88.20 523.4
4 410 90.70 523.3
5 406 91.04 522.6
6 413 90.08 522.5
>#对初试分数和复试分数进行相关分析:
> cor.test(score$first,score$last)
Pearson's product-moment correlation
data: score$first and score$last
t = 1.4536, df = 45, p-value = 0.153
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.08027284 0.47033893
sample estimates:
cor
0.2117758
>#从R的输出结果中可以看出,相关系数为0.21,相应的p值为0.153,由于p远大于常用的α=0.05,因此,无法拒绝原假设,认为初试分数与复试分数没有显著的相关性。
>#接下来探究初试分数与总分的关系。
> cor.test(score$first,score$total)
Pearson's product-moment correlation
data: score$first and score$total
t = 2.2898, df = 45, p-value = 0.02678
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.03954187 0.55840596
sample estimates:
cor
0.3230405
从上述结果可以看出,即使相关系数r只有0.323,但是p值=0.02678,小于常用的α=0.05,如果仅从p值的角度考虑,可认为初试分数与总分具有显著的相关性。
2 一元线性回归
回归分析与相关分析具有本质的区别,具体来说,回归分析主要解决以下几个问题:
- 从一组样本数据出发,确定变量之间的数学表达式;
- 对这些关系式的可信程度进行各种统计检验,并确定哪些变量的影响是显著的,哪些是不显著的;
- 利用所求的关系式,对目标变量进行预测。
2.1 一元线性回归模型
①回归模型

其中,y表示被预测的变量,即因变量,x表示预测变量,即自变量。 和
和 分别为模型的参数。
分别为模型的参数。 为随机误差项,表示不能被自变量与因变量之间的线性关系解释的部分。整个方程除去随机误差项,则反映了自变量与因变量之间的线性关系对因变量的影响。
为随机误差项,表示不能被自变量与因变量之间的线性关系解释的部分。整个方程除去随机误差项,则反映了自变量与因变量之间的线性关系对因变量的影响。
该模型具有几个假设条件:
- 因变量与自变量之间具有线性关系;
- 在重复抽样中,自变量x的取值是固定的,即自变量x非随机变量;
- 随机误差项
 服从同方差、0期望的正态分布。即
服从同方差、0期望的正态分布。即
②回归方程
根据回归模型中的假定, 的期望为0,则
的期望为0,则 。其中
。其中 表示回归直线在y轴上的截距,
表示回归直线在y轴上的截距,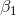 为直线的斜率。上述方程即为回归方程。
为直线的斜率。上述方程即为回归方程。
③估计的回归方程
由于 与
与 是未知的,也就是需要求的总体参数,这就需要用样本统计量去估计总体参数。因此,用样本统计量
是未知的,也就是需要求的总体参数,这就需要用样本统计量去估计总体参数。因此,用样本统计量 和
和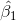 来代替总体参数所得的方程
来代替总体参数所得的方程 即为估计的回归方程。
即为估计的回归方程。
2.2 参数的最小二乘估计
假如给定一组样本,我们可以做无数条直线去近似表示自变量与因变量的关系,但是到底那一条直线是最优的?这就需要一个评价准则。也就是说,坐标上的各点 到直线的距离最近。德国数学家卡尔·高斯提出用最小化图中垂直方向的离差平方和来估计
到直线的距离最近。德国数学家卡尔·高斯提出用最小化图中垂直方向的离差平方和来估计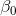 和
和 ,根据这一方法确定模型参数
,根据这一方法确定模型参数 和
和 的方法称为最小二乘法,它是通过使因变量的观测值
的方法称为最小二乘法,它是通过使因变量的观测值 与估计值
与估计值 之间的离差平方和达到最小来估计
之间的离差平方和达到最小来估计 和
和 的方法。
的方法。
根据最小二乘法,使

最小,令
 ,
,
在给定样本数据后,Q是 和
和 的函数,且最小值总是存在的。根据微积分的极值定理,对Q求相应于
的函数,且最小值总是存在的。根据微积分的极值定理,对Q求相应于 和
和 的偏导数,并令其等于0,便可求出
的偏导数,并令其等于0,便可求出 和
和 ,即
,即


解上述方程,可得:


由上式可知,直线过样本的中心,即 。
。
利用上述数据,对总成绩与初试成绩进行回归分析,在R中可求出相应的估计值。
> attach(score)
> lm.score<-lm(total~first,data = score)
> summary(lm.score)
Call:
lm(formula = total ~ first, data = score)
Residuals:
Min 1Q Median 3Q Max
-297.189 -5.145 7.302 18.209 31.911
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -26.0397 228.0289 -0.114 0.9096
first 1.3003 0.5679 2.290 0.0268 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 47.06 on 45 degrees of freedom
Multiple R-squared: 0.1044, Adjusted R-squared: 0.08445
F-statistic: 5.243 on 1 and 45 DF, p-value: 0.02678
在R中,可以用lm()函数对线性回归方程进行拟合,该函数返回的是一个回归对象。用summary()函数可以输出该对象的一些细节。
Call:公式
Residuals:残差
Coefficients:估计的回归系数、标准误、t值、p值以及R平方等统计量。
2.3 回归直线的拟合优度
①判定系数
在方差分析文章中,已经介绍过R平方的计算原理,这里回归直线的拟合优度与之类似,也用R平方来衡量。
记总平方和为SST,即
 ,
,
而每个观测点的离差可以分解为:
 ,可以证明,
,可以证明,

即
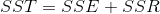
SSE表示除了x对y的线性影响之外的其他因素引起的误差,是不能被回归直线解释的变差部分,称为误差平方和。
SSR表示x对y的线性影响,是可以由回归直线解释的部分,称为回归平方和。
回归平方和占总平方和的比例,称为判定系数:

根据R平方,可以判断直线对数据的拟合程度。
同时,R平方与在数值上是相关系数r的平方,因此,假设即使r已经达到了0.5,但是R平方仅为0.25,不能说明拟合得很好。
②估计标准误差
估计标准误差是度量各实际观测点在直线周围散布状况的一个统计量,同时均方残差(MSE)的平方根,用Se来表示,其计算公式为:
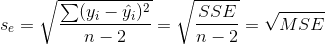 。
。
估计标准误差是对误差项的标准差 的估计,可以看做在排除了x对y的线性影响后,y随机波动大小的一个估计量。
的估计,可以看做在排除了x对y的线性影响后,y随机波动大小的一个估计量。
2.4 显著性检验
①线性关系检验
第一步:提出假设。


第二步:计算检验统计量F。

第三步:做出统计决策。
F服从第一自由度为1,第二自由度为n-2的F分布,查F分布表,若F大于Fα(1,n-2),则拒绝原假设,认为两个变量之间的线性关系是显著的。
②回归系数检验
第一步:提出假设。


第二步:计算检验统计量t。
 ,其中,
,其中, ,t服从自由度为n-2的t分布。
,t服从自由度为n-2的t分布。
第三步:进行统计决策。
若|t|>tα/2,则拒绝原假设。
在一元线性回归中,线性关系的检验与回归系数的检验等价。但在多元回归分析中,具有不同的意义。
下面给出几个结果的计算公式:
|
名称 |
计算公式 |
注释 |
|
调整的R平方 |
|
K为自变量的个数 |
|
截距的抽样标准误差 |
|
Se为标准误 |
|
截距的置信区间 |
|
|
|
斜率的置信区间 |
|




3 预测
预测是指通过自变量x的取值来预测因变量y的取值。
3.1 点估计
①个别值的点估计
对于一个给定的x0,求出y的一个个别值的估计值 。
。
②平均值的点估计
对于一个给定的值x0,求出y的平均值的一个估计值
3.2 区间估计
①置信区间估计
置信区间估计就是对x的一个给定值x0,求出y的平均值的区间估计。用 表示
表示 的标准差的估计量,其计算公式为
的标准差的估计量,其计算公式为
 ,
,
E(y0)在1-α的置信水平下的置信区间为:

②预测区间估计
预测区间估计是对x的一个给定值x0,求出y的一个个别值的区间估计。
y的一个个别值y0的标准差为 ,其计算公式为:
,其计算公式为:
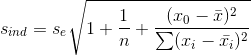
因此,对于给定的x0,y的一个个别值y0在1-α置信水平下的预测区间可表示为:

4 残差分析
确定有关ε的假定是否成立的方法之一就是进行残差分析。
4.1 残差图
残差图分为关于x的残差图、关于 的残差图、标准化残差图等。该例中,关于x的残差图如下:
的残差图、标准化残差图等。该例中,关于x的残差图如下:

发现除了一个点偏离比较严重意外,其他的点都较为均匀地分布在0周围。
4.2 标准化残差
标准化残差是残差除以它的标准差以后得到的数值。
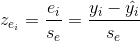 。
。

虽然标准化残差在0两侧均匀分布,但是似乎具有某种趋势,不一定满足随机误差项的假设。

