
手把手教你做一个天猫精灵(一)
如今,智能家居的话题越来越火,物联网已经融入了我们生活。最近闲在家里了解了一下这方面的背景知识,自己动手做了一个类似天猫精灵的物联网智能终端。于是打算出一个教程分享一下我的研究成果。
硬件准备
- 一台能连上网的电脑(系统最好是Windows 10)
背景知识
物联网智能终端
类似于天猫精灵这类产品我们都把它叫做智能终端(或者智能音箱)。它能通过用户之间的语音互动对智能家居进行命令控制,也能提供一些内置的软件服务,比如语音提醒和QQ音乐等。因此,我把它总结出以下几个功能模块。
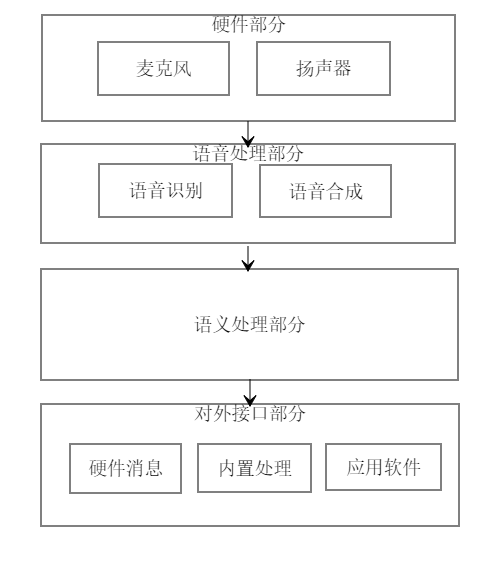
目前,市面上除了天猫精灵,还有百度小度、小米小爱、Google Home和比亚迪小迪等。
语音处理术语
智能终端运用了大量的语音处理方面的人工智能算法,这些算法可软件实现也可以硬件实现,主要包括语音识别(Automated Speech Recognition,ASR)、语音合成(Text To Speech,TTS)和语音唤醒(Keyword Spotting,KWS)。
一般的流程是这样的,先通过语音唤醒捕捉用户的Keyword,当捕捉到了才给用户录音并作语音识别,然后根据用户的意图调用相应的API并通过语音合成给用户适当的反馈。据我观察至少有三种API调用方式,或者说是对外调用的接口,总结如下:
- MQTT消息:智能终端操作硬件一般采用IBM定义的MQTT协议,这种消息协议类似
Kafka,但是它更适应网络环境不稳定的场景,比如多了服务质量(QoS)和遗言机制(Last Will),这部分内容以后介绍。 - 蓝牙接口:还有一种是通过蓝牙Mesh直接和硬件相连,不需要联网就能直接操作硬件。
- HTTP接口:这种接口一般是提供软件服务的,比如QQ音乐、墨迹天气和喜马拉雅广播
快速开始
考虑到可能会接入很多应用功能,所以本项目是通过Python开发的。新建一个工程,并设置好环境,然后下载这个包:
pip install fubuki-iot
提醒:如果下载不了可以换源,也可以在GitHub上下载,仓库地址点这里 。同时也欢迎PR。
然后创建一个程序入口,我把它命名为 app.py, 然后调用 Terminal 的 run函数,如下:
from iot import Terminal
if __name__ == '__main__':
Terminal.run()
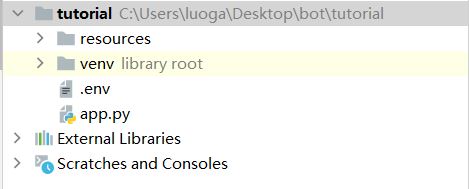
当然现在这个程序是跑不起来的,因为没有相应的配置。新建一个目录叫 resources ,然后再创建一个配置文件 .env ,注意前面有一个点。接着,把刚刚新建的 resource 文件的路径写到这个配置文件中,如下:
RESOURCE_PATH=你的resources的路径
这时候,你的项目目录应该是这样的:
原则上就可以运行了,但是像上文所说需要语音处理相关的能力,所以我先暂时借用了百度智能云的AI能力。这个平台可以免费提供半年的人工智能服务,所以先去申请以下相关服务。
进入百度智能云的官网,依次点击“产品”-“人工智能”-“语音技术”,然后申请这个AI服务。之后就可以在控制台中找到自己的API Key和Secret Key,如图所示:

然后在刚才的 .env文件中追加这两条信息,并预留一个BAIDU_ACCESS_TOKEN字段,如下所示:
BAIDU_API_KEY=你的API Key
BAIDU_SECRET_KEY=你的Secret Key
BAIDU_ACCESS_TOKEN=
提醒:由于百度API是要生成access token使用的,这个token是有时效的,所以这里预留可以方便以后不用重复申请,但是过了时效还是要把这个字段置空,就像现在这个样子。
当然,百度API试用结束后还是会收费,如果你不想收费可以自己训练模型来替代它,这个以后会介绍。
现在就可以运行这个程序了。运行结果如图所示:
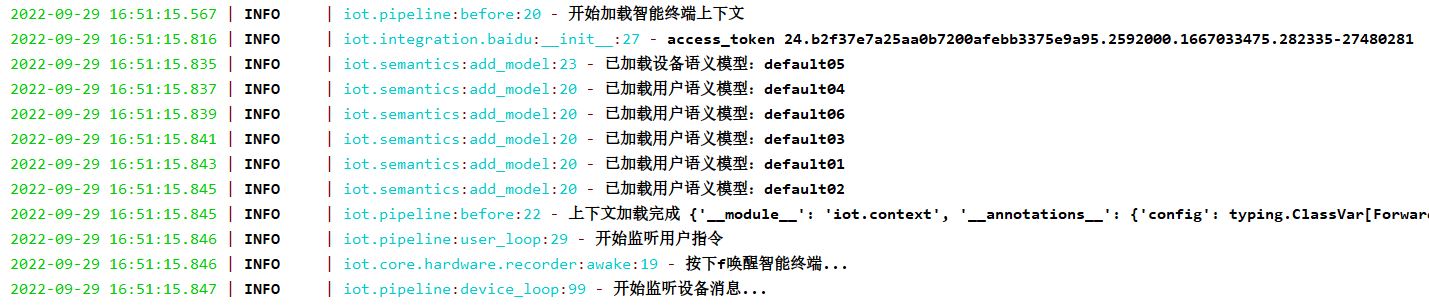
按下“F”键就可以唤醒终端,它会回应“我在,你说”。然后等它开始录音就可以说“你好”,它会回应“在的”。至此,一个极简的智能终端就做好了。
开启语音唤醒
虽然智能终端的样子已经有了,但是距离天猫精灵还差远了。现在,就让我们开启它的语音唤醒功能。
这个终端内置了一个PocketSphinx的语音唤醒功能。这个工具是C写的,因此要在Windows环境下需要对应的编译器,官方推荐的是Visual C++。
首先点这里下载Visual Studio Installer,然后安装,接着打开以后选择安装“单个组件”,然后勾选这三个组件“Windows 10 SDK”、“Windows 通用 CRT SDK”以及“MSVC v140 - VS 2015 C++ 生成工具(v14.00)”,下载完即可。这个环境变量无需配置。

注意:有可能碰到“无法打开包括文件: “windows.h”: No such file or directory”的问题,这个需要将
<windows.h>头文件放在指定目录,具体自行百度或者谷歌。
然后下载swigwin,这个软件是让python调用C/C++编译的软件的,点这里下载,下载完成后解压,并配置环境变量,然后重启生效。
最后,安装PocketSphinx。
pip install pocketsphinx
如果没有报错就说明成功了,有报错可能和C语言环境有关,这个需要具体问题具体分析了。
然后在 .env 文件中追加两行配置:
TERMINAL_MODE=0
DEVICE_REC=PocketsphinxRecorder
接着启动程序可以通过对他说“hello”或者“hi”唤醒它。
编写第一个程序
接下来,我们要开始向终端里面添加功能。类似天猫精灵的定时提醒功能,我们也做一个提醒功能。
首先创建一个包,命名为 mods,我们接下来写的模组都将放在这个包里。新建一个文件命名为timer.py,然后在文件里新建一个语义模型,这个模型继承了SemanticsModel,其目的是为了匹配用户的命令,如下所示:
@SemanticsGroup.add_model
class TimerSemanticsModel(SemanticsModel):
code = 'timer'
frm = SemanticsFromEnum.USER
topic = ''
regex = '(.*)后提醒我(.*)'
regex_num = 3
redirect = SemanticsRedirectEnum.ACOUSTICS
func: SemanticsFunc = timer_semantics_func
字段说明如下:
- code:语义模型的标识,这里随便填,只用来区分。
- frm:语义来源,这里是用户
- topic:因为来自用户,所以这里不需要填
- regex:正则表达式,用来匹配用户的命令,如果匹配命中则使用这个语义模型,否则继续匹配下一个语义模型,如果都没有命中则发送兜底的语音回应用户
- regex_num:上面正则表达式的
groups()个数,至少为1,表示全量,具体参考Python正则表达式相关文档,这个是用来抽取参数的 - redirect:重定向,这里不需要处理硬件,只是返回语音,所以是
ACOUSTICS - func:用来处理这个命令的回调函数
重点就在这个回调函数,它是处理语义的关键。在当前环境下,它接受一个列表,即正则表达式匹配的groups,我们可以通过数组下标拿到想要的参数,并作后续处理。比如:
def timer_semantics_func(*args) -> FunctionDeviceModel:
sentence = args[0] # 获取全文
timespan: str = args[1] # 第一个参数,时间
content = args[2] # 第二个参数,内容
...
此外它返回一个功能设备模型FunctionDeviceModel,它告知终端要如何处理,即如何返回给用户信息。其字段如下。
class FunctionDeviceModel(BaseModel):
"""
功能设备模型,既是用户发送指令的封装,也是语义转换模块处理后的产物。
"""
# 对应的semantics_model的code
smt_code: Optional[str]
# raw标志位,如果为True则data为str,否则为dict
is_raw: bool
# 执行成功后返回的语音提示,如果重定向到MESSAGE则作为语音提示,
# 如果是重定向到ACOUSTICS则也可以表示返回内容
acoustics: str
# 数据,只有当is_raw为False才为字典,用于展示详细内容
data: Union[str, Dict[str, str]]
因此,做一个提醒功能就是判断用户的语句是否正确,如果正确则返回正确的语音信息,否则告诉用户听不懂,具体如下:
def timer_semantics_func(*args) -> FunctionDeviceModel:
...
if not is_ok:
return FunctionDeviceModel(
smt_code='timer',
is_raw=True,
acoustics="抱歉我没听清",
data=""
)
else:
scheduler.start()
return FunctionDeviceModel(
smt_code='timer',
is_raw=True,
acoustics=f"好的,我会在{timespan}后提醒你{content}",
data=""
)
有正确的处理和返回还不够,还需要在时间到了的时候给用户语音提醒,这实现也很简单,只要从Context中获取相应的API就可以了,具体如下:
path = Context.tts_processor.tts("您好,时间到了,请" + content)
Context.player.play(path)
实现定时的方案有很多种,我采用了APScheduler实现了这个功能,下面仅供参考:
def ch2i(ch: str):
try:
# 尝试直接转换
return int(ch)
except Exception:
pass
_dict = {
"一": 1,
"二": 2,
"三": 3,
"四": 4,
"五": 5,
"六": 6,
"七": 7,
"八": 8,
"九": 9,
"十": 10,
"百": 100
}
if ch.startswith("十") or ch.startswith("百"):
ch = "一" + ch
_buf = list()
_res = 0
for i in range(len(ch)):
if len(_buf) == 0:
_buf.append(_dict[ch[i]])
else:
_res += _buf.pop() * _dict[ch[i]]
return _res + (_buf[0] if len(_buf) else 0)
def timer_semantics_func(*args) -> FunctionDeviceModel:
sentence = args[0] # 获取全文
timespan: str = args[1] # 获取时间
content = args[2] # 获取内容
is_ok = True
scheduler = BackgroundScheduler()
def _job():
path = Context.tts_processor.tts("您好,时间到了,请" + content)
Context.player.play(path)
try:
if timespan.endswith("秒"):
target = ch2i(timespan.split("秒")[0])
scheduler.add_job(_job, 'date', run_date=datetime.datetime.now() + datetime.timedelta(seconds=target))
elif timespan.endswith("分钟"):
target = ch2i(timespan.split("分钟")[0])
scheduler.add_job(_job, 'date', run_date=datetime.datetime.now() + datetime.timedelta(minutes=target))
elif timespan.endswith("小时"):
target = ch2i(timespan.split("小时")[0])
scheduler.add_job(_job, 'date', run_date=datetime.datetime.now() + datetime.timedelta(hours=target))
else:
# 只处理到小时,更大的单位不处理了
raise RuntimeError("Fail to match")
except Exception as e:
logger.error("Fail to translate " + e.__str__())
is_ok = False
if not is_ok:
return FunctionDeviceModel(
smt_code='timer',
is_raw=True,
acoustics="抱歉我没听清",
data=""
)
else:
scheduler.start()
return FunctionDeviceModel(
smt_code='timer',
is_raw=True,
acoustics=f"好的,我会在{timespan}后提醒你{content}",
data=""
)
@SemanticsGroup.add_model
class TimerSemanticsModel(SemanticsModel):
code = 'timer'
frm = SemanticsFromEnum.USER
topic = ''
regex = '(.*)后提醒我(.*)'
regex_num = 3
redirect = SemanticsRedirectEnum.ACOUSTICS
func: SemanticsFunc = timer_semantics_func
最后,在程序入口处加载这个包:
from iot import Terminal
Terminal.load_models('mods.timer')
if __name__ == '__main__':
Terminal.run()
现在,再启动程序,对它说“五分钟后提醒我打扫卫生”它就会回应,并在五分钟后通过语音播报提醒我们。
本章初步介绍了物联网领域的相关概念,然后跑通了一个简单的智能终端的程序。下一章我们会进一步完善这个程序,并把它做成硬件,离我们的目标更近一步!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号