Python 爬虫练手项目—酒店信息爬取
from bs4 import BeautifulSoup
import requests
import time
import re
url = 'http://search.qyer.com/hotel/89580_4.html'
urls = ['http://search.qyer.com/hotel/89580_{}.html'.format(str(i)) for i in range(1,10)] # 最多157页
infos = []
# print(urls)
# 批量爬取数据
def getAUrl(urls):
data_number = 0
for url in urls:
getAttractions(url)
print('--------------{}-----------------'.format(len(infos)),sep='\n')
# 爬取当页面数据
def getAttractions(url,data = None):
web_data = requests.get(url)
time.sleep(2)
soup = BeautifulSoup(web_data.text,'lxml')
# print(soup)
hotel_names = soup.select('ul.shHotelList.clearfix > li > h2 > a')
hotel_images = soup.select('span[class="pic"] > a > img')
hotel_points = soup.select('span[class="points"]')
hotel_introduces = soup.select('p[class="comment"]')
hotel_prices = soup.select('p[class="seemore"] > span > em')
if data == None:
for name,image,point,introduce,price in \
zip(hotel_names,hotel_images,hotel_points,hotel_introduces,hotel_prices):
data = {
'name':name.get_text().replace('\r\n','').strip(),
'image':image.get('src'),
'point':re.findall(r'-?\d+\.?\d*e?-?\d*?', point.get_text())[0],
'introduce':introduce.get_text().replace('\r\n','').strip(),
'price':int(price.get_text())
}
# print(data)
infos.append(data)
# 根据价格从高到低进行排序
def getInfosByPrice(infos = infos):
infos = sorted(infos, key=lambda info: info['price'], reverse=True)
for info in infos:
print(info['price'], info['name'])
# getAttractions(url)
爬取的网站链接
遇到的问题及解决办法
1.【转载】Python: 去掉字符串开头、结尾或者中间不想要的字符
①Strip()方法用于删除开始或结尾的字符。lstrip()|rstirp()分别从左右执行删除操作。默认情况下会删除空白或者换行符,也可以指定其他字符。
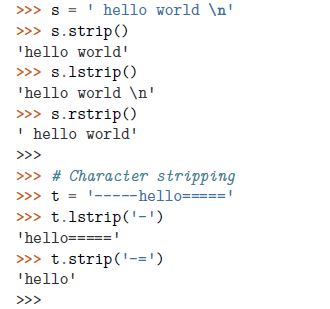
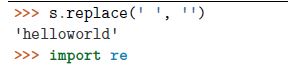
②如果想处理中间的空格,需要求助其他技术 ,比如replace(),或者正则表达式

③strip()和其他迭代结合,从文件中读取多行数据,使用生成器表达式

④更高阶的strip
可能需要使用translate()方法
2. 【转载】Python:object of type 'Response' has no len(),如何解决?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号