

嵌入式操作系统VxWorks中网络协议存储池原理及实现
嵌入式操作系统VxWorks中网络协议存储池原理及实现
周卫东 蔺妍 刘利强
(哈尔滨工程大学自动化学院,黑龙江 哈尔滨,150001)
摘 要 本文讨论了网络协议存储池的基本原理和在嵌入式操作系统中的实现方法。为在嵌入式系统中实现TCP/IP协议栈,提供了一种有效、简洁、可靠的缓冲区管理。
关键词 VxWorks; mBlk; clBlk; 网络协议存储池
VxWorks操作系统是美国WindRiver公司于1983年设计开发的一种嵌入式实时操作系统(RTOS)。它以良好的持续发展能力、高性能的内核以及卓越的实时性被广泛的应用在通信、军事、航空、航天等高精尖技术及实时性要求极高的领域中。VxWorks操作系统有着优越的网络性能,而缓冲区的数据拷贝是影响网络性能的主要因素。
众所周知,缓冲区在网络协议栈中有两个作用:第一,提供载体,使分组或报文可以在各协议层中流动;第二,为各级缓冲区提供空间。缓冲区的设立使得TCP/IP协议栈支持异步I/O操作,异步操作对于协议栈的I/O性能是非常重要的。在网络输出的过程中每一层需要在数据的首部或者尾部添加数据头和数据尾来对数据进行封装使得接收端对应的层能够进行正确的接收,在输入的过程中每层都需要将本层的数据头和数据尾去掉而最终还原成发送端发送的数据。上述的封装/去封装和拷贝操作使得网络协议对内核的存储器管理能力提出了很多要求。这些要求包括能方便地操作可变长缓存,能在缓存头部和尾部添加数据(如低层封装来自高层的数据),能从缓存中移去数据(如当数据包向上经过协议栈时要去掉首部),并能尽量减少这些操作所作的数据复制。
1 使用netBufLib管理存储池的基本原理
网络协议存储池使用mBlk结构、clBlk结构、簇缓冲区和netBufLib提供的函数进行组织和管理。mBlk和clBlk结构为簇缓冲区(cluster)中数据的缓冲共享和缓冲链接提供必要的信息。netBufLib例程使用mBlk和clBlk来管理cluster和引用cluster中的数据,这些结构体中的信息用于管理cluster中的数据并且允许他们通过引用的形式来实现数据共享,从而达到数据“零拷贝”(zero copy)的目的。
1.1 结构体mBlk和clBlk及其数据结构
mBlk是访问存储在内存池中数据的最基本对象,由于mBlk仅仅只是通过clBlk来引用数据,这使得网络层在交换数据时就可以避免数据复制。只需把一个mBlk连到相应mBlk链上就可以存储和交换任意多的数据。一个mBlk结构体包括两个成员变量mNext和mNextPkt,由它们来组成纵横两个链表:mNext来组成横的链表,这个链表中的所有结点构成一个包(packet);mNextPkt来组成纵的链表,这个链表中的每个结点就是一个包 (packet),所有的结点链在一起构成一个包队列,如图1所示。
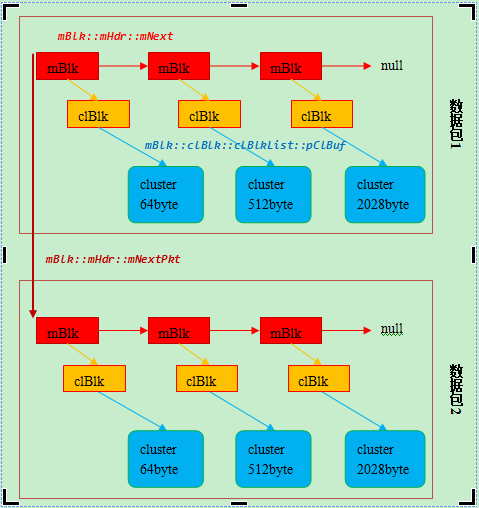
图1 包含两个数据包的mBlk链
结构体mBlk和clBlk的数据结构如下所示:
structmBlk
{
M_BLK_HDR mBlkHdr; /*header */
M_PKT_HDR mBlkPktHdr; /* pkthdr */
CL_BLK* pClBlk; /*pointer to cluster blk */
}M_BLK;
structclBlk
{
CL_BLK_LIST clNode; /* union of next clBlk */
UINT clSize; /* cluster size*/
Int clRefCnt; /* countof thecluster */
struct netPool* pNetPool; /* pointer to the netPool */
}CL_BLK;
/* header at beginning of each mBlk */
structmHdr
{
struct mBlk* mNext; /* next buffer in chain */
struct mBlk* mNextPkt; /* next chain in queue/record */
char* mData; /* location ofdata */
int mLen; /* amount ofdata in this mBlk */
UCHAR mType; /* type of datain this mBlk */
UCHAR mFlags; /* flags; seebelow */
} M_BLK_HDR;
/* record/packet header in first mBlk of chain; valid if M_PKTHDR set */
structpktHdr
{
struct ifnet* rcvif; /* rcv interface */
int len; /* total packet length */
}M_PKT_HDR;
typedefstruct clDesc
{
int clSize; /*cluster type*/
int clNum; /*number of clusters*/
char* memArea; /*pre allocatedmemory area*/
int memSize; /*pre allocatedmemory size*/
}CL_DESC;
typedefstruct m_cl_config
{
int mBlkNum; /*number of mBlks*/
int clBlkNum; /*number of clBlks*/
char* memArea; /*pre allocatedmemory area*/
int memSize; /*pre allocatedmemory size*/
}M_CL_CONFIG;
1.2 网络协议存储池的初始化
VxWorks在网络初始化时给网络协议分配存储池并调用netPoolInit(NET_POOL_ID, M_CL_CONFIG*,CL_DESC*)函数对其初始化,由于一个网络协议通常需要不同大小的簇,因此它的存储池也必须包含很多簇池(每一个簇池对应一个大小的簇)。如图2所示。另外,每个簇的大小必须为2的方幂,最大可为64KB(65536),存储池的常用簇的大小为64,128,256,512,1024比特,簇的大小是否有效取决于CL_DESC表中的相关内容,CL_DESC表是由netPoolInit()函数调用设定的。
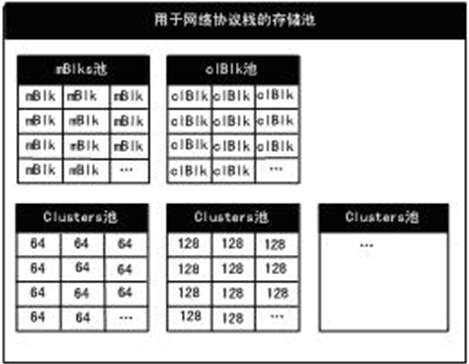
图2 网络协议存储池初始化后的结构
1.3 存储池的链接及释放
存储池在初始化后,由netPool结构组织几个下一级子池:一个mBlk池、一个clBlk池和一个cluster池。mBlk池就是由很多mBlk组成的一条mBlk链;clBlk池就是由很多clBlk组成的一条clBlk链。cluster池由很多的更下一级cluster子池构成,每一个cluster子池就是一个cluster链。每一个cluster链中的所有cluster的大小相同,不同链中的cluster大小不同。但要实现不同进程访问同一簇而不需要作数据的拷贝,还需要把mBlk结构,clBlk结构和簇结构链接在一起。创建这三级结构一般要遵循这样五步:
a.调用系统函数netClusterGet()预定一块簇缓冲区;
b.调用系统函数netClBlkGet()预定一个clBlk结构;
c.调用系统函数netMblkGet()预定一个mBlk结构;
d.调用系统函数netClBlkJoin()把簇添加到clBlk结构中;
e.调用系统函数netMblkClJoin()把clBlk结构添加到mBlk结构中。
这样,就构成了最后的缓冲区。
在缓冲区中的数据使用完毕后要及时的释放内存,这一过程只需要调用系统函数netMblkClChainFree()释放存有数据的mBlk链表。例如当数据向上层传送时,在本层中可以释放已经不再使用的mBlk链表,由于在clBlk中记录着指向本模块的mBlk的个数,虽然释放了mBlk链表,但是这并不表示将cluster中的数据释放掉了,上层复制的链表仍然控制着这些数据,直到clBlk中的mBlk计数为0时才真正的将数据占用的簇释放掉,将数据占用的内存空间释放、归还给系统将来使用。
2 网络协议存储池与数据的封装处理
VxWorks操作系统之所以采用mBlk—clBlk—cluster这样的网络数据存储结构,目的就是减少数据拷贝的次数,提高网络数据的传输速率。
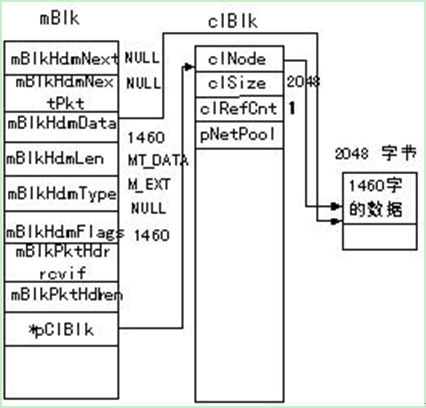
图3 存储带有1460个字节数据的mBlk
在网络输出的过程中当从上层向下层传递数据时,下层协议需要对数据进行封装使得接收端对应的层能够进行正确的接收。下面通过实例分析网络数据的封装过程。例如要在如图3所示的mBlk链中添加IP和UDP的首部。
在mBlk链表中封装数据的方法是分配另外一个mBlk,把它放在链首,并将分组首部复制到这个mBlk。IP首部和UDP首部被放置在新mBlk的最 后,这个新mBlk就成了整个链表的首部。如果需要,它允许任何其它低层协议(例如添加以太网首部)在IP首部前添加自己的首部,不需要再复制IP和UDP首部。在第一个mBlk中的mBlkHdr.mData指针指向首部的起始位置,mBlkHdr.mLen的值是28。在分组首部和IP首部之间有72字节的未用空间留给以后的首部,通过适当地修改mBlkHdr.mData指针和mBlkHdr.mLen添加在IP首部的前面。注意,分组首部已经移到新mBlk中了,分组首部必须放在mBlk链表的第一个mBlk中。在移动分组首部的同时,在第一个mBlk设置mFlags为M_PKTHDR,设置mType为MT_HEADER。在第二个mBlk中分组首部占用的空间现在未用, 设置mFlags为M_EXT,设置mType为MT_DATA。最后,改变在此分组首部中的长度成员mBlkPktHdr.len,成员mBlkPktHdr.len的值是这个分组的mBlk链表中所有数据的总长度:即所有通过mBlkHdr.mNext指针链接的mbuf的mBlkHdr.mLen值的和。本例中由于增加了28个字节变成了1488。如图4所示。
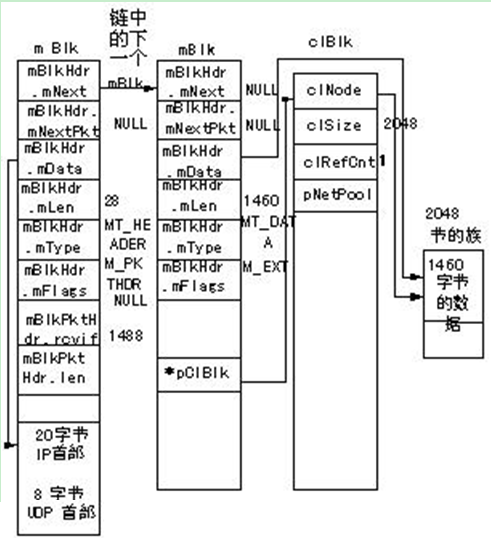
图4 添加完IP和UDP首部的mBlk
这样,当报文在协议栈中流动时,不会拷贝报文链,而只需把指向mBlk的指针通过参数传递。当报文需要进人缓冲区时,也是通过链表的指针操作将报文插入或添加到队列中。
3 结论
网络协议存储池的职责有两个:为协议栈提供合适的缓冲区,如果太大会浪费系统资源,太小会影响协议栈的吞吐量;提供合适的数据结构装载网络报文,既可以使协议栈方便地处理报文,又可以减少缓冲区拷贝的次数。减少拷贝次数不仅降低了CPU的负荷,还可以降低存储器的消耗。本文剖析了嵌入式操作系统 VxWorks中网络协议存储池的原理,实现了数据能够动态增删、但在逻辑上又呈现连续性的数据结构。能够满足在各协议层之间传递数据而不需要进行内存拷贝。
参考文献
[1] 翟东海,李力.mbuf的实现原理剖析及其在网络编程中的应用[J].计算机工程与应,2004(8):104-106.
[2] [美]DouglasE.Comer著.张娟等译.用TCP/IP进行网际互联第二卷:设计、实现与内核(第三版)[M].北京:电子工业出版社,2001.05.
[3] [美]GaryR.Wright W.RichardStevens著.陆雪莹,蒋慧等译.TCP/IP详解卷2:实现[M].北京:机械工业出版社.2000.07:10—50.
[4] Wind River System Inc.VxWorksNetwork
收稿日期:8月25日 修改日期:9月2日
posted on 2015-07-23 11:06 littleKing163 阅读(622) 评论(0) 编辑 收藏 举报

