Flink/Spark 如何实现动态更新作业配置
Flink/Spark 如何实现动态更新作业配置
由于实时场景对可用性十分敏感,实时作业通常需要避免频繁重启,因此动态加载作业配置(变量)是实时计算里十分常见的需求,比如通常复杂事件处理 (CEP) 的规则或者在线机器学习的模型。尽管常见,实现起来却并没有那么简单,其中最难点在于如何确保节点状态在变更期间的一致性。目前来说一般有两种实现方式:
- 轮询拉取方式,即作业算子定时检测在外部系统的配置是否有变更,若有则同步配置。
- 控制流方式,即作业除了用于计算的一个或多个普通数据流以外,还有提供一个用于改变作业算子状态的元数据流,也就是控制流。
轮询拉取方式基于 pull 模式,一般实现是用户在 Stateful 算子(比如 RichMap)里实现后台线程定时从外部系统同步变量。这种方式对于一般作业或许足够,但存在两个缺点分别限制了作业的实时性和准确性的进一步提高:首先,轮询总是有一定的延迟,因此变量的变更不能第一时间生效;其次,这种方式依赖于节点本地时间来进行校准。如果在同一时间有的节点已经检测到变更并更新状态,而有的节点还没有检测到或者还未更新,就会造成短时间内的不一致。
控制流方式基于 push 模式,变更的检测和节点更新的一致性都由计算框架负责,从用户视角看只需要定义如何更新算子状态并负责将控制事件丢入控制流,后续工作计算框架会自动处理。控制流不同于其他普通数据流的地方在于控制流是以广播形式流动的,否则在有 Keyby 或者 rebalance 等提高并行度分流的算子的情况下就无法将控制事件传达给所有的算子。
以目前最流行的两个实时计算框架 Spark Streaming 和 Flink 来说,前者是以类似轮询的方式来实现实时作业的更新,而后者则是基于控制流的方式。
Spark Streaming Broadcast Variable
Spark Streaming 为用户提供了 Broadcast Varialbe,可以用于节点算子状态的初始化和后续更新。Broacast Variable 是一组只读的变量,它在作业初始化时由 Spark Driver 生成并广播到每个 Executor 节点,随后该节点的 Task 可以复用同一份变量。
Broadcast Variable 的设计初衷是为了避免大文件,比如 NLP 常用的分词词典,随序列化后的作业对象一起分发,造成重复分发的网络资源浪费和启动时间延长。这类文件的更新频率是相对低的,扮演的角色类似于只读缓存,通过设置 TTL 来定时更新,缓存过期之后 Executor 节点会重新向 Driver 请求最新的变量。
Broadcast Variable 并不是从设计理念上就支持低延迟的作业状态更新,因此用户想出了不少 Hack 的方法,其中最为常见的方式是:一方面在 Driver 实现后台线程不断更新 Broadcast Variavle,另一方面在作业运行时通过显式地删除 Broadcast Variable 来迫使 Executor 重新从 Driver 拉取最新的 Broadcast Variable。这个过程会发生在两个 micro batch 计算之间,以确保每个 micro batch 计算过程中状态是一致的。
比起用户在算子内访问外部系统实现更新变量,这种方式的优点在于一致性更有保证。因为 Broadcast Variable 是统一由 Driver 更新并推到 Executor 的,这就保证不同节点的更新时间是一致的。然而相对地,缺点是会给 Driver 带来比较大的负担,因为需要不断分发全量的 Broadcast Variable (试想下一个巨大的 Map,每次只会更新少数 Entry,却要整个 Map 重新分发)。在 Spark 2.0 版本以后,Broadcast Variable 的分发已经从 Driver 单点改为基于 BitTorrent 的 P2P 分发,这一定程度上缓解了随着集群规模提升 Driver 分发变量的压力,但我个人对这种方式能支持到多大规模的部署还是持怀疑态度。另外一点是重新分发 Broadcast Variable 需要阻塞作业进行,这也会使作业的吞吐量和延迟受到比较大的影响。
Flink Broadcast State & Stream
Broadcast Stream 是 Flink 1.5.0 发布的新特性,基于控制流的方式实现了实时作业的状态更新。Broadcast Stream 的创建方式与普通数据流相同,例如从 Kafka Topic 读取,特别之处在于它承载的是控制事件流,会以广播形式将数据发给下游算子的每个实例。Broadcast Stream 需要在作业拓扑的某个节点和普通数据流 (Main Stream) join 到一起。
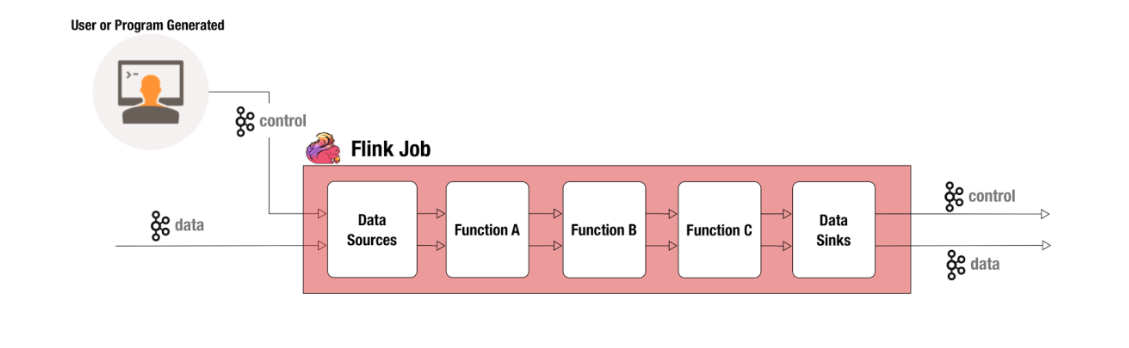
该节点的算子需要同时处理普通数据流和控制流:一方面它需要读取控制流以更新本地状态 (Broadcast State),另外一方面需要读取 Main Stream 并根据 Broadcast State 来进行数据转换。由于每个算子实例读到的控制流都是相同的,它们生成的 Broadcast State 也是相同的,从而达到通过控制消息来更新所有算子实例的效果。
目前 Flink 的 Broadcast Stream 从效果上实现了控制流的作业状态更新,不过在编程模型上有点和一般直觉不同。原因主要在于 Flink 对控制流的处理方式和普通数据流保持了一致,最为明显的一点是控制流除了改变本地 State 还可以产生 output,这很大程度上影响了 Broadcast Stream 的使用方式。Broadcast Stream 的使用方式与普通的 DataStream 差别比较大,即需要和 DataStream 连接成为 BroadcastConnectedStream 后,再通过特殊的 BroadcastProcessFunction 来处理,而 BroadcastProcessFunction 目前只支持 类似于 RichCoFlatMap 效果的操作。RichCoFlatMap 可以间接实现对 Main Stream 的 Map 转换(返回一只有一个元素的集合)和 Filter 转换(返回空集合),但无法实现 Window 类计算。这意味着如果用户希望改变 Window 算子的状态,那么需要将状态管理提前到上游的 BroadcastProcessFunction,然后再通过 BroadcastProcessFunction 的输出来将影响下游 Window 算子的行为。
总结
实时作业运行时动态加载变量可以令大大提升实时作业的灵活性和适应更多应用场景,目前无论是 Flink 还是 Spark Streaming 对动态加载变量的支持都不是特别完美。Spark Streaming 受限于 Micro Batch 的计算模型(虽然现在 2.3 版本引入 Continuous Streaming 来支持流式处理,但离成熟还需要一定时间),将作业变量作为一致性和实时性要求相对低的节点本地缓存,并不支持低延迟地、低成本地更新作业变量。Flink 将变量更新视为特殊的控制事件流,符合 Even Driven 的流式计算框架定位,目前在业界已有比较成熟的应用。不过美中不足的是编程模型的易用性上有提高空间:控制流目前只能用于和数据流的 join,这意味着下游节点无法继续访问控制流或者需要把控制流数据插入到数据流中(这种方式并不优雅),从而降低了编程模型的灵活性。个人认为最好的情况是大部分的算子都可以被拓展为具有 BroadcastOperator,就像 RichFunction 一样,它们可以接收一个数据流和一个至多个控制流,并维护对应的 BroadcastState,这样控制流的接入成本将显著下降。
参考文献
1.FLIP-17 Side Inputs for DataStream API
2.Dynamically Configured Stream Processing: How BetterCloud Built an Alerting System with Apache Flink®
3.Using Control Streams to Manage Apache Flink Applications
4.StackOverFlow - ow can I update a broadcast variable in spark streaming?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号