

猫狗分类CNN
猫狗分类CNN
实验环境
编译器 :win10+python3.7.4+pycharm2018
库: anaconda+pytorch+tensorflow+tensorboardX
硬件 gpu(可以没有)
性能:
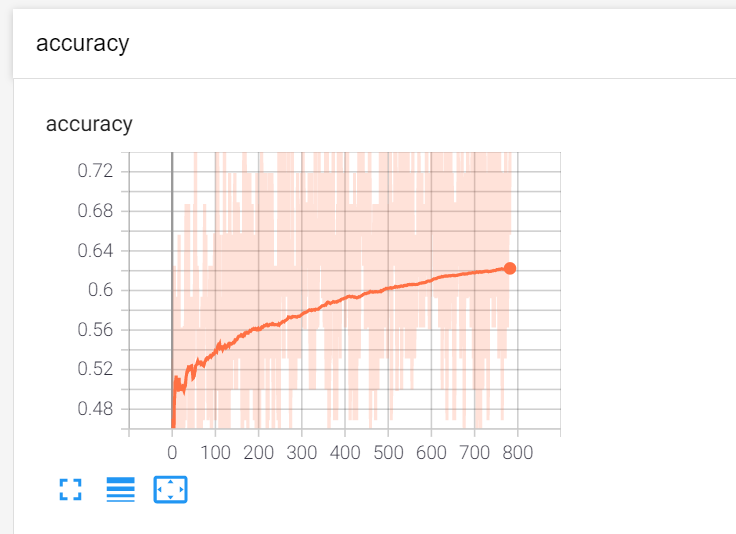
accuracy:准确度大概稳定在0.6左右。这是在二分类的情况下。如果测试自己的图片,也就是存既不是猫也不是狗的概率的话,肯恶搞准确度会更低。
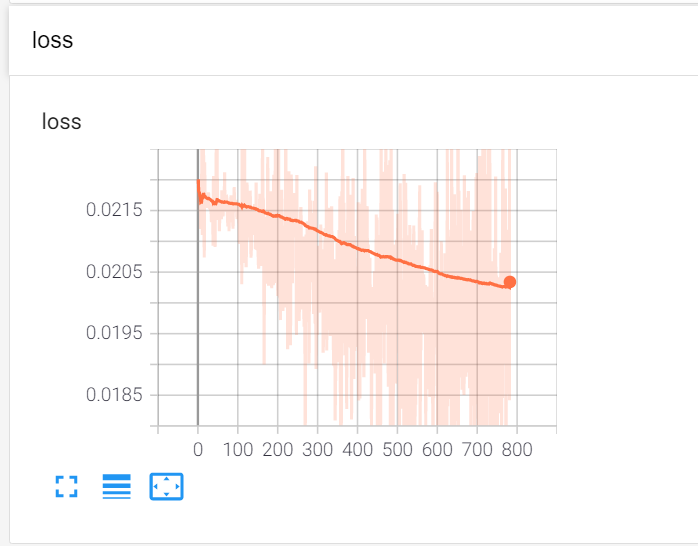
loss:约为0.02
Ⅰ、解决方法
一、数据集的预处理
1.训练集
1.1.1 初始化:提取路径和标签
这个问题是kaggle竞赛的一个赛题。所以数据集也是由官方提供的。训练集内容如下图

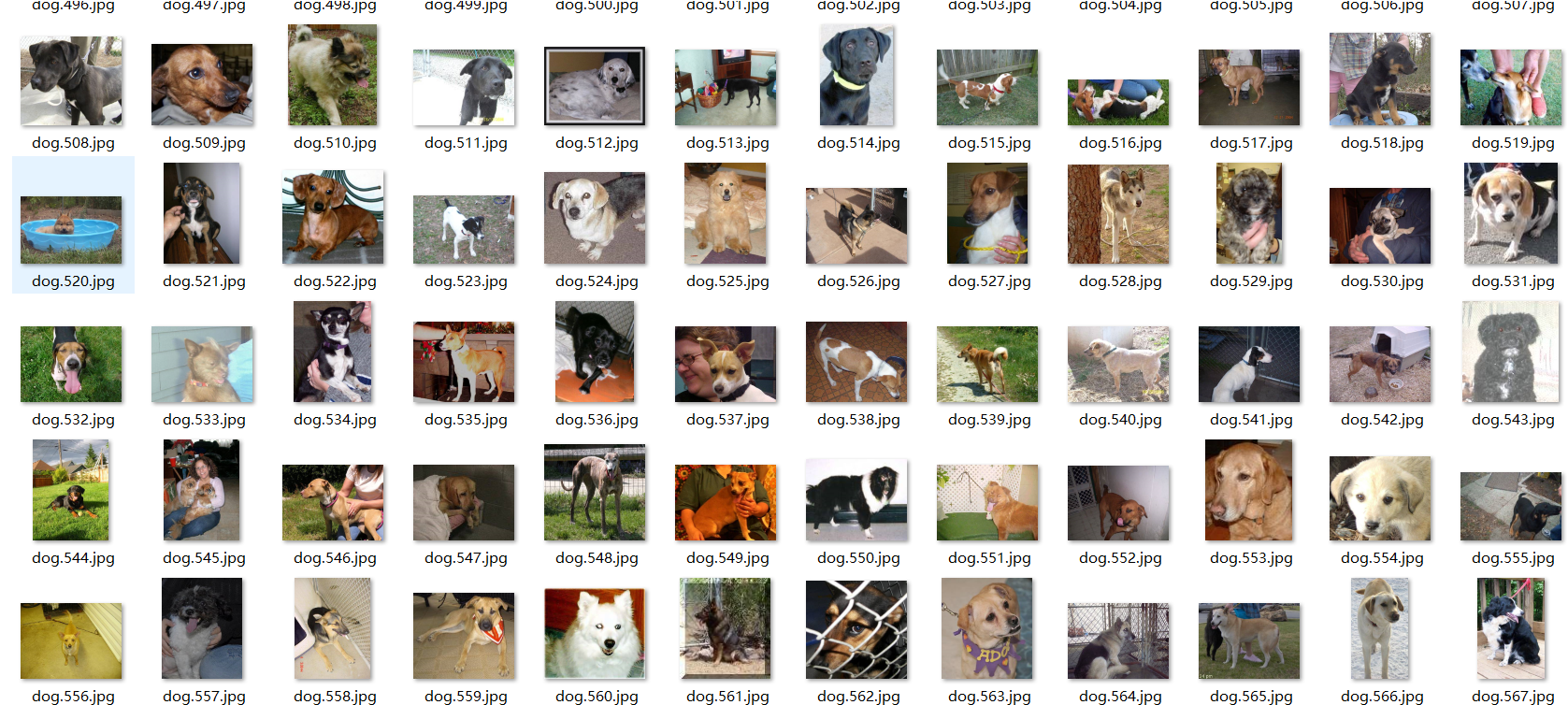
我们可以看到,它的命名规则是 分类.序号.jpg
所以我们就只要建立两个list,一个存路径,一个存标签
self.list_img = []
self.list_label = [] # 0:cat,1:dog
然后打开训练集,循环遍历里面的图片
dir = train_path + '/' #train_path为训练集文件夹
for file in os.listdir(dir):
self.list_img.append(dir + file)
self.data_size += 1
name = file.split(sep='.') #以'.'为界限,分割文件名
# one-hot
if name[0] == 'cat':
self.list_label.append(0)
else:
self.list_label.append(1)
采用one-hot编码,这样对后期计算损失函数比较友好。
1.1.2 处理图片
思路:打开图片-->重新设置图片大小-->转换图片为tensor的形式-->返回tensor和标签
img = Image.open(self.list_img[item]) #item为选中的图片序号
img = img.resize((IMAGE_H, IMAGE_W)) #重新设置图片大小
img = np.array(img)[:, :, :3]
label = self.list_label[item]
return self.transform(img), torch.LongTensor([label])
其中transform函数的方法是
transforms.ToTensor()
2.测试集
1.2.1初始化:
这是大赛提供的测试集。叫测试集或许不太准确,因为他没有打标签。姑且叫他测试集好了。

初始化的思路比训练集要简单,因为没有标签,所以只要遍历文件夹然后把路径存起来。
dir = test_path + '/'
for file in os.listdir(dir):
self.list_img.append(dir + file)
self.data_size += 1
1.2.2 处理图片
和训练集差不多,因为没有标签所以只需要返回图片就行
img = Image.open(self.list_img[item])
img = img.resize((IMAGE_H, IMAGE_W))
img = np.array(img)[:, :, :3]
return self.transform(img)
二、模型搭建
伤透心,别人代码随便搭的网络都比我的效果好。果然,网络的搭建还是要有经验。
有人说可以修改预训练好的模型来再处理。看了好久,感觉搭了之后可视化就不太会用了。作为新手操作不了,所以还是选择用这样的方法来做
def __init__(self):
super(myNet, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1)
self.conv2 = torch.nn.Conv2d(16, 16, 3, padding=1)
self.fc1 = nn.Linear(50*50*16, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = x.view(x.size()[0], -1)
x=self.fc1(x)
x = F.relu(x)
x=self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
return F.softmax(x, dim=1)
三、训练
1.参数
训练就是普普通通的调用啦,然后一些参数什么的都写在开头,可以根据自己的电脑性能改一改,我的初始参数如下
writer = SummaryWriter('./runs') #可视化保存位置
save_model_path = './model/myModel.pth' # 模型保存位置
workers = 10 # PyTorch读取数据线程数量
batch_size = 32 # batch_size大小
lr = 0.0001 # 学习率
2.loss和准确度
因为是要有迭代的曲线。所以loss和准确度都是采用最近训练的结果来计算的。我是以一个batch_size作为节点计算一次。
其中loss是交叉熵计算法
for img, label in dataloader:
img, label = Variable(img).cuda(), Variable(label).cuda()
out = model(img)
loss = criterion(out, label.squeeze())
loss.backward()
optimizer.step()
optimizer.zero_grad()
cnt += 1
_, preds = torch.max(out.data, 1)
acc = float(torch.sum(preds==label.squeeze()))
print('epoch:{},acc:{:.4f}, loss: {:.4f}'.format(cnt, acc/out.size()[0],loss/batch_size))
3.结果
具体的曲线实现和展示,在可视化部分说明
四、测试
1.test
测试方法就是随机从测试集中提取一个图片,然后输出结果。
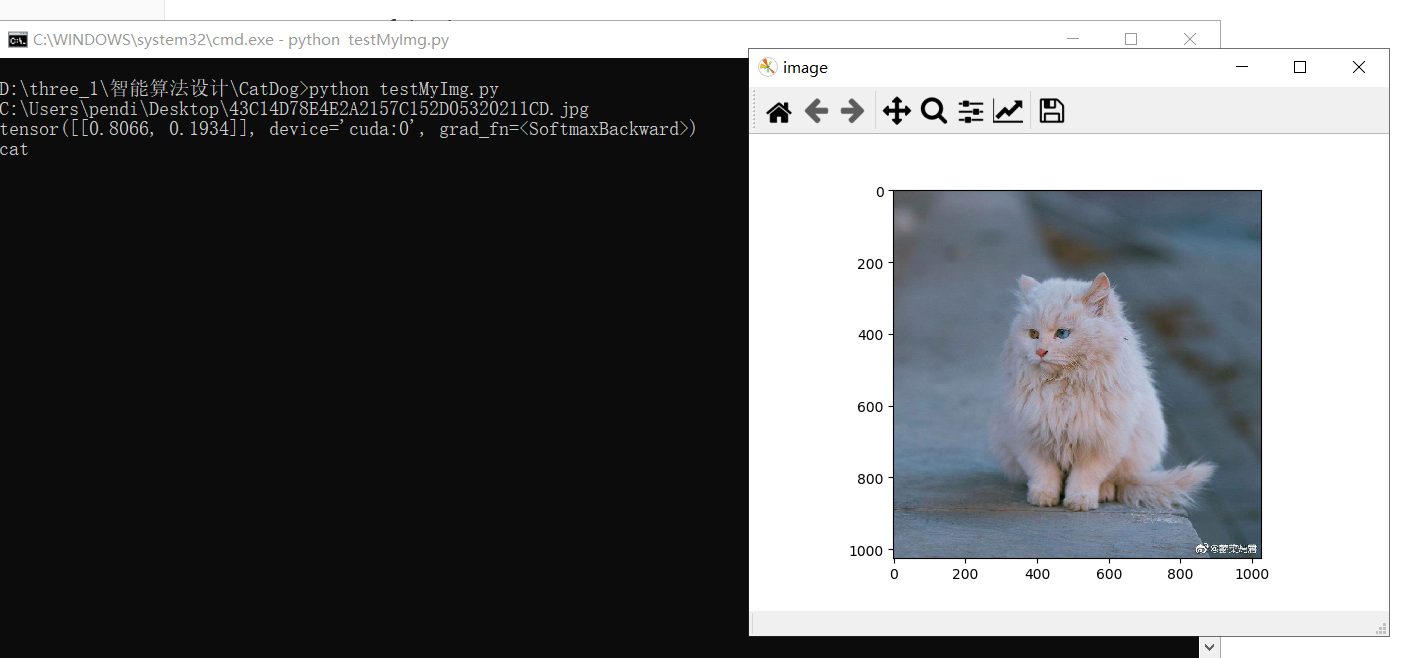
2.testMyImg
这个测试就是可以测试自己的图片的。
与test的不同点在于,test测试的都是大赛给的数据集,所以内容不是猫就是狗。但是testMyImg是输入自己的图片,所以可能既没有猫,也没有狗。所以我设置了一个阈值VPT,只有可能性超过VPT才会判定。
可以根据自己的需求修改
VPT=0.5
注意!!因为设置的三通道,所以图片格式为jpg
3.结果
1.test结果
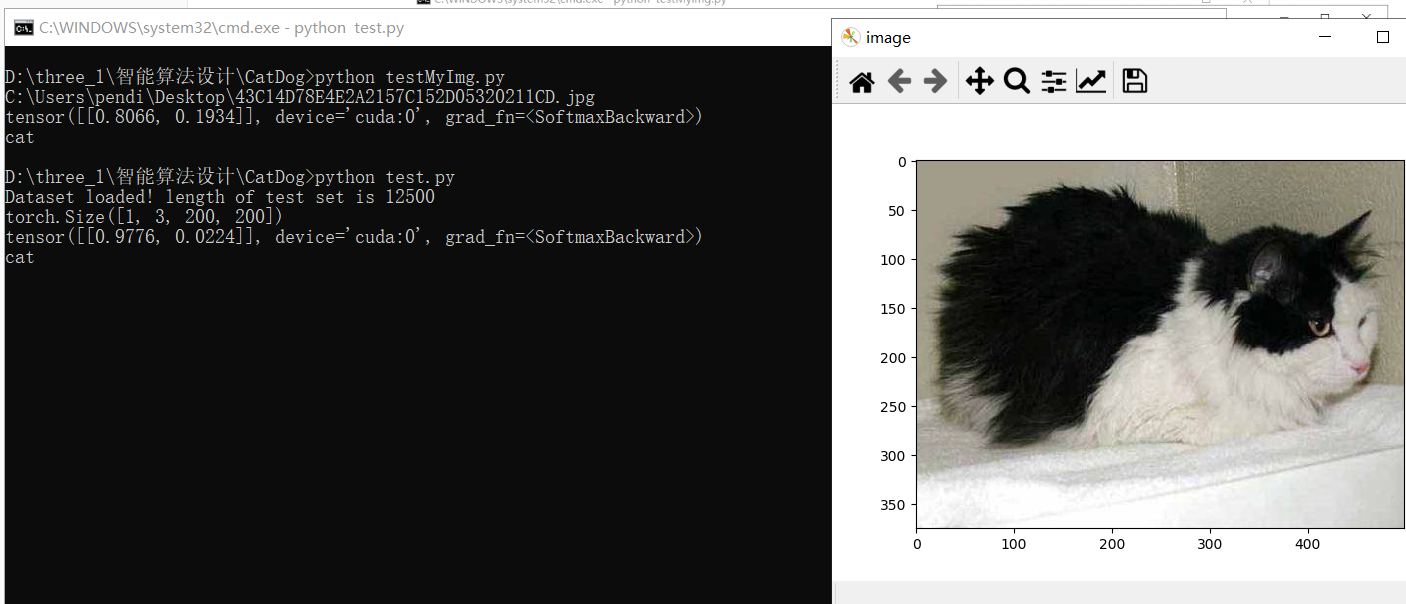
2.testMyImg
3.我将整个网络结构都可视化了。具体方法在可视化部分说明
Ⅱ 可视化
一、工具
本来想用qypt来做一个界面,在里面可视化输出的。但是中间出的叉子比较多。还涉及到多线程,速度太慢了。无意中发现了tensorboardX。发现太好用了!对于我这种还没入门的新手,需要的功能还特别简单。上手特!别!快!
tensorboardX是tensorflow下的一个可视化工具。所以要用tensorboardX的话,要同时安装tensorflow和tensorboardX。anaconda下安装就行了,推荐使用豆瓣源
二、代码详解
我是在训练里可视化loss和accracy曲线。然后测试里可视化了cnn网络结构和权重以及卷积核
开头定义了保存位置,可以根据自己的需求修改
writer = SummaryWriter('./runs') #可视化保存位置
1.loss和accracy曲线
用的是tensorboard的add_scalar
writer.add_scalar('loss', loss/out.size()[0], cnt)
writer.add_scalar('accuracy', acc/out.size()[0],cnt)
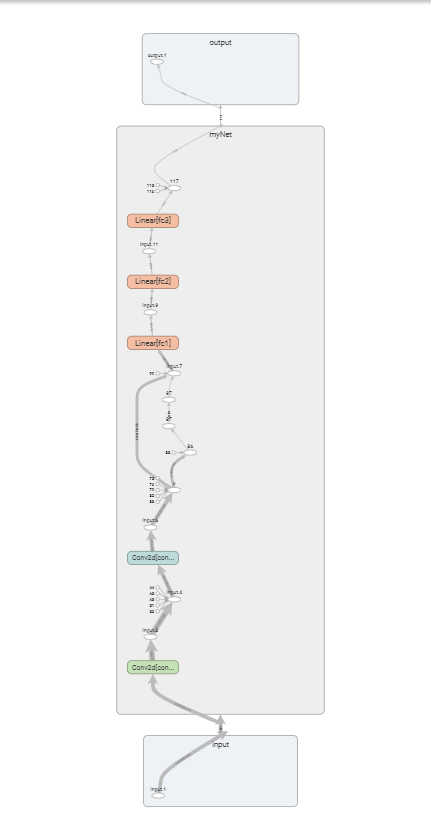
2.cnn网络结构可视化
writer.add_graph(model, (img,)) # 记录神经网络结构
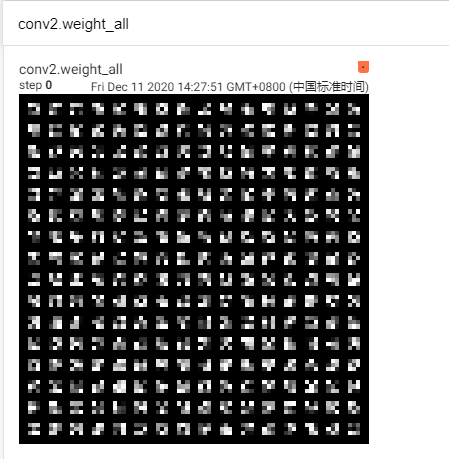
3.权重、卷积核可视化
权重可视化
for name, param in model.named_parameters():
if 'conv' in name and 'weight' in name:
in_channels = param.size()[1]
k_w, k_h = param.size()[3], param.size()[2] # 卷积核的尺寸
kernel_all = param.view(-1, 1, k_w, k_h) # 每个通道的卷积核
kernel_grid =utils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=in_channels)
writer.add_image(f'{name}_all', kernel_grid, global_step=0)

卷积核特征值可视化(根据自己的网络结构编写)
for name, layer in model._modules.items():
if not('conv' in name):
break
showImg=layer(showImg)
showImg=F.relu(showImg)
showImg=F.max_pool2d(showImg,2)
#
x1 = showImg.transpose(0, 1)
img_grid = utils.make_grid(x1, normalize=True, scale_each=True, nrow=4) # normalize进行归一化处理
writer.add_image(f'{name}_feature_maps', img_grid, global_step=0)


4.其它
原图存储(以test为例,testMyImg也差不多)
writer.add_image('img',datafile.__getitem__(index),)

结果存储
writer.add_text('test\' result',str)

三、使用方法
可以在命令行操作 ,输入tensorboard =可视化文件所在位置
tensorboard --logdir=runs

注意!!!!!
runs文件内容每次都会添加,而不是覆盖。如果觉得数据有干扰的话,建议每次运行之前,把上一次的runs文件删掉
