
python人脸识别+语音识别 的监控系统
使用流程
添加成员-->训练模型-->监控
注:添加成员后,数据仅仅保存在后台,并没有在模型里。所以此时监控,就没有这次新添加的成员。只有训练模型后才会存入在模型里
主页
添加成员

采集数据数量:人脸采集照片的数量。数量越多,模型训练效果越好
每张照片间隔帧率:采集照片间隔的帧数。如果连续采集,照片相似度太高。建议每次采集照片间隔一段时间,用户可以改变角度和位置。效果会更好
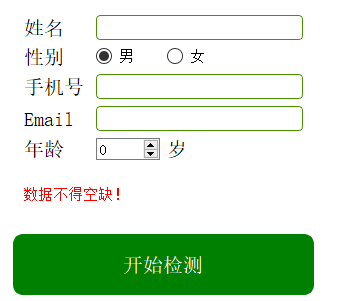
如果信息没有填写完整,会出现以上情况。
注:请填写英文,否则可能信息会出现乱码情况
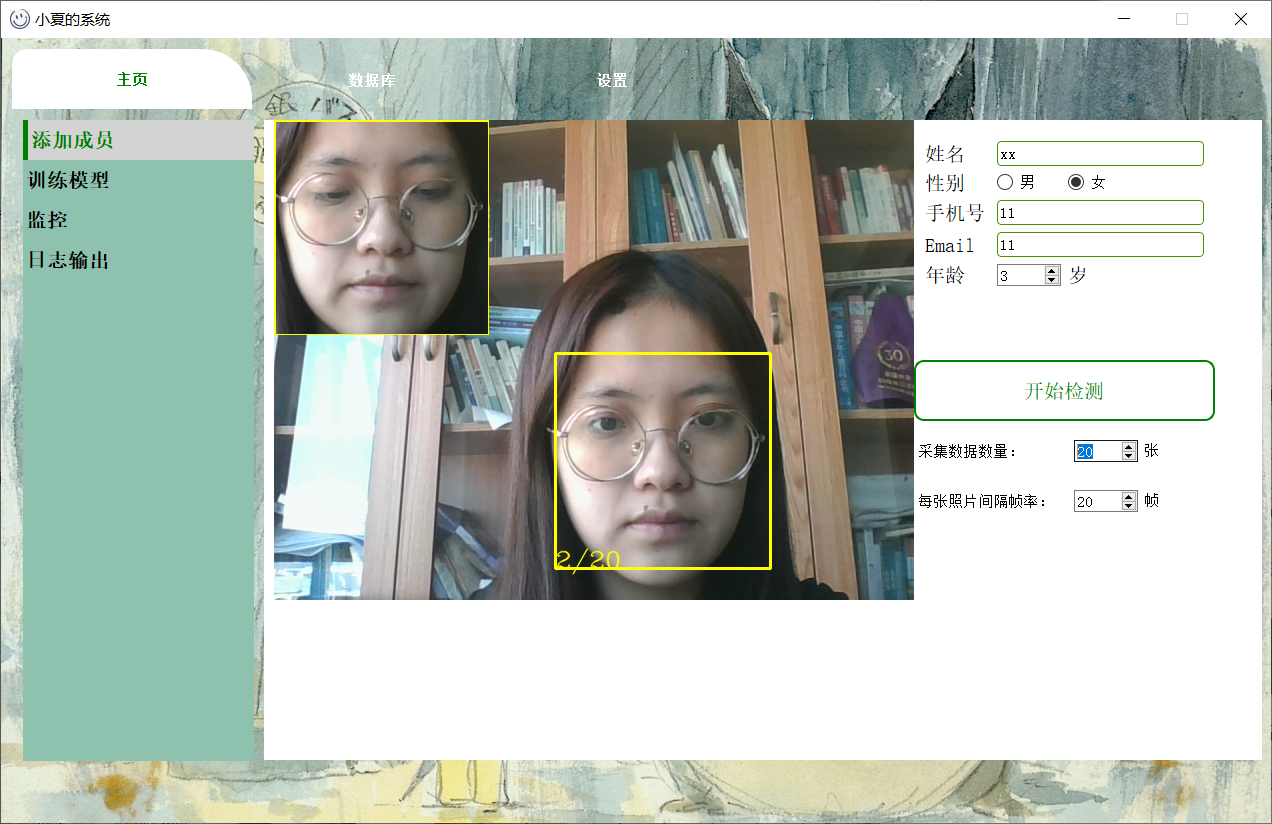
人脸框下显示当前已采集的照片数量。
左上角显示采集的照片样子。
训练模型
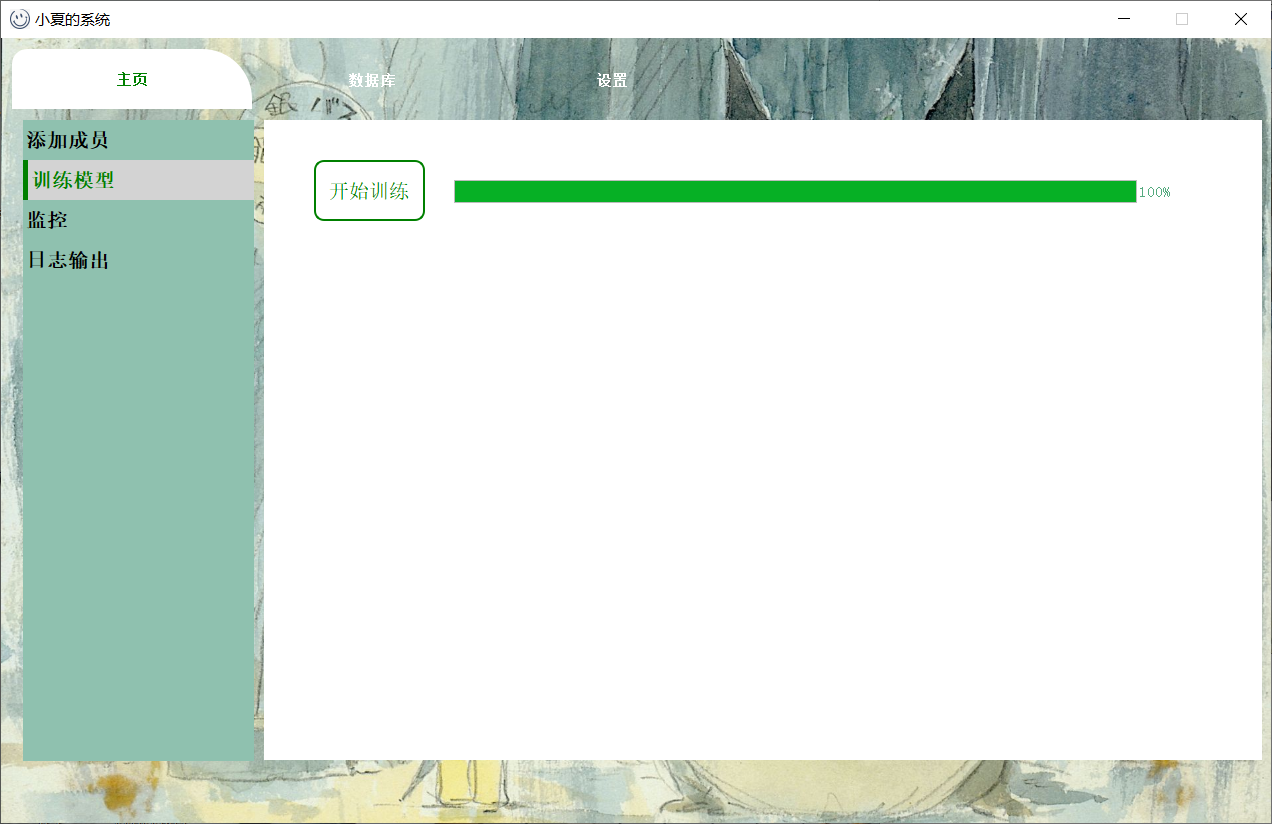
训练模型时间较长。期间如果进行别的操作,可能还会出现(未响应)的情况,非常正常。每训练完一个人,进度条才会刷新一次。进度条长时间不动,也是正常情况
监控
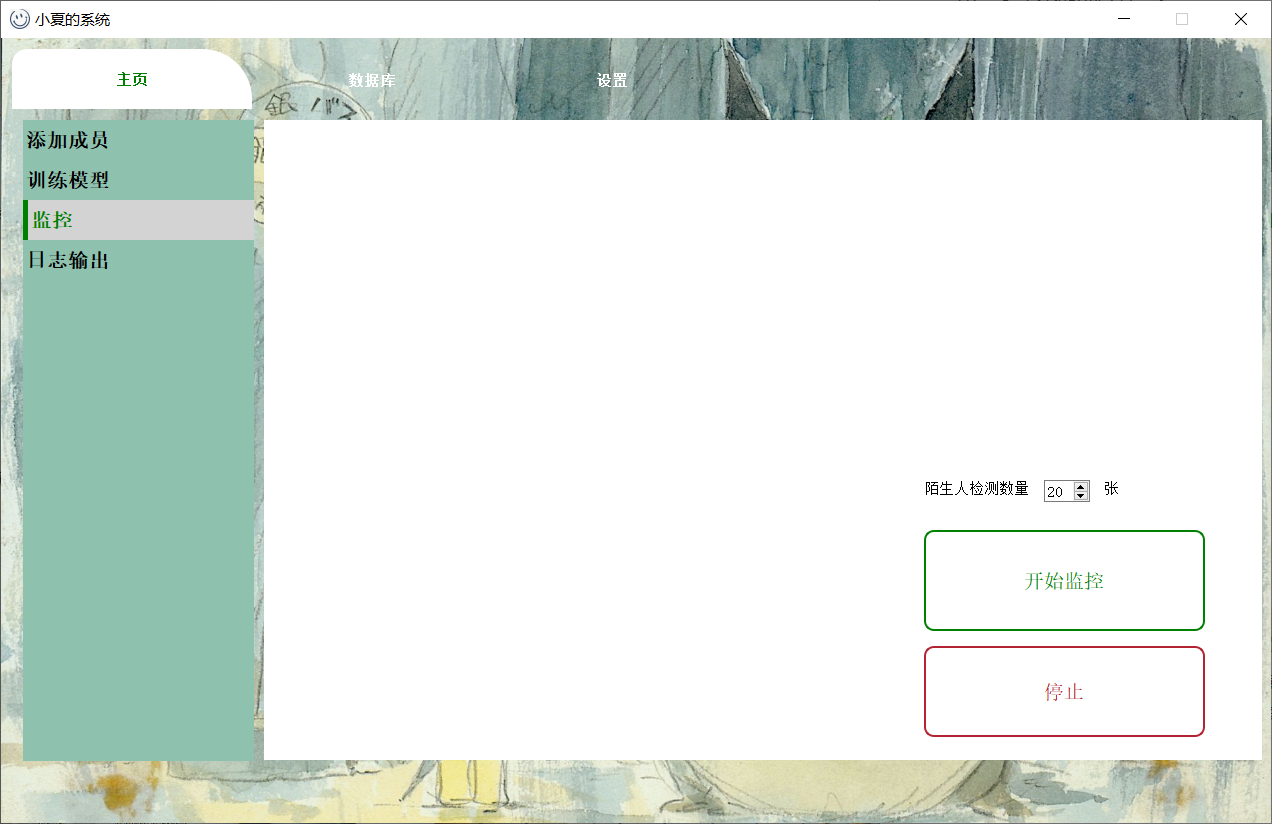
陌生人检测数量:指的是连续检测多少张才判定为陌生人。逻辑就是,偶尔可能有人不小心入镜或者路过,就无需监控警报。

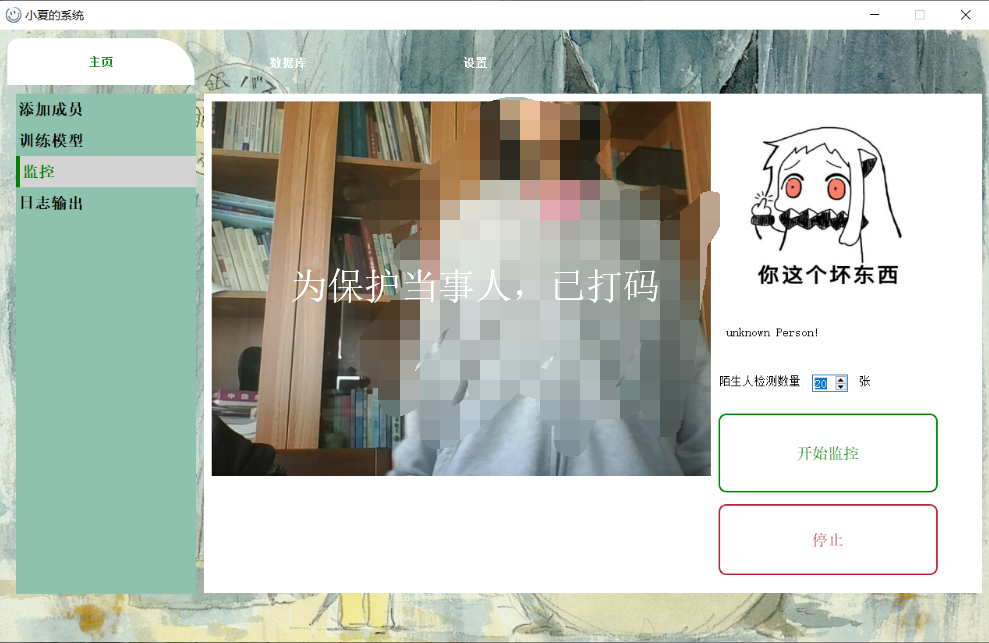
如果检测到熟人,就会立刻显示编号+人名。右上角出现提示,并且发出叮咚的提示音。
如果检测到陌生人,就会显示“unknown Person!”字眼。右上角出现提示,并发出“吨~~~”的警报音
注:为了防止误操。点击开始监控后,此按钮就不可再用了。只能点击停止按钮。
日志输出
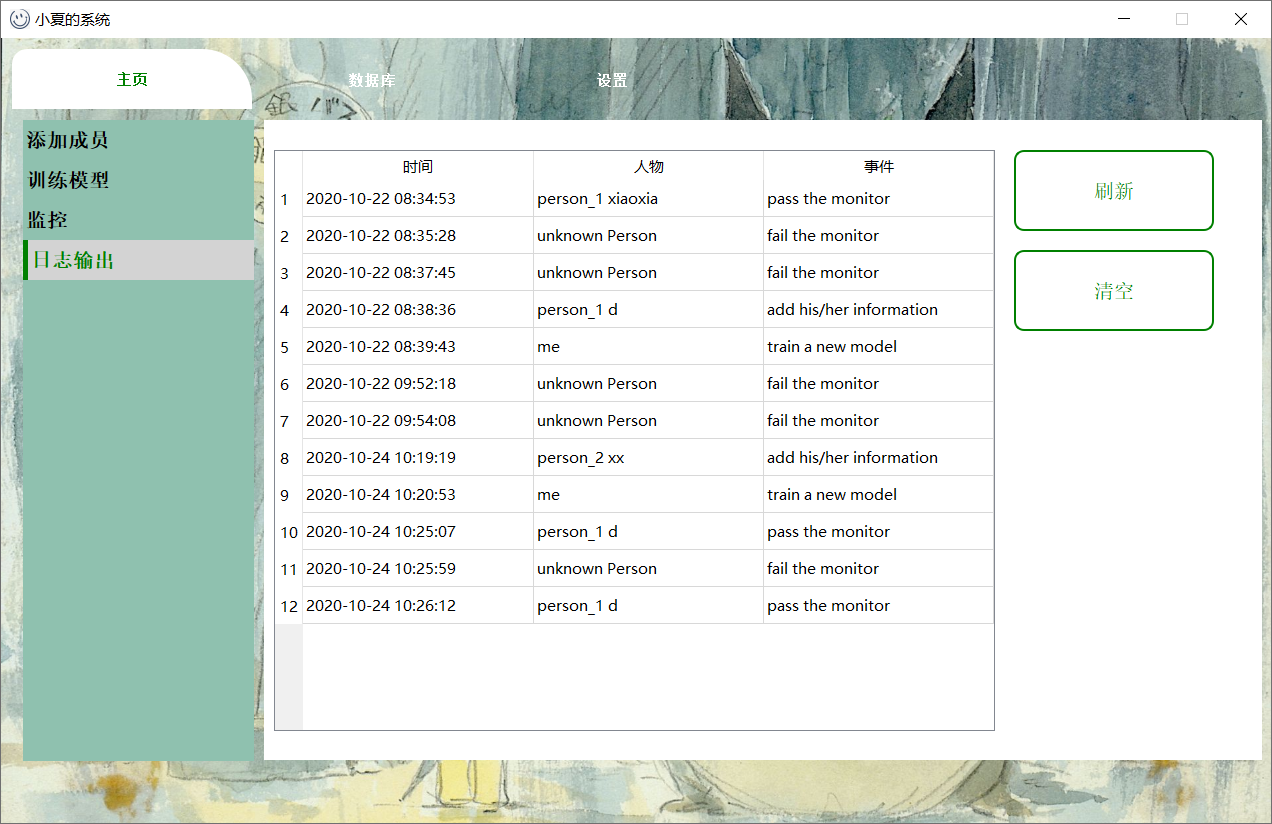
刷新:就是把最新的一些操作显示
清空:清空所有的日志文件
数据库
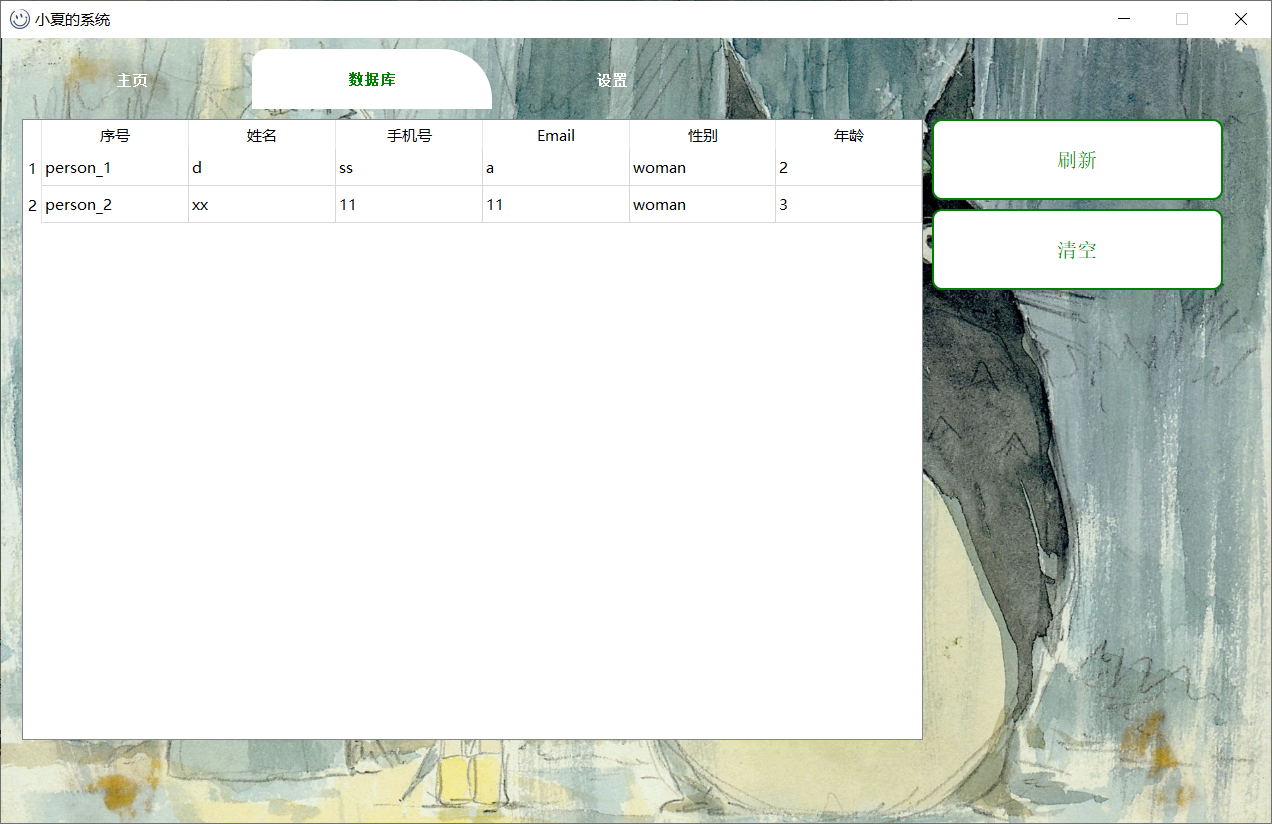
显示所有成员的信息
清空:清空所有成员的信息,连同采集的照片集和模型。再次监控时,将会被判定为陌生人
设置

静音模式:勾选后,监控就不会发出提示音和警报音
语音助手:勾选后,可以语音控制。此模式需要在网络环境。
语音助手(网络环境)
训练模型: ['开始训练', '训练模型','train model'],
开始监控:['开始监控', '打开监控'],
停止监控: ['停止监控', '关闭监控'],
日志输出:['打开日志','查看日志'],
清空日志:['清除日志','清空日志'],
刷新日志:['刷新日志'],
数据库:['打开数据库','查看数据','查看信息'],
设置:['打开设置','查看设置'],
添加成员:['添加人员']
设置了以上几条语音命令。
只要包含以上关键词,就可以实现操作。
注:系统实时监测麦克风,超过一定的分贝才会语音检测。命令加一些前缀,比如“请”,“小夏”之类的,效果会更加
超过一定的次数,接口就要收费的。但我是不会花钱的,到时候就没得用了。所以没事别用这个!

