
python4
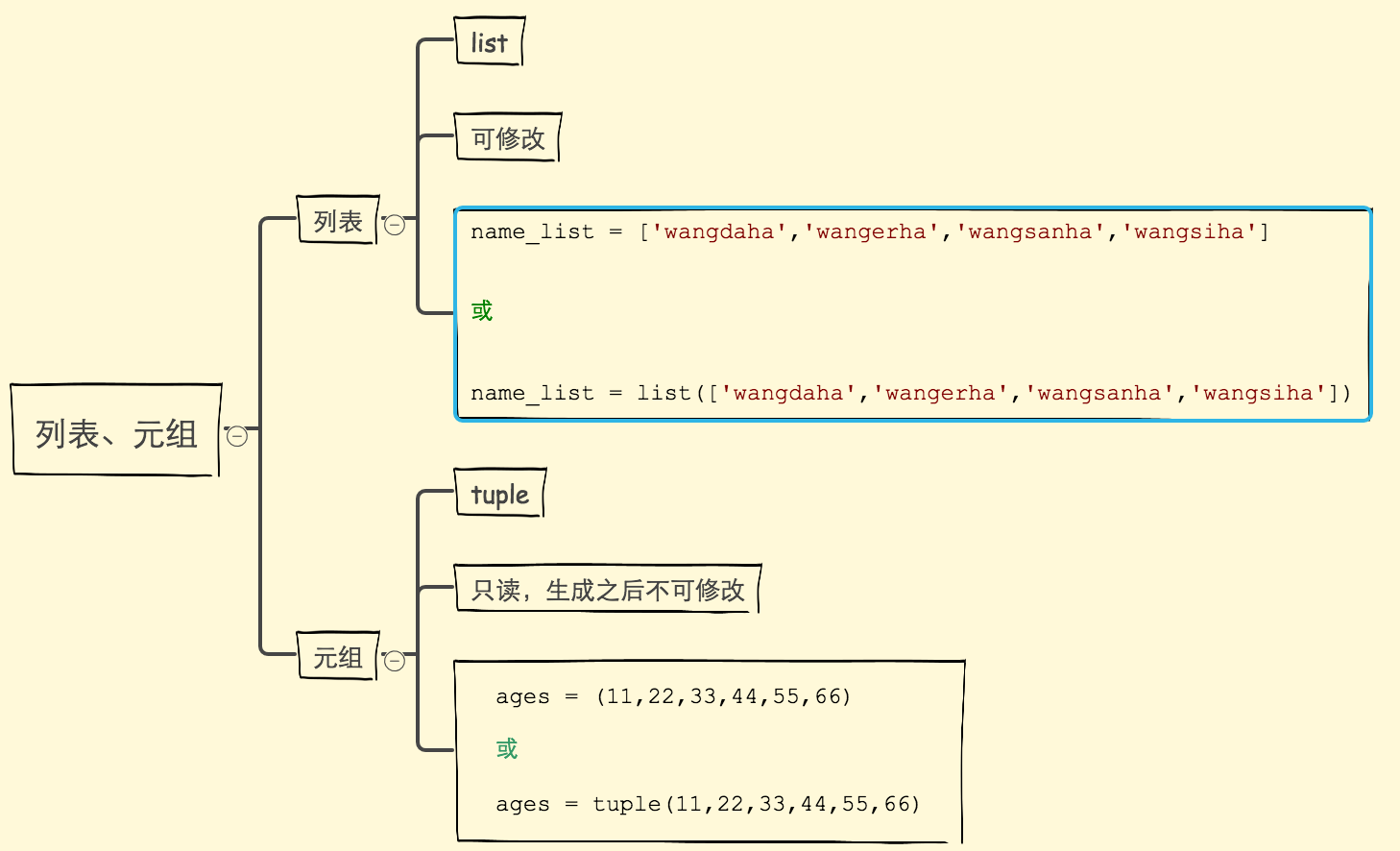
元组
定义
不可变列表
类型:tuple

不能修改,只能统计和获取数据操作而已,如果做其他的操作就会报错:TypeError: 'tuple' object is not callable
创建元组
ages = (11,22,33,44,55,66)
或
ages = tuple(11,22,33,44,55,66)
元组与列表
基本操作
1、统计:count
特性:
count(),括号里面一定要填写元素,如果为空的话会报以下错误:TypeError: count() takes exactly one argument (0 given)
返回的结果为统计元素的个数,如果元素不存在的话,返回的结果是0
r = (1,2,3,4,5,5,5,5) r1 = r.count(7) print(r1) #运行结果:4 #在count(),括号里面必需填写元素,如果元素不存在的话返回0,如果元素存在的话会返回元组里面有多少个元素
2、索引:index
特性:
index(),括号里面一定要填写元素,如果为空的话会报错:TypeError: index() takes at least 1 argument (0 given)
返回结果为该元素的位置
如果有重复的元素的话,返回的永远是第一个元素的位置
如果元素不错在的话会报错:ValueError: tuple.index(x): x not in tuple
r = (1,2,3,4,5,5,5,5) r1 = r.index(2) print(r1) #运行结果:1 #在index(),括号里面需要填写元素,并且返回的结果是该元素在元组当中的位置,如果有重复的元素的话,则是返回第一个元素的位置就停止了。不可为空
备注:
1)可以通过pycharm定义一个元组,在查看全部可以使用的基本操作;两个下划线的表示的是内部的方法,我们不能使用。

2)应用场景:程序不想被人修改的时候(统计全部国家的一个列表,已经是一个定数了,修改的可能性不大。)
数据运算
算数运算

1、取模:% 返回除数的余数
应用场景:如上面的图片,奇数是白色的背景色,偶数是灰色的背景色
print(10 % 2) print(11 % 2) # 结果 #0 #1
2、取整数://
print(10.3 // 3) #取整数 print(10.3 / 2) #除法 # 结果 #3.0 #5.15
比较运算

<> 与!=一样,但是一般使用的是!=
赋值运算

逻辑运算

and:全部为真即为真,有一个假即为假
a,b,c = 3,5,7 print(a >2 and c <7) print(a >2 and c <8) print(a >2 and c <7 and b > 4) # 结果 #False 真假=假 #True 真真=真 #False 真假假 = 假 #假假 = 假,真假 = 假 假真 = 真 真真 = 真 #可以加多个and(一般是使用2个)必须全部为真才是真
or:只要有一个为真就为真,全部为假才是假
a,b,c = 3,5,7 print(a >2 and c <8 and b > 4 or c == 8) print(a >2 and c <7 and b > 4 or c == 8) # 结果 #True #False #只要有一个为真就为真,必须两个都是假才是假 #a >2 and c <8 and b > 4 为真 c == 8 为假 所以为真 #a >2 and c <7 and b > 4 为假 c == 8 为假 所以为假
not: if not 后面的条件如果为真的话则执行print语句,为假的话不执行(还在在疑问?????)
a,b,c = 3,5,7 if not a >2 and c <8 and b > 4 or c == 7:print("ddddd") if not a >2 and c <7 and b > 4 or c == 8:print('dddd') # 结果 #dddd #空 #if not 后面的条件如果为真的话则执行print语句,为假的话不执行 a = [1,2,3,4] if 1 not in a:print('hahhah') if 32 not in a :print('hahahhah') # 结果 #空 #hahahhah a = '333' if not a.isdigit():print('ddds') print(type(a)) print(a.isdigit()) #结果: #<class 'str'> #True
成员运算

身份运算

is
a = [1,2,3,4] print(type(a)) print(a is list) print(type(a) is list)
# 结果 #<class 'list'> #False #True
位运算

二进制
1、二进制是计算机里最小的单位,只有两个值:分别是0或1
2、计算机里面为什么用0和1来表示最小的单位?
因为计算机最底层是通过电流来实现的,通过电流来表示数字、文字等,但是电流只有开、关两种情况,一个动作只能代表一个信息。
电流代表最简单的信息,通过0和1来传递更新的信息。

最大:1024
规律:前面的数加起来比后面的这个数少1,例如要用第五位的16来表示前面四个数的话16-1 = 8+4+2+1
电路也是只能用开关来表示两种状态,关 = 0 ,开 =1
计算机的加法

计算机中能表示的最小单位:一个二进制位(0或1)=1bit
计算机中能存储的最小单位:1个二进制位(表示一个信息)
人们为了看起来比较容易,将二进制分组成8个二进制位一组:8 bit =1byte(字节)
计算机任何一个字符至少用1个字节存储
1024byte = 1kbyte(下载用的)
1024kbyte = 1mbyte
1024mb = 1gb
1024gb = 1tb
&:与、and 运算
a = 60 #60 = 0011 1100 b = 13 #13 = 0000 1101 print(a & b) #结果 #12 0000 1100
1&1 =1 1&0=0 0&1=0 0&0=0

|:或运算
a = 60 #60 = 0011 1100 b = 13 #13 = 0000 1101 print(a | b) #结果 #61 0011 11001
0|0=0 1|0=1 0|1=1 1|1=1

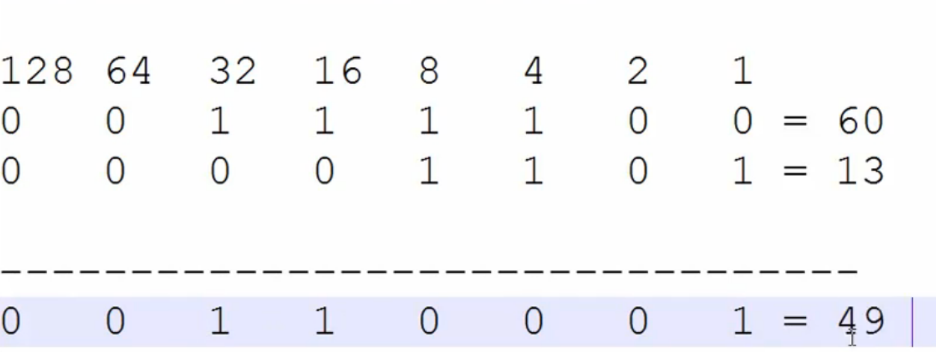
^ :异或运算
a = 60 #60 = 0011 1100 b = 13 #13 = 0000 1101 print(a ^ b) #结果 #49 0011 0001
0^0=0 1^1=0 (相同为0)
0^1=1 1^0=1 (不同为1)
~:按位取反运算--取一个值的反数
a = 60 #60 = 0011 1100 print(~a) #结果 #-61 195-256=-61
对60取反得到二进制1100 0011=195 256-195=-61

<<:左移
左移1 = 60*2
左移2 = 60*4
a = 60 #60 = 0011 1100 print(a<<2) #结果 #240
>>:右移
右移1 = 60/2
右移2 = 60/4
a = 60 #60 = 0011 1100 print(a>>2) #结果 #15
运算符优先级

while死循环(loop)
定义
有一种循环叫死循环,一经触发,就永远的运行着,但是计算机的内存是有限的,所以如果内存不够的话就不会再循环了。
创建死循环
while True:只要为真,会一直运行下去,没运行一次就打印并且自动加1
count = 0 while True: print("hahahhha",count) count +=1
应用
达到一定的条件停止循环
如果count加到100的话就停止。
break:跳出整个循环
continue:运行到continue的话下面的程序就不走了,直接接上下一个循环
count = 0 while True: print("循环啊循环啊循环",count) count +=1 if count == 100: print("不循环啦") break #打印结果 ''' 循环啊循环啊循环 0 循环啊循环啊循环 1 ....0-99不列出啦,太长了 循环啊循环啊循环 94 循环啊循环啊循环 95 循环啊循环啊循环 96 循环啊循环啊循环 97 循环啊循环啊循环 98 循环啊循环啊循环 99 不循环啦 '''
2、选择性循环打印
count = 0 while True: count +=1 #需要放到这个位置,不能放在continue后面,因为这样的话就不会自加1了。 if count > 2 and count <10: continue print("循环啊循环啊循环",count) if count == 15: print("不循环啦") break #打印结果 ''' 循环啊循环啊循环 1 循环啊循环啊循环 2 循环啊循环啊循环 10 循环啊循环啊循环 11 循环啊循环啊循环 12 循环啊循环啊循环 13 循环啊循环啊循环 14 循环啊循环啊循环 15 不循环啦 '''
字典
从13亿中国人当中找出王小华
方法一
列表
1、取值的话,需要先知道元素的索引值
2、如果不知道索引值,需要先查询元素的索引值在进行取值
3、思路:
王小华会有对应的很多信息(身份证号、籍贯、性别等信息)
通过大列表嵌套下列表将王小华的其它信息包含进去
name = [1,[123988298,'wangxiaohua','shandong'],56,456,'hjjjj'] print(name.index(123988298)) #结果: #ValueError: 123988298 is not in list #通过index方法来查找的话只能查找到大列表里面的元素,对于嵌套在大列表的小列表并不能查找到。
方法二、通过for循环(不具备去重功能,容易出现循环错误;如果身份证号码或者其它信息重复的话不具备去重的效果)
方法三、字典
1、字典里面可以嵌套:字典、列表等元素
2、去重功能--随机
id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977890:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } print(id_db)
#结果: #{347917737977890: {'name': 'wangxiaohong', 'age': 20, 'addr': 'shanghai'}, # 347917734392438: {'name': 'wangdaha', 'age': 20, 'addr': 'beijing'}} #小华跟小红的身份证是重复的,所以随机去掉了一个
结构
1、key:value 结构
2、key 必须是唯一的,如果key重复的话会随机显示一个
3、中括号开始--中间是key:value对,value里面可以是任何东西:字典、字符串、列表等 --中括号结束
4、嵌套里面的小字典也是 key:value对,每个key:value对用逗号隔开

基本操作
1、取值--通过key取(唯一性)
id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977893:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } print(id_db[347917737977890])
#结果: #{'addr': 'shanghai', 'age': 20, 'name': 'wangxiaohua'} #取得是347917737977890对应的value值
2、修改
id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977893:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } id_db[347917737977890]['name'] = 'wangwang' print(id_db[347917737977890]) #结果: #{'name': 'wangwang', 'addr': 'shanghai', 'age': 20} #取得是347917737977890对应的value值,将name修改成wangwang
3、添加值
id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977893:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } id_db[347917737977890]['wife'] = 'hehe' print(id_db[347917737977890]) #结果: #{'addr': 'shanghai', 'age': 20, 'wife': 'hehe', 'name': 'wangxiaohua'} #347917737977890对应的value值里面添加wife key:value对
4、删除
del删除
id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977893:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } del id_db[347917737977890]['name'] print(id_db[347917737977890]) #结果: #{'addr': 'shanghai', 'age': 20}
POP删除
id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977893:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } id_db[347917737977893].pop("age") print(id_db[347917737977893]) #结果: #{'addr': 'shanghai', 'name': 'wangxiaohong'}
5、copy:与列表中的copy一样
6、clear:清空操作
7、获取:get
查询的key不存在
id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977893:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } print(id_db.get(3479177324893)) #结果: #None key:3479177324893对应是没有value的,所以打印出来是none
#如果没有对应的value会直接报错 id_db = { 347917737977890:{ 'name':'wangxiaohua', 'age':20, 'addr':'shanghai', }, 347917737977893:{ 'name':'wangxiaohong', 'age':20, 'addr':'shanghai', }, 347917734392438: { 'name': 'wangdaha', 'age': 20, 'addr':'beijing', }, } print(id_db[3479177324893]) #结果: #KeyError: 3479177324893
8、update:更新
id_db = { 1111:'1', 2222:'2', } id_db2 = { 3333:'3', 4444:'4', 5555:'5' } id_db.update(id_db2) #将id_db2字典里面的东西更新到id_db字典里面去 print(id_db) #结果: # {5555: '5', 4444: '4', 3333: '3', 2222: '2', 1111: '1'} #将id_db2更新到id_db里面,如果id_db里面没有的的话直接添加上去
#相同的key,不同的value id_db = { 1111:'1', 2222:'2', } id_db2 = { 1111:'11', 4444:'4', 5555:'5' } id_db.update(id_db2) #将id_db2字典里面的东西更新到id_db字典里面去 print(id_db) #结果:{5555: '5', 4444: '4', 2222: '2', 1111: '11'} #id_db2的value直接覆盖到id_db中
9、item:将字典变成一个元祖(列表)
id_db = { 1111:'1', 2222:'2', } print(id_db) print(id_db.items()) #结果: #print(id_db) #print(id_db.items())
10、打印所有的values
id_db = { 1111:'1', 2222:'2', } print(id_db) print(id_db.values())
#结果: #print(id_db) #dict_values(['2', '1'])
11、打印所有的keys
id_db = { 1111:'1', 2222:'2', } print(id_db) print(id_db.keys())
#结果: #print(id_db) #dict_keys([2222, 1111])
12、判断对应的字典里是否包含我们想要的身份证号
适用于python2、python3版本
id_db = { 1111:'1', 2222:'2', } print(id_db) print(999 in id_db)
#结果: #print(id_db) #False #表示在id_db里面没有这个key
仅仅适用于python2版本
1 id_db = { 2 1111:'1', 3 2222:'2', 4 } 5 print(id_db) 6 print(id_db.has_key(9999)) 7 8 #结果: 9 #print(id_db) 10 #False #表示在id_db里面没有这个key
13、setdefault:添加一个key:value对
1 #添加一个只有key没有value的,默认value为none 2 id_db = { 3 1111:'1', 4 2222:'2', 5 } 6 print(id_db) 7 id_db.setdefault(9999) 8 print(id_db) 9 10 #结果: 11 #print(id_db) 12 #{9999: None, 2222: '2', 1111: '1'} 13 14 15 16 #添加key:value对 17 id_db = { 18 1111:'1', 19 2222:'2', 20 } 21 print(id_db) 22 id_db.setdefault(9999,'9') 23 print(id_db) 24 25 #结果: 26 #print(id_db) 27 #{9999: '9', 2222: '2', 1111: '1'}
14、formkeys
将列表里面的每一个元素取出来,将其当作一个key存到字典里面,并且对应的value都是dddd
1 id_db = { 2 1111:'1', 3 2222:'2', 4 } 5 print(id_db.fromkeys([11,22,33,44],'dddd')) 6 print(id_db) 7 print(dict.fromkeys([11,22,33,44],'dddd')) 8 9 10 #结果: 11 #{33: 'dddd', 11: 'dddd', 44: 'dddd', 22: 'dddd'} 12 #{2222: '2', 1111: '1'} 13 #{33: 'dddd', 11: 'dddd', 44: 'dddd', 22: 'dddd'} 14 #通过字典去调用对象里面的方法,只要是字典都可以进行调用这个方法,与是什么字典,没有关系,用默认的字典dict去调用也可以
15、popitem:随机删除一对key:value对
1 id_db = { 2 1111:'1', 3 2222:'2', 4 3333:'3', 5 4444:'4', 6 5555:'5', 7 } 8 9 print(id_db) 10 print(id_db.popitem()) 11 print(id_db) 12 13 14 15 #结果: 16 #{5555: '5', 4444: '4', 3333: '3', 2222: '2', 1111: '1'} #删除之前的 17 #(5555, '5') #打印出来被随机删除的key:value对 18 #{4444: '4', 3333: '3', 2222: '2', 1111: '1'} #剩余的字典
16、循环字典
简单的循环--效率低(需要有一个dict to list的转换过程),适合数据量比较小的
1 id_db = { 2 1111:'1', 3 2222:'2', 4 3333:'3', 5 4444:'4', 6 5555:'5', 7 } 8 9 for k,v in id_db.items(): 10 print(k,v) 11 12 13 14 #结果: 15 ''' 16 5555 5 17 4444 4 18 3333 3 19 2222 2 20 1111 1 21 '''
适合数据量较大
1 id_db = { 2 1111:'1', 3 2222:'2', 4 3333:'3', 5 4444:'4', 6 5555:'5', 7 } 8 9 for key in id_db: 10 print(key,id_db[key]) 11 12 13 14 #结果: 15 ''' 16 5555 5 17 4444 4 18 3333 3 19 2222 2 20 1111 1 21 '''
总结
生成字典的语法-取值-修改-插入-删除指定-取值不报错-取值报错(不使用)-更新-items(不用)-取values(不用)--打印keys--打印values
判断存在不?--setdefault--fromkeys--popitem(不用)--循环
set集合
创建集合
1 #方式一 2 se = {'123','456'} 3 print(type(se)) 4 5 6 #结果:<class 'set'> 7 8 #方式二 9 s = set() 10 print(s) 11 12 13 #结果:set() 创建一个空集合 14 #自动执行set()类里面的__init__方法 15 16 17 18 #方式三 19 li = [22,33,44,55] 20 s1 = set(li) 21 s3 = set([2,3,44,55]) 22 print(s1) 23 print(s3) 24 25 #结果: 26 # {33, 44, 22, 55} 27 #{2, 3, 44, 55} 28 #列表转换成集合
基本操作
1、创建空集合
1 s = set() 2 print(s) 3 4 5 #结果:set() 创建一个空集合 6 #自动执行set()类里面的__init__方法
2、add方法
1 s = set() 2 s.add(456) 3 print(s) 4 5 6 #结果:{456} 7 8 9 10 s = set() 11 s.add(456) 12 s.add(456) 13 s.add(456) 14 s.add(456) 15 print(s) 16 17 18 #结果:{456} 19 #添加多个一样的元素,只会默认添加一个元素
3、clear:清除所有的内容
s3 = set([2,3,44,55]) print(s3) s3.clear() print(s3) #结果: # {2, 3, 44, 55} #set()
4、copy(浅拷贝)--类似于列表的浅拷贝,可以具体参照列表的浅copy
5、difference
S1中存在S2中不存在的所有元素
S1进行调用,S2是后面加入的参数
1 A = {11,22,33} 2 B = {22,33,66} 3 4 C = A.difference(B) 5 print(C) 6 7 #结果:{11} 8 #取A中存在的,B中不存在的。
6、symmetric_difference
symmetric:对称
1 A = {11,22,33} 2 B = {22,33,66} 3 4 C = A.symmetric_difference(B) 5 print(C) 6 7 #结果:{66, 11} 8 #取A中存在的,B中不存在的;取B中存在的,A中不存在的
5跟6不改变集合A、B的值,是产生新的集合C
7、difference_update
1 A = {11,22,33} 2 B = {22,33,66} 3 4 A.difference_update(B) 5 print(A) 6 7 #结果:{11} 8 #取A中存在的B中不存在的元素,更新到A集合当中去,如果B中有A集合的元素直接去掉
8、symmetric_difference_update
1 A = {11,22,33} 2 B = {22,33,66} 3 4 A.symmetric_difference_update(B) 5 print(A) 6 7 #结果:{66,11} 8 #集合A、B中都不相同的元素到A中去
7跟8改变集合A的值
9、discard:移除指定元素
1 A = {11,22,33} 2 3 A.discard(11) 4 print(A) 5 6 #结果:{33,22} 7 #移除指定的元素
移除的指定元素不存在,照原样打出,不会报错
1 A = {11,22,33} 2 3 A.discard(55) 4 print(A) 5 6 #结果:{33, 11, 22} 7 #原样打出
10、POP删除(不太用得着)
1 #方法里面不能带参数 2 A = {11,22,33} 3 A.pop(22) 4 print(A) 5 6 7 8 #结果:TypeError: pop() takes no arguments (1 given) 9 10 11 12 A = {11,22,33} 13 A.pop() 14 print(A) 15 16 17 #结果:{11, 22} 18 #随机删除某一个元素 19 20 21 A = {11,22,33} 22 C = A.pop() 23 print(C) 24 25 26 #结果:33 27 #随机删除某一个元素,并且随机删除的元素会直接赋值给C
11、remove删除--与discord一样,但是移除的元素不存在的话会报错(推荐使用discord)
12、intersection:取两个集合的交集
A = {11,22,33}
B = {55,66,33}
C = A.intersection(B)
print(C)
#结果:{33}
#取两个集合的交集
13、intersection_update
A = {11,22,33}
B = {55,66,33}
A.intersection_update(B)
print(A)
#结果:{33}
#取两个集合的交集并更新到到A集合中去
14、isdisjoint
判断两个集合是否是并集,是的话打印出True,不是的话打印出False
A = {11,22,33}
B = {55,66,33}
print(A.isdisjoint(B))
#结果:False
A = {11,22,333}
B = {55,66,33}
print(A.isdisjoint(B))
#结果:True
15、issuperset:判断是否有父序列
A = {11,22,33}
B = {22,33}
print(A.issuperset(B))
#结果:True
#存在包含关系,打印出True
A = {11,22,333}
B = {11,66,33}
print(A.issuperset(B))
#结果:False
16、取并集:union
A = {11,22,33}
B = {22,33}
C = A.union(B)
print(C)
#结果:{33, 11, 22}
17、update:批量添加元素
接收一个可以被for 循环,可迭代的元素--批量添加元素
添加多个元素可以通过列表的方法,内部自动执行add方法添加到集合里面
for循环字符串:一个字符一个字符进行循环
add方法:一个元素一个元素添加
可迭代元素:字符串、列表、数字、元组
A = {11,22,33}
li = [44,22,66,77]
A.update(li)
print(A)
#结果:{33, 66, 11, 44, 77, 22}
#添加字符串
A = {11,22,33}
li = 'tangtang'
A.update(li)
print(A)
#结果:{33, 't', 11, 'a', 'n', 22, 'g'}
拓展
双下划线方法:自动执行
li = [11,22,33] #list __init__ li() #list __call__ li[0] #list __getitem__ li[0] = 123 #list __setitem__ def li[1] #list __delitem__ #li是一个对象,类是list 如果在对象后面加括号的话就会自动执行python定死的list对象方法(含下划线的方法)
set函数练习
需求
1、假设做一个资产采集的功能,在资产采集之前在内存里已经有保存一定的数据
2、第一个槽位插了一块8GB的内存,第二块:4GB,第三块:没有,第四块:2GB
3、将第一个内存条换成4GB的内存,拔了第四块内存插到第三个位置
4、将拔插的内存条位置进行更新
需求分析
1、利用字典来创建内存条
2、 将第一块8GB内存条换成4GB内存条
old里面有的new里面没有的--删除
new里面有的old里面没有的添加到old里面
new、old里面都有的,更新对应的值
#应该删除哪几个槽位? #old_dict存在,new_dict不存在的key #之前的操作只能操作元素,不能直接操作字典,所以需要将字典中的key转换成集合 #执行删除操作 old_dict = { '#1':8, '#2':4, '#4':2, } new_dict = { '#1':4, '#2':4, '#3':2, } #old_kyes = old_dict.keys() #old_set = set(old_kyes) #new_keys = new_dict.keys() #new_set = set(new_keys) new_set = set(new_dict.keys()) old_set = set(old_dict.keys()) remove_set = old_set.difference(new_set) #添加 add_set = new_set.difference(old_set) #更新(找两个集合的交集) updeta_set = old_set.intersection(new_set)

