
多线程 与 JUC 笔记
多线程 与 JUC 笔记
源码:Plan1ThreadsAndJUC: 多线程、JUC、JAVA spring boot实现事件监听
线程,是指正在执行的一个指令序列。
线程 5 种状态(生命周期)
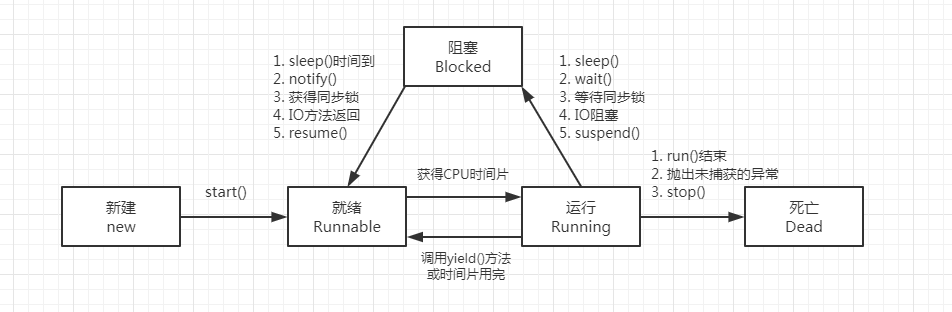
创建线程的 4 种方式
1.继承 Thread 类
2.实现 Runnable 接口
3.通过 Callable 和 Future 创建线程
4.使用线程池
Runnable 和 Callable 区别:
- 方法名不同,Runnable 是 run 方法,Callable 是 call 方法
- 返回值:Runnable 无返回值,Callable 有返回值
- 抛异常:run() 不会抛异常, call() 会抛出异常
- Callable 支持泛型,搭配 FutureTask 使用
Runnable oneRunnable = new SomeRunnable();
new Thread(oneRunnable).start();
CallableImpl callable = new CallableImpl();
FutureTask<String> futureTask = new FutureTask<>(callable);
new Thread(futureTask,"A").start();
线程方法
setPriority(int newPriority) //更改线程的优先级, 使用 MAX_PRIORITY、MIN_PRIORITY 和 NORM_PRIORITY
int getPriority() // 获得线程的优先级
static void sleep(lon mills) throw InterruptedException //指定的毫秒数内让线程休眠
void join() //等待该线程终止 (类似插队)
static void yield() //暂停当前执行的线程,并执行其他的线程(礼让)
void interrupt() //终止线程 不要用这个方式
boolean isAlive() //测试线程是否处于活动状态
void setDaemon(true) //设置守护线程 虚拟机不会等待守护线程执行完毕 用户线程执行完毕后,守护线程也就结束了
线程同步
-
synchronized同步方法 / 代码块 -
特殊域变量
volatile
• 提供了一种免锁机制,每次使用该域就要重新计算,而不是使用寄存器中的值(保证了变量在内存中的可见性);
• 不提供原子操作,也不能修饰 final 类型的变量。
• 禁止指令重排
- 可重入锁
ReentrantLock
线程通信
1.借助 Object 类的 wait()、notify() 和 notifyAll() 实现通信
2.使用 Condition 控制线程通信
private final Lock lock = new ReentrantLock();
private Condition condition_pro = lock.newCondition();
private Condition condition_con = lock.newCondition();
3.使用阻塞队列(BlockingQueue)控制线程通信
BlockingQueue 具有一个特征:
-
当生产者试图向队列中放入元素时,如果该队列已满,则线程被阻塞;
-
消费者线程试图从队列中取出元素时,如果队列已空,则该线程阻塞。
程序的两个线程通过交替向 BlockingQueue 中放入元素、取出元素,即可很好地控制线程的通信。
BlockingQueue提供如下两个支持阻塞的方法:
(1)put(E e):尝试把元素放如 BlockingQueue 中,如果该队列的元素已满,则阻塞该线程。
(2)take():尝试从BlockingQueue的头部取出元素,如果该队列的元素已空,则阻塞该线程。
BlockingQueue 继承了 Queue 接口,当然也可以使用 Queue 接口中的方法,这些方法归纳起来可以分为如下三组:
(1)在队列尾部插入元素,包括 add(E e)、offer(E e)、put(E e),当该队列已满时,这三个方法分别会抛出异常、返回 false、阻塞队列。
(2)在队列头部删除并返回删除的元素。包括 remove()、poll()、和 take()方法,当该队列已空时,这三个方法分别会抛出异常、返回 false、阻塞队列。
(3)在队列头部取出但不删除元素。包括 element()和 peek()方法,当队列已空时,这两个方法分别抛出异常、返回 false。
BlockingQueue接口包含如下5个实现类:
ArrayBlockingQueue :基于数组实现的BlockingQueue队列。
LinkedBlockingQueue:基于链表实现的BlockingQueue队列。
PriorityBlockingQueue:它并不是保准的阻塞队列,该队列调用remove()、poll()、take()等方法提取出元素时,并不是取出队列中存在时间最长的元素,而是队列中最小的元素。
它判断元素的大小即可根据元素(实现Comparable接口)的本身大小来自然排序,也可使用Comparator进行定制排序。
SynchronousQueue:同步队列。对该队列的存、取操作必须交替进行。
DelayQueue:它是一个特殊的BlockingQueue,底层基于PriorityBlockingQueue实现,不过,DelayQueue要求集合元素都实现Delay接口(该接口里只有一个long getDelay()方法),
DelayQueue根据集合元素的getDalay()方法的返回值进行排序。
线程池
最大优点是把任务的提交和执行解耦。
合理利用线程池的好处:
- 降低资源消耗。减少了线程的创建和销毁次数。
- 提高响应速度。任务到达时,不需要等线程创建,可以立即执行。
- 提高线程的可管理性。可以进行统一的分配,调优和监控。
1.使用 Executors 工厂类产生线程池
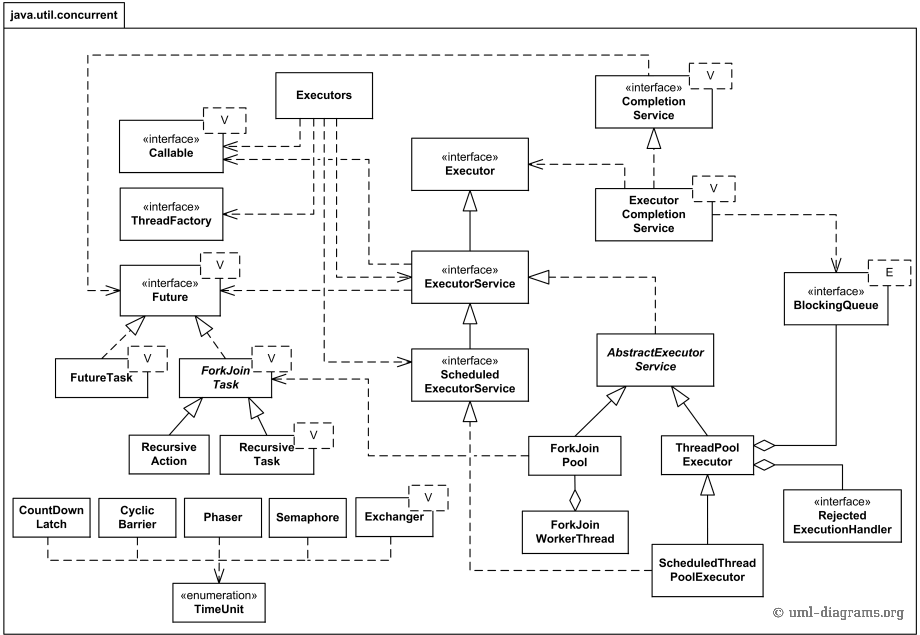
(1)使用Executors的静态工厂类创建线程池的方法如下:
1、newFixedThreadPool() :
作用:返回一个固定线程数量的线程池,该线程池中的线程数量始终不变,即不会再创建新的线程,也不会销毁已经创建好的线程。
2、newCachedThreadPool() :
作用:返回一个可以根据实际情况调整线程池中线程的数量的线程池。即该线程池中的线程数量不确定,是根据实际情况动态调整的。
3、newSingleThreadExecutor() :
作用:返回一个只有一个线程的线程池,即每次只能执行一个线程任务,多余的任务会保存到一个任务队列中,等待这一个线程空闲,当这个线程空闲了再按FIFO方式顺序执行任务队列中的任务。
4、newScheduledThreadPool() :
作用:返回一个可以控制线程池内线程定时或周期性执行某任务的线程池。可以指定线程池的大小。
5、newSingleThreadScheduledExecutor() :
作用:返回一个可以控制线程池内线程定时或周期性执行某任务的线程池。该线程池大小为1。
(2)关闭Executors创建的线程池:
原因:如果的应用程序是通过 main() 方法启动的,在这个 main() 退出之后,如果应用程序中的 ExecutorService 没有关闭,这个应用将一直运行。ExecutorService 中运行的线程会阻止 JVM 关闭。
ExecutorService.shutdown(),不再接受提交的任务,等待线程处理完任务队列中的任务才会关闭
ExecutorService.shutdownNow(),立即关闭
2.Java8增强的 ForkJoinPool 产生线程池
在Java 8中,引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,前提是使用了ForkJoinPool。ForkJoinPool需要使用相对少的线程来处理大量的任务。
比如要对1000万个数据进行排序。ForkJoinPool能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。ThreadPoolExecutor使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。
使用ThreadPoolExecutor和ForkJoinPool的性能差异:
-
ForkJoinPool 能够使用有限数量的线程来完成非常多具有父子关系的任务
-
ForkJoinPool能够实现工作窃取(Work Stealing),在该线程池的每个线程中会维护一个队列来存放需要被执行的任务。当线程自身队列中的任务都执行完毕后,它会从别的线程中拿到未被执行的任务并帮助它执行。因此,提高了线程的利用率,从而提高了整体性能。
-
对于ForkJoinPool,还有一个因素会影响它的性能,就是停止进行任务分割的那个阈值。比如在之前的快速排序中,当剩下的元素数量小于10的时候,就会停止子任务的创建。
死锁
1)死锁的四个必要条件
- 互斥条件:资源同一时间只能被同一个进程使用
- 请求与保持条件:已经得到资源的进程可以申请新的资源
- 不可剥夺条件:已经分配的资源不能从相应的进程中被强制剥夺
- 循环等待条件:系统中若干进程组成环路,该环路中每个进程都在等待相邻进程占用的资源
2)破坏死锁
-
破坏互斥条件:破坏不了,临界资源本来就用于互斥
-
破坏请求与保持条件:一次性申请完所有的资源
-
破坏不剥夺条件:线程申请不到资源的时候主动放弃持有的资源
-
破坏循环等待条件:按照统一的顺序申请资源
ThreadLocal
可以在每个线程中存储数据的数据存储类,多个线程通过同一个ThreadLocal获取到的东西是不一样的。
ThreadLocal与synchronized有本质的区别:
1、Synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。
2、Synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。
remove方法,直接将ThrealLocal 对应的值从当前相差Thread中的ThreadLocalMap中删除。为什么要删除,这涉及到内存泄露的问题。
实际上 ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,弱引用的特点是,如果这个对象只存在弱引用,那么在下一次垃圾回收的时候必然会被清理掉。
所以如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候会被清理掉的,这样一来 ThreadLocalMap中使用这个 ThreadLocal 的 key 也会被清理掉。但是,value 是强引用,不会被清理,这样一来就会出现 key 为 null 的 value。
适用场景:
JUC
java.util.concurrent 下的类就叫 JUC 类,JUC 下常用的辅助类:
-
ReentrantLock :可重入锁;
-
Semaphore :信号量;
-
CountDownLatch :计数器;
-
CyclicBarrier :循环屏障。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)