

如何估计llm的GPU显存?
如何估计llm的GPU显存?
计算本地运行 llm 所需的 GPU 显存
随着
GPT、 Llama 和 Deepseek等大型 llm 的兴起,人工智能从业者面临的最大挑战之一是弄清楚他们需要多少 GPU
显存来有效地为这些模型服务。GPU 资源昂贵,因此优化显存分配至关重要。这里通过一个简单有效的公式来估计LLM 服务所需的GPU
显存。可用于部署推理或者针对专门任务进行微调时进行有效地规划。
一.GPU 显存估算公式
为了计算 LLM 所需的 GPU 显存,可使用以下公式:
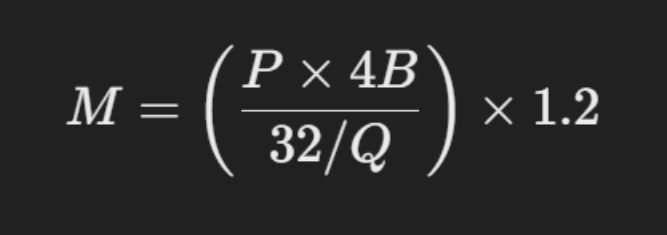
理解参数:
M:所需 GPU 显存(GB)
P:模型中的参数数量(例如, 7B 模型有 70 亿参数)
4B: 每个参数 4 字节(假设全精度 FP32)
32: 4 字节中有 32 位
Q:模型存储中每个参数使用的位数(例如, FP16 = 16 位,
INT8 = 8 位,等等)
1.2:表示额外显存需求的 20%开销,如激活存储、注意力键值
缓存等。
此公式可帮助我们确定将模型加载到GPU中需要多少 GPU 显存,同时考虑不
同的量化级别和开销。
二.逐步分解
假设我们想以 FP16 精度估计 Llama 70B 所需的 GPU 显存。
鉴于:
• P = 70B(700 亿个参数)
• Q = 16(因为我们使用的是 FP16 精度)
•开销因子= 1.2
现在,应用公式:
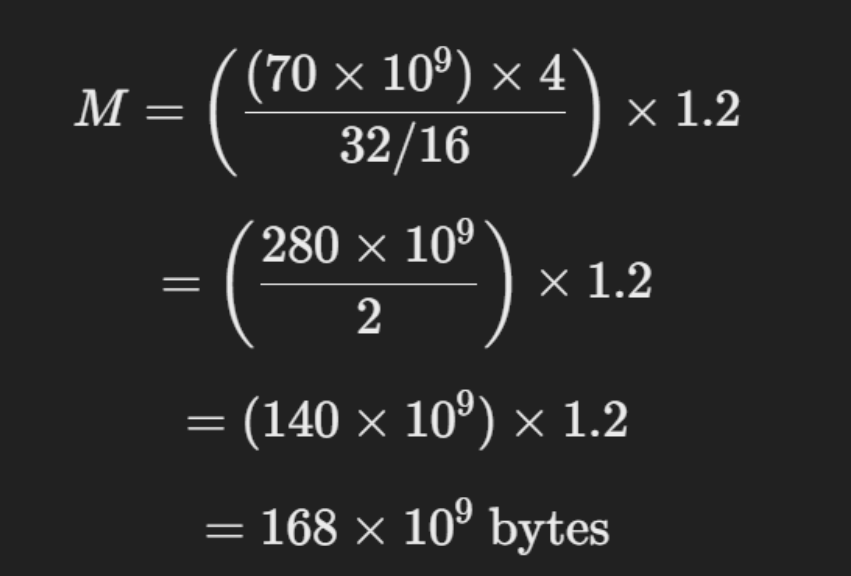
转换为 GB:
由于 1 GB = 1⁰⁹字节,我们除以 1⁰⁹:
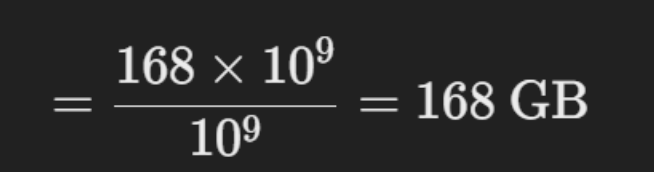
因此,要在 FP16 中加载 Llama 70B,我们将需要 168GB 的 GPU 显存。
三.量化会发生什么?
量化允许我们以较低的精度存储模型权重,从而降低显存需求。以下是
Llama 70B 在不同位格式下所需的显存:
Precision (Q) GPU 显存要求
FP32( 32 位) 336gb
FP16( 16 位) 168 GB
INT8( 8 位) 84 GB
4 位量化 42gb
四.关键点
• 较低精度的模型需要更少的 GPU 显存。
• 4 位量化是非常有效的显存,允许大量模型适合像 RTX 4090 ( 24GB
VRAM)这样的消费级 gpu。
• FP16 是平衡性能和显存使用的行业标准。
五.优化我们的模型部署
如果我们的 GPU 显存有限,这里有一些优化策略:
1. 使用量化:将我们的模型转换为 8 位或 4 位,以减少显存占用。
2. Offload to CPU:可以将部分权重卸载给 CPU,减少 GPU 显存占用。
3. 使用模型并行性:跨多个 gpu 拆分模型权重。
4. 优化 KV 缓存:减少存储的注意力键值对的数量。
5. 利用高效服务框架:使用 vLLM 或 TensorRT-LLM 等工具进行优化推
理。
六.结论
计算为
llm所需GPU 显存对于有效扩展 AI 应用至关重要。 使用上面的简单公式,我们可以估计不同精度级别所需的
VRAM,并相应地优化部署。如果我们正在处理像 Llama 70B 这样的大型模型,量化和并行是较好的选择,可以保持 GPU
成本可控。通过应用这些优化,我们可以在消费级GPU上进行LLM部署和应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号