

pdf多模态rag问答
pdf multimodal rag 【pdf多模态rag问答】
项目:https://github.com/jiangnanboy/pdf_multimodal_rag
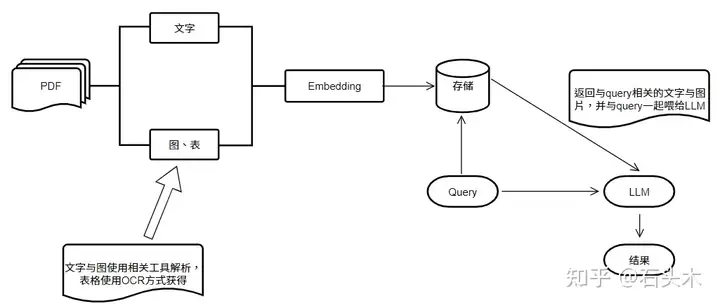
本项目对PDF文件进行解析,对其中的图、表以及文本进行Embedding化,并进行存储。根据用户query进行检索,将检索后的结果(包括图表和文本)和query输送到多模态LLM,
从而得到最终分析结果。
pdf_multimodal_rag 项目主要包含pdf解析,表格检测,文本和图表的embedding化,向量存储,向量检索,LLM问答等部分。
In this project, the PDF file is parsed, the graphs, tables and texts in it are embedded and stored.
The retrieval is carried out according to the user query, and the retrieved results (including charts and text)
and the query are fed to the multi-modal LLM to obtain the final analysis results.
The pdf_multimodal_rag project mainly contains pdf parsing, table detection, embedding of text and charts,
vector storage, vector retrieval, LLM question answering and other parts.
pdf_multimodal_rag 有以下功能:
- pdf文字及图解析(pdf parse) --> src/parse or parse_and_store_embedding.py
- pdf表格检测(pdf table detection) --> src/parse or parse_and_store_embedding.py
- text/image/table embedding --> src/parse or parse_and_store_embedding.py
- embedding存储(embedding store) --> src/store or parse_and_store_embedding.py
- embedding检索(embedding retriever) --> src/retriever or retriever_embedding_from_local.py
- LLM问答(LLM QA) --> rag_chat_from_llm.py
说明
- pdf文及图的解析利用fitz,表格的检测利用目标检测模型,下载表格检测模型https://huggingface.co/jiangnanboy/table_det
- 文本的embedding利用nomic-ai/nomic-embed-text-v1.5,图片的embedding利用nomic-ai/nomic-embed-vision-v1.5 可以自行去下载相关模型https://huggingface.co/nomic-ai
- llm问答部分可自行部署开源的多模态模型或者调用第三方多模态API
ui
【ui_web.py】
利用streamlit实现web页面:
- 上传pdf文件,并解析
- 输入查询query
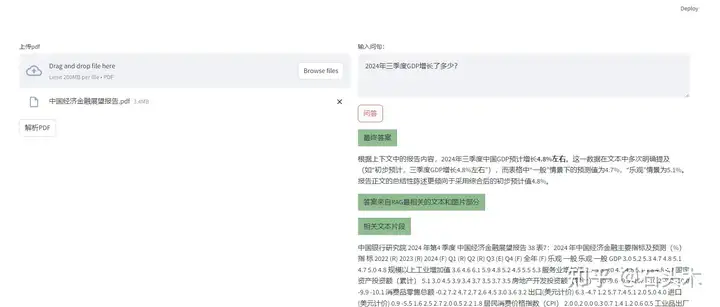
- 返回最终答案
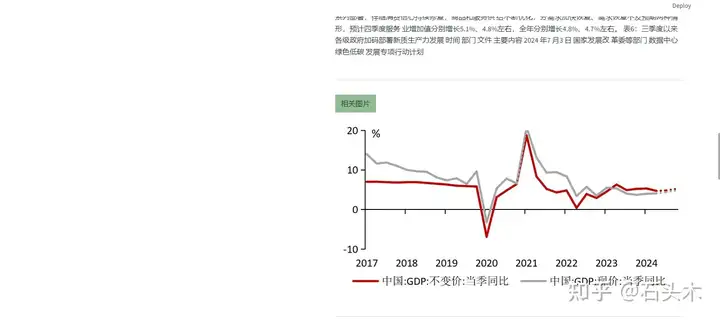
- 返回原始pdf中的相关文本及图表


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端