

小模型(SLM)的效率、性能和潜力
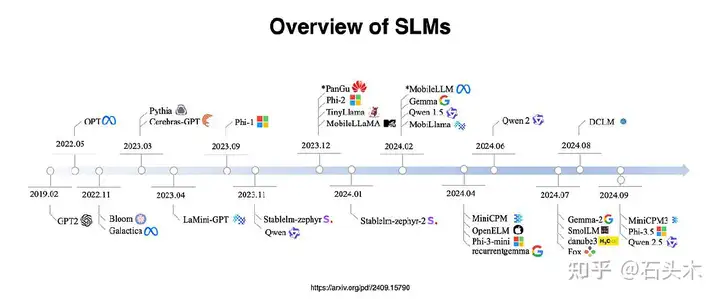
关于小语言模型
小语言模型(slm)是为在桌面、智能手机和可穿戴设备上进行资源高效部署而设计的。
其目标是使先进的机器智能能够为每个人所使用和负担得起,就像人类认知的普遍性一样。
小语言模型(slm)已经广泛集成到商业设备中。例如,最新的谷歌和三星智能手机内置了大型语言模型(LLM)服务,如 Gemini Nano,它允许第三方应用程序通过提示和模块化集成来访问 LLM 功能。
同样,iphone 和 ipad 上最新的 iOS 系统包括一个与操作系统紧密集成的设备上基础模型,既增强了性能,又增强了隐私。这种广泛采用显示了 slm 在日常技术中的潜力。
通过在个人设备上启用人工智能功能,slm 旨在使强大技术的使用民主化,使人们能够随时随地使用智能系统,而无需依赖基于云的资源。
slm 的关键见解:
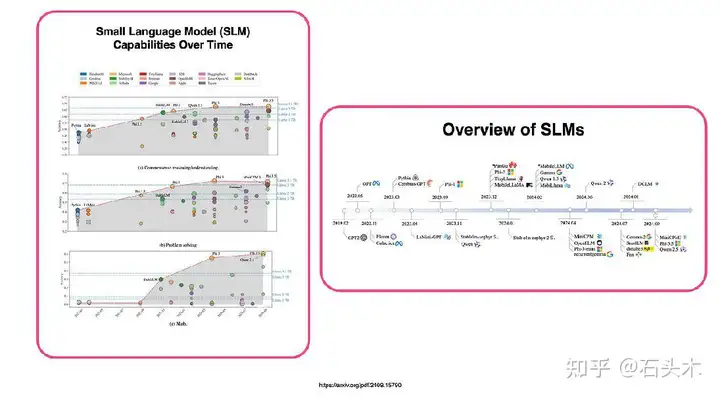
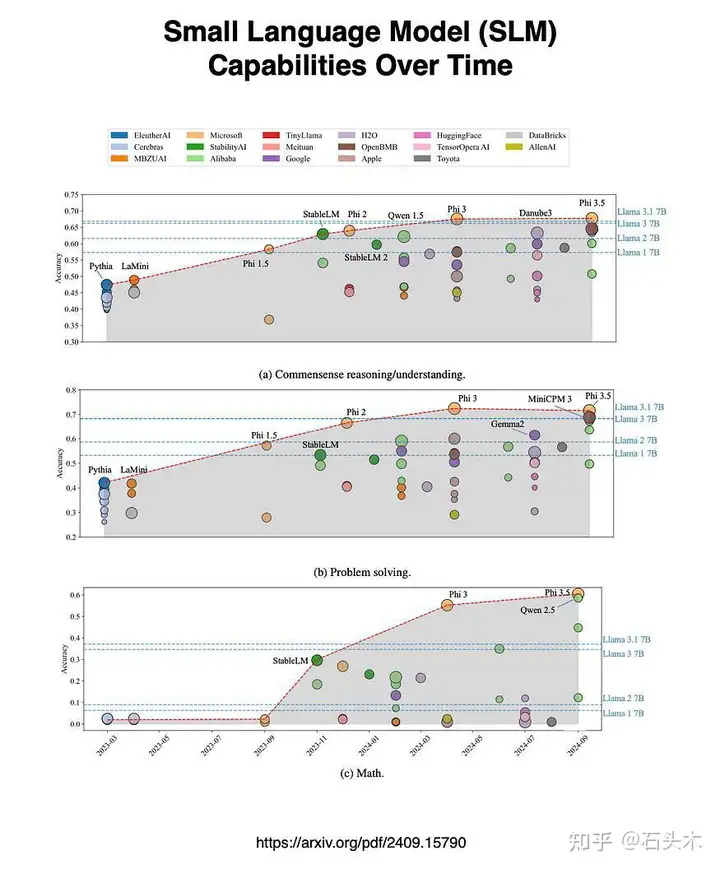
- 从 2022 年到 2024 年,slm 在语言任务上表现出了显著的性能提升,超过了 LLaMA-7B 系列,表明了在设备上解决任务的强大潜力。
- Phi 系列,特别是 Phi-3-mini 在 2024 年 9 月之前达到了领先的精度,部分原因是数据工程和微调技术。
- 虽然较大的型号通常表现更好,但像 Qwen2-1.5B 这样的较小型号在特定任务中表现出色。
- 在开源数据上训练的 slm 正在改进,但在复杂的推理任务中,特别是涉及逻辑和数学的任务,仍然落后于闭源模型。
- 大多数 slm 都具有一定程度的上下文学习,但其有效性因任务而异。虽然几乎所有模型都从任务中的上下文学习中受益匪浅。
- 模型架构会显著影响延迟和模型大小。
- 模型的架构,包括层和词汇量大小等因素,会影响其速度和内存使用。例如,Qwen1.5-0.5B 比 Qwen2-0.5B 有更多的参数,但在某些硬件上运行得更快,这表明性能取决于设备。
- 语言模型对“小”的定义是主观的,随着设备内存的增加,可能会随着时间的推移而改变,这使得将来更大的模型被认为是“小”的。
- 目前,小型语言模型的参数限制为 50 亿,因为到 2024 年 9 月,70
亿个参数模型仍主要部署在云中。 - 这种区别反映了硬件不断发展的能力和当时的实际部署限制。
- 数据质量对小语言模型(Small Language Models, slm)的性能至关重要,
在最近的研究中得到了越来越多的关注。
一般来说,数据的质量比数据的数量或特定的模型架构更重要。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律