


校对:一键修复所有错误

校对是 Gboard 的一项新功能,它使用服务器端大型语言模型(LLM),只需点击一下就可以提供无缝的句子级和段落级更正,减轻了那些喜欢专注于打字而不是检查已提交单词的快速打字者的痛点。
校对背后的系统由四个部分组成:数据生成、指标设计、模型调优和模型服务。
- 数据生成过程涉及一个精心设计的错误合成框架,该框架模拟用户输入并确保数据分布接近 Gboard 域。
- 设计用于衡量模型质量的指标包括基于 llm 的语法错误存在性检查和相同含义检查。
- 模型调整过程包括监督微调,然后是受 InstructGPT 启发的强化学习(RL)
调整。结果表明,重写任务调优和 RL 调优配方显著提高了基础模型的校对性能。
- 为了降低服务成本,该功能构建在中型 LLM PaLM2-XS 之上,经过 8 位量化后可以装入单个 TPU v5。通过桶密钥、分段、推测解码等进一步优化时延。
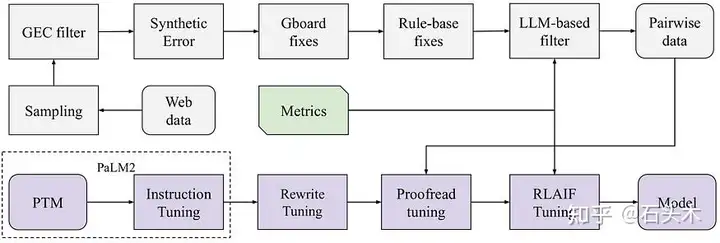
数据合成和模型调优管道
数据集
数据集中的每个项目由一个源句子和几个可能的参考句子组成。数据集准备过程包括以下几个步骤:
从 web 抓取的数据集中采样数据,并使用语法错误纠正 (Grammar Error Correction, GEC)模型对其进行处理,以修复语法错误。
将语法错误合成到源句子中,模拟真实世界的用户输入,包括:
- 字符遗漏(例如,将“hello”写成“hllo”)
- 字符插入(例如,将“hello”替换为“hhello”)
- 换位(例如,将“hello”替换为“hhello”)
- 双击(例如,将“hello”替换为“heello”)
- 省略双字符(例如,将“hello”替换为“helo”)
- 基于高斯的位置错误(例如,将“hello”误认为“jello”)
将合成错误的数据传递给 Gboard 模拟器,使用 Gboard 内置的文字解码、主动密钥校正(KC)和主动自动校正(AC)功能来修复错误。此外,启发式规则被应用于修复以下情况:
- Emoji /表情符号对齐
- 日期时间格式
- URL 模式
使用大型语言模型(LLM)过滤噪声数据,并使用精心设计的指令,以避免污染模型。数据根据各种维度进行诊断,包括:
- 参考句子仍然存在错误
- 参考句子不够流利或清楚
- 参考句的意思与源句不同
- 参考句的语气、语气或时态与源句不同
使用人类评分员标记的部分示例作为评估的黄金集。

合成数据集的一个例子。
指标
给定三个元素,输入(损坏的文本),答案(从模型中预测的候选人)和目标(基本事实),我们提出以下指标。
- EM /精确匹配率:答案与目标完全相等的比率。
- NEM /标准化精确匹配率:忽略大写和标点符号的答案等于目标的比率。
- 错误率:包含语法错误的答案的比例,由 LLM 在特定的指导下进行。
- Diff Meaning Ratio:答案与目标不具有相同含义的比例,这也是由 LLM 在特定指令下进行的。
- Good Ratio:没有语法错误且与目标意义相同的答案比例。
- 差比:答案有语法错误或与目标意义不同的比例。
模型优化
模型调优过程从 PaLM2-XS 模型开始
第一步是在包含数百个文本重写任务的 Rewrite 数据集上对模型进行微调。接下来,在一个合成数据集上对模型进行微调。使用 RLAIF,以及启发式奖励。设计了两种基于大型语言模型(LLM)的可选启发式奖励:
1.全局奖励:LLM 用于确定候选是否是损坏输入的良好修复,使用少量示例。
2.直接奖励:目标是提高 Good Ratio,所以奖励直接从语法错误检查和 diff 意义检查转换而来,两者都依赖于 LLM。示例中包含了 ground truth,并且将奖励组合起来作为最终奖励。
为了优化模型,使用了近端策略优化(PPO),其中涉及到 KL 散度,以帮助模型保留恢复原始文本的能力。
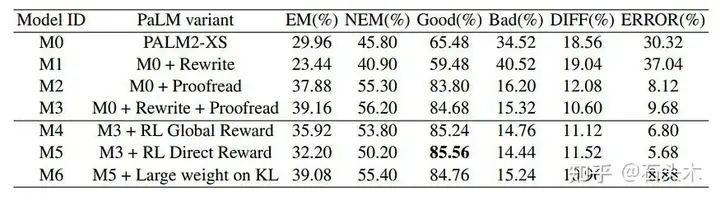
PaLM2-XS 的指标在 Golden 数据集的各个阶段进行了调优。
- 【对比 M2 和 M3】虽然在 Rewrite 数据集上进行微调会降低质量,但在
Rewrite 和 Proofread 数据集上进行顺序微调会产生最佳结果,Good ratio 为84.68%,Bad ratio 为 15.32%。
- [比较 M3、M4 和 M5]分别采用全局奖励 RL 和直接奖励 RL,PaLm2-XS模型的 Bad ratio 可相对提高 0.56%和 0.88%。
- [比较 M5 和 M6] RL 降低了 EM 和 NEM 比率,表明正确和错误情况下的输出分布发生了变化。虽然增加 KL 散度惩罚可以缓解这种情况,但它并没有显著提高好/坏比率。
模型服务
Proofread 模型使用谷歌的 TPUv5e 芯片提供服务,该芯片具有 16GB HBM 和 8
位量化,可以在不影响质量的情况下减少内存占用和延迟。该模型专为在聊天应用程序中部署而设计,这些应用程序的平均句子长度通常很短(少于 20 个单词)。为了处理较长的文档,该模型将文档分割成段落并并行处理。
该方法还结合了针对用户历史模式量身定制的推测解码和启发式起草人模型。使用推测草案处理初始输入,并根据需要使用外部起草人模型。这种方法降低了操作成本,提高了效率。
对该系统进行了实证评估,以 TPU 周期衡量,每个服务请求的中位延迟减少了39.4%。这突出了该系统在实时应用中的效率。

