

教小模型进行推理
https://arxiv.org/abs/2212.08410
思维链提示在基础层面上是如此成功,以至于它产生了一些被称为 x
链现象的东西。谷歌研究院探索了如何使用 llm 为现有数据集生成
CoT 数据本体,然后如何在 CoT 上微调较小的语言模型。
介绍
众所周知,思维链提示提高了大型语言模型的推理能力。
谷歌断言,推理能力只出现在具有至少数百亿参数的模型中。谷歌的这项研究探索了通过知识蒸馏将这些能力转移到更小的模型上。
他们利用一个更大的教师模型的思维链输出对一个学生模型进行了微调。
来自谷歌的研究人员发现,这种方法提高了算术、常识和符号推理数据集的任务性能。
思维链(CoT)
思维链(CoT)提示教导语言模型(lm)将推理任务分解为一系列中间步骤。
研究表明,这种提示显著提高了跨常识、符号和数学推理数据集的大型语言模型(llm)的任务准确性。
然而,较小的 lm 的推理能力在 CoT 提示下并没有提高,大多产生非逻辑的CoT。值得注意的是,CoT 提示甚至降低了小于 100 亿个参数的模型的准
确性。
研究将其归因于语义理解和符号映射等能力,这些能力仅在更大规模的模型中出现。
该方法
谷歌研究提出了 CoT(思维链)知识蒸馏的两步管道。
CoT 推理注释
- 使用教师模型,如 PaLM 540B 或 GPT-3 175B,用 CoT 推理注释现有的监督数据集。
- 使用 8 个示例执行少镜头提示以生成 CoT,调整提示以在问题之后和示例 CoT 之前提供目标答案。这有助于纠正小错误。
- 根据目标答案剔除不正确的 CoT,保证质量。
微调学生模型
- 使用教师强迫对学生模型进行微调。
- 提供问题作为输入,CoT 和答案作为目标。
- 这种训练消除了微调过程中提示的需要。
所提出方法的概述如下图所示
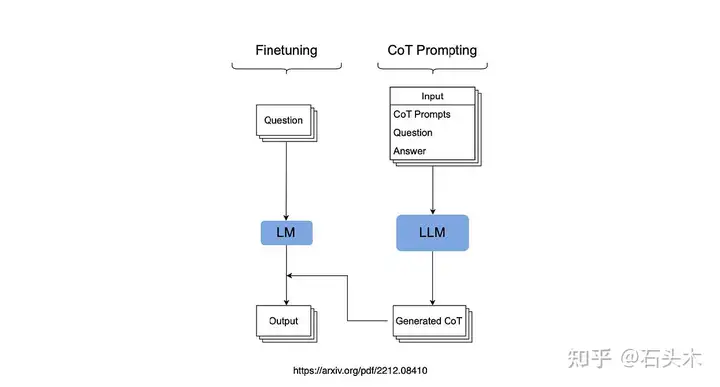
这张图是所提出方法的概述
总之
这项研究又是一个很好的例子,证明了快速工程技术是有效的,正在进入语言模型训练。因此,提示工程正在影响训练数据拓扑。
这也是 LLM 用于生成或增强小型语言模型的训练数据的另一个例子。
第三,第一步涉及使用教师模型生成的 CoT 推理对现有的监督数据集进行
注释。已经有许多研究通过人工注释和监督过程创建了非常细粒度、细粒
度的数据。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律