

时间序列分析的代理检索-增强生成
https://arxiv.org/abs/2408.14484 Agentic Retrieval-Augmented Generation for Time Series Analysis

该方法引入了一种利用多智能体 RAG 系统进行时间序列分析的新框架。该框架 解决了时间序列数据中复杂的时空依赖关系和分布变化等挑战。它采用分层架构, 其中主代理将任务委托给专门的子代理,每个子代理针对特定的时间序列任务进 行微调。这些子代理使用较小的预训练语言模型,并从共享存储库中检索相关提 示,以增强预测。模块化的多代理 RAG 方法提供了灵活性,并在各种时间序列 任务中实现了最先进的性能。
问题公式化
数据集由 N 个单变量时间序列组成,每个序列在 T 个时间戳上收集。它被表示为 一个数据矩阵。有四个任务:
• 预测:使用滑动窗口从前面的步骤构建子序列,以预测下一步的未来值。
• 缺失数据输入(Missing Data Imputation):一个二元掩模矩阵识别缺失数 据,观察到的样本通过利用滑动窗口内的时空依赖关系来估计缺失值。
• 异常检测:通过将当前行为与训练期间的正常模式进行比较来检测异常。使 用滑动窗口方法预测未来值,并计算异常分数以标记与移动平均最大异常值 的偏差。
• 分类:应用无监督 K-means 聚类来识别数据中的聚类。使用滑动窗口方法 根据过去的时间步长预测未来的聚类标签。
方法
动态提示机制
动态提示机制通过解决非平稳性和分布变化来增强时间序列建模。它改进了使用 固定窗口长度的传统方法,这些方法可能会错过短期或长期依赖关系。该方法从 编码历史模式(如季节性、周期性、不规则性等)的键值对共享池中检索相关提示。 输入时间序列被投射到向量空间中,余弦相似度用于将它们与最相关的提示进行 匹配。这些提示与输入数据相结合,以改进预测,使模型能够适应和利用过去的 知识,在不同的数据集上获得更好的性能。
微调/偏好优化 SLM
预训练的小型语言模型,如 Google 的 Gemma 和 Meta 的 lama-3,受到 8K token 上下文窗口的限制,这阻碍了它们处理长输入序列的能力。为了解决这个问题, 引入了两层注意机制(分组和邻居注意),允许 slm 捕获远程依赖关系而无需微调, 从而提高了扩展文本序列的性能。虽然针对特定任务对 slm 进行微调可以提高性 能,但使用参数有效的微调技术对扩展的 32K 令牌上下文窗口进行指令调优可以 提高它们处理时间序列任务的能力。此外,直接 DPO 用于通过随机屏蔽 50%的 数据并执行二元分类来预测正确的特定于任务的结果,从而将 SLM 预测导向更 可靠的特定于任务的结果。
实验
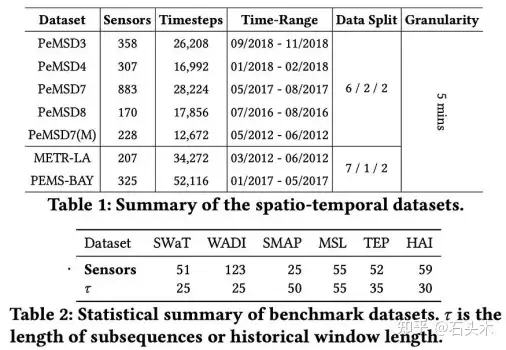

agenic-rag 框架变体在预测的七个基准数据集以及异常检测任务上对基线方法 进行了评估。结果表明,所提出的框架在这些数据集上的性能明显优于基线方法。
我们进行了消融研究,以评估 agenic-rag 框架内各个成分的贡献。该研究分析 了移除关键组件的影响:动态提示机制、子代理专门化、指令调整和 DPO。结果 表明,在跨多个数据集的时间序列预测、异常检测和分类任务中,完整框架始终 优于消融版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号