时间序列预测(商品销量预测)
一.概要
此项目将围绕一个时间序列预测任务展开。该任务是Kaggle上的一个比赛,M5 Forecasting - Accuarcy(https://www.kaggle.com/c/m5-forecasting-accuracy/notebooks )。M5的赛题目标是预测沃尔玛各种商品在未来28天的销量。本案例使用前1913天的数据作为训练数据,来预测1914天到1941天的销量。并且,我们只对最细粒度的30490条序列进行预测。 训练数据从kaggle中自行下载:
- calendar.csv - Contains information about the dates on which the products are sold.
- sales_train_validation.csv - Contains the historical daily unit sales data per product and store [d_1 - d_1913]
- sample_submission.csv - The correct format for submissions. Reference the Evaluation tab for more info.
- sell_prices.csv - Contains information about the price of the products sold per store and date.
- sales_train_evaluation.csv - Includes sales [d_1 - d_1941] (labels used for the Public leaderboard)
以上数据下载后放入resources/advanced下,并在properties.properties中配置一下文件名和路径,以供程序读取和处理数据。
1.数据处理以及特征工程利用java spark进行提取,见TimeSeries.java。
2.模型的训练及预测利用python lightgbm进行操作,见time_series.ipynb,data.7z下是spark处理好的数据。
二.特征工程代码解读,完整见项目中代码注释
/** * 分析和挖掘数据 * @param session */ public static void analysisData(SparkSession session) { // 一.数据集 /* 1.这里是历史销量sales_train_validation数据 +--------------------+-------------+---------+-------+--------+--------+---+---+---+---+---+---+---+---+- | id| item_id| dept_id| cat_id|store_id|state_id|d_1|d_2|d_3|d_4|d_5|d_6|d_7|d_8|d_9|d_10|... +--------------------+-------------+---------+-------+--------+--------+---+---+---+---+---+---+---+---+---+----+ |HOBBIES_1_001_CA_...|HOBBIES_1_001|HOBBIES_1|HOBBIES| CA_1| CA| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0|... |HOBBIES_1_002_CA_...|HOBBIES_1_002|HOBBIES_1|HOBBIES| CA_1| CA| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0|... |HOBBIES_1_003_CA_...|HOBBIES_1_003|HOBBIES_1|HOBBIES| CA_1| CA| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0|... +--------------------+-------------+---------+-------+--------+--------+---+---+---+---+---+---+---+---+---+----+ schema: |-- id: string (nullable = true) |-- item_id: string (nullable = true) |-- dept_id: string (nullable = true) |-- cat_id: string (nullable = true) |-- store_id: string (nullable = true) |-- state_id: string (nullable = true) |-- d_1: integer (nullable = true) |-- d_2: integer (nullable = true) |-- d_3: integer (nullable = true) |-- d_4: integer (nullable = true) |-- ...... */ String salesTrainValidationPath = TimeSeries.class.getClassLoader().getResource(PropertiesReader.get("advanced_timeseries_sales_train_validation_csv")).getPath().replaceFirst("/", ""); Dataset<Row> salesTVDataset = session.read() .option("sep", ",") .option("header", true) .option("inferSchema", true) .csv(salesTrainValidationPath); /*首先,我们只留下salesTVDataset中的历史特征值,删去其他列。 +---+---+---+---+---+---+---+---+---+----+ |d_1|d_2|d_3|d_4|d_5|d_6|d_7|d_8|d_9|d_10| +---+---+---+---+---+---+---+---+---+----+ | 0| 0| 0| 0| 0| 0| 0| 0| 0| 0|... | 0| 0| 0| 0| 0| 0| 0| 0| 0| 0|... | 0| 0| 0| 0| 0| 0| 0| 0| 0| 0|... +---+---+---+---+---+---+---+---+---+----+ */ Column[] columns = new Column[1913]; int index = 0; for(String column : salesTVDataset.columns()) { if(column.contains("d_")) { columns[index] = functions.col(column); index++; } } Dataset<Row> xDataset = salesTVDataset.select(columns); /* 2.这里是日历信息calendar数据 +----------+--------+--------+----+-----+----+---+------------+------------+------------+------------+-------+-------+-------+ | date|wm_yr_wk| weekday|wday|month|year| d|event_name_1|event_type_1|event_name_2|event_type_2|snap_CA|snap_TX|snap_WI| +----------+--------+--------+----+-----+----+---+------------+------------+------------+------------+-------+-------+-------+ |2011-01-29| 11101|Saturday| 1| 1|2011|d_1| null| null| null| null| 0| 0| 0| |2011-01-30| 11101| Sunday| 2| 1|2011|d_2| null| null| null| null| 0| 0| 0| |2011-01-31| 11101| Monday| 3| 1|2011|d_3| null| null| null| null| 0| 0| 0| +----------+--------+--------+----+-----+----+---+------------+------------+------------+------------+-------+-------+-------+ schema: |-- date: string (nullable = true) |-- wm_yr_wk: integer (nullable = true) |-- weekday: string (nullable = true) |-- wday: integer (nullable = true) |-- month: integer (nullable = true) |-- year: integer (nullable = true) |-- d: string (nullable = true) |-- event_name_1: string (nullable = true) |-- event_type_1: string (nullable = true) |-- event_name_2: string (nullable = true) |-- event_type_2: string (nullable = true) |-- snap_CA: integer (nullable = true) |-- snap_TX: integer (nullable = true) |-- snap_WI: integer (nullable = true) */ String calendarPath = TimeSeries.class.getClassLoader().getResource(PropertiesReader.get("advanced_timeseries_calendar_csv")).getPath().replaceFirst("/", ""); Dataset<Row> calendarDataset = session.read() .option("sep", ",") .option("header", true) .option("inferSchema", true) .csv(calendarPath); /* 3.商品每周的价格信息sell_prices +--------+-------------+--------+----------+ |store_id| item_id|wm_yr_wk|sell_price| +--------+-------------+--------+----------+ | CA_1|HOBBIES_1_001| 11325| 9.58| | CA_1|HOBBIES_1_001| 11326| 9.58| | CA_1|HOBBIES_1_001| 11327| 8.26| +--------+-------------+--------+----------+ schema: |-- store_id: string (nullable = true) |-- item_id: string (nullable = true) |-- wm_yr_wk: integer (nullable = true) |-- sell_price: double (nullable = true) */ // String sellPricesPath = TimeSeries.class.getClassLoader().getResource(PropertiesReader.get("advanced_timeseries_sell_prices_csv")).getPath().replaceFirst("/", ""); // Dataset<Row> sellPricesDataset = session.read() // .option("sep", ",") // .option("header", true) // .option("inferSchema", true) // .csv(sellPricesPath); // (1).测试集,我们只是计算了第1914天的数据的特征。这只些特征只能用来预测1914天的销量,也就是说,实际上是我们的测试数据。 int targetDay = 1914; // 使用历史数据中最后的7天构造特征 int localRange = 7; // 由于使用前1913天的数据预测第1914天,历史数据与预测目标的距离只有1天,因此predictDistance=1 // 如果使用前1913天的数据预测第1915天,则历史数据与预测目标的距离有2天,因此predictDistance=2,以此类推 int predictDistance = 1; Dataset<Row> testDataset = getTestDataset(salesTVDataset, calendarDataset, xDataset, targetDay, predictDistance); // (2).训练集,为了构造训练数据,我们对1914天之前的日期进行同样的特征计算操作,并附上它们的当天销量作为数据标签。 int trainingDataDays = 7; // 为了简便,现只取7天的数据作训练集 Dataset<Row> trainDataset = getTrainDataset(salesTVDataset, calendarDataset, xDataset, trainingDataDays, targetDay, predictDistance); String salesTrainEvaluationPath = TimeSeries.class.getClassLoader().getResource(PropertiesReader.get("advanced_timeseries__sales_train_evaluation_csv")).getPath().replaceFirst("/", ""); Dataset<Row> labelDataset = session.read() .option("sep", ",") .option("header", true) .option("inferSchema", true) .csv(salesTrainEvaluationPath); // (3).测试集的label Dataset<Row> testLabelDataset = getTestDatasetLabel(labelDataset, targetDay); // (4).训练集的label Dataset<Row> trainLabelDataset = getTrainDatasetLabel(labelDataset, targetDay, trainingDataDays, predictDistance); // (5).保存为csv文件,供python lightgbm训练 // 保存test dataset String testDatasetCsvPath = "E:\\idea_project\\spark_data_mining\\src\\main\\resources\\dataalgorithms\\advanced\\timeseries_data\\testdata.csv"; saveCsv(testDataset, testDataset.columns(), testDatasetCsvPath); // 保存train dataset String trainDatasetCsvPath = "E:\\idea_project\\spark_data_mining\\src\\main\\resources\\dataalgorithms\\advanced\\timeseries_data\\traindata.csv"; saveCsv(trainDataset, trainDataset.columns(), trainDatasetCsvPath); // 保存test label String testLabelCsvPath = "E:\\idea_project\\spark_data_mining\\src\\main\\resources\\dataalgorithms\\advanced\\timeseries_data\\testlabel.csv"; saveCsv(testLabelDataset, testLabelDataset.columns(), testLabelCsvPath); // 保存train label String trainLabelCsvPath = "E:\\idea_project\\spark_data_mining\\src\\main\\resources\\dataalgorithms\\advanced\\timeseries_data\\trainlabel.csv"; saveCsv(trainLabelDataset, trainLabelDataset.columns(), trainLabelCsvPath); }
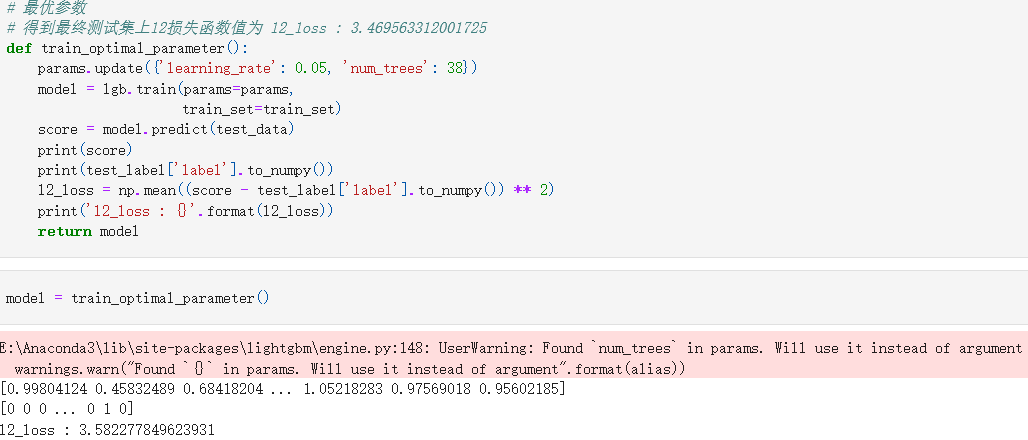
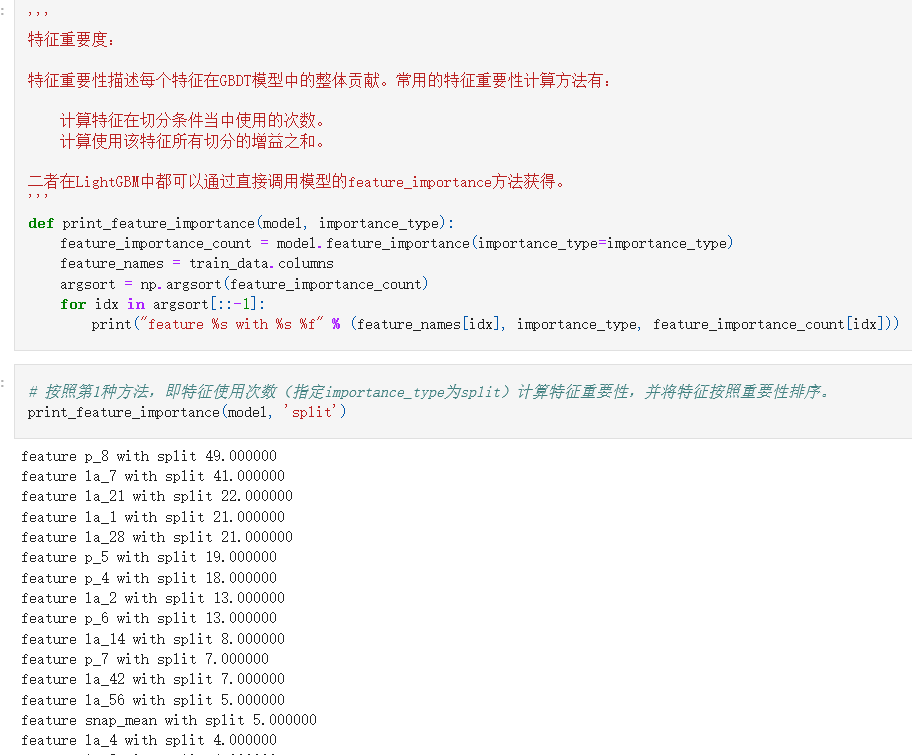
三.模型训练