

LFM矩阵分解
对矩阵R的近似求解:
1.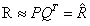
其中,P矩阵维度:N*K;Q矩阵维度:M*K。前者为User在K维潜因子空间的表示;后者为Item在K维潜因子空间的表示。
2.预测评分,或者説近似评分 为:
为:
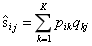
3. 损失函数为平方误差+L2正则项:
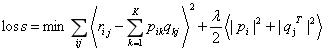 ,其中
,其中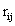 为真实评分。
为真实评分。
4.用梯度下降求解:
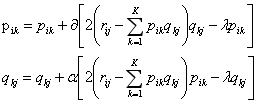
其中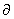 是学习率,
是学习率,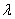 是正则化参数。
是正则化参数。
5.代码如下,完整代码(预处理等,数据来自movielens, ml-100k)https://github.com/jiangnanboy/recommendation_methods/blob/master/com/sy/reco/recommendation/matrix_factorization/lfm.py
import numpy as np import math import random ''' LFM(latent factor model)隐语义推荐模型,利用矩阵分解来拟合原始评分矩阵,训练得到U,I矩阵 对user-item评分矩阵进行分解为U、I矩阵,再利用随机梯度下降(函数值下降最快的方向)迭代求解出U,I矩阵,最后用U*I预测得出user对item的预测评分 这里U矩阵是user对每个隐因子的偏好程度,I矩阵是item在每个隐因子中的分布 最小化误差平方函数,加入正则化是为了减少过拟合 ''' class LFM(): ''' 初始化ratingMatrix,F, alpha, λ ratingMatrix:评分矩阵 F:隐因子数目 alpha:学习速率 λ:正则化参数,以防过拟合 ''' def __init__(self,ratingMatrix,F,alpha,λ): self.ratingMatrix=ratingMatrix self.F=F self.alpha=alpha self.λ=λ #对U,I矩阵初始化,随机填充,根据经验随机数与1/sqrt(F)成正比 def __initPQ(self,userSum,itemSum): self.U=np.zeros((userSum,self.F)) self.I=np.zeros((itemSum,self.F)) for i in range(userSum): self.U[i]=[random.random()/math.sqrt(self.F) for x in range(self.F)] for i in range(itemSum): self.I[i]=[random.random()/math.sqrt(self.F) for x in range(self.F)] #预测打分,用户的行与项目的列 def predict(self,user,item): I_T=self.I.T#项目矩阵转置 pui=np.dot(self.U[user,:],I_T[:,item]) return pui #迭代训练分解,max_iter:迭代次数 def iteration_train(self,max_iter): userSum = len(self.ratingMatrix) # 用户个数 itemSum = len(self.ratingMatrix[0]) # 项目个数 self.__initPQ(userSum,itemSum)#初始化U,I矩阵 for step in range(max_iter): for user in range(userSum): for item in range(itemSum): if self.ratingMatrix[user,item]>0:#未评分的项目不参与计算 eui=self.ratingMatrix[user,item]-self.predict(user,item)#真实值减去预测的值 for f in range(self.F): self.U[user,f]+=self.alpha*(self.I[item,f]*eui-self.λ*self.U[user,f])#更新 self.I[item,f]+=self.alpha*(self.U[user,f]*eui-self.λ*self.I[item,f])#更新 #self.alpha*=0.9#对学习参数进行衰减,使用算法尽快收敛 return np.round(np.dot(self.U,self.I.T),0)#返回全部,两个矩阵相乘 #预测误差训练,convergence:误差收敛,小于这个误差 def convergence_train(self,convergence): userSum = len(self.ratingMatrix) # 用户个数 itemSum = len(self.ratingMatrix[0]) # 项目个数 self.__initPQ(userSum, itemSum) flag=True while flag: for user in range(userSum): for item in range(itemSum): if self.ratingMatrix[user,item]>0:#未评分的项目不参与计算 eui=self.ratingMatrix[user,item]-self.predict(user,item)#真实值减去预测的值 for f in range(self.F): self.U[user,f]+=self.alpha*(self.I[item,f]*eui-self.λ*self.U[user,f])#更新 self.I[item,f]+=self.alpha*(self.U[user,f]*eui-self.λ*self.I[item,f])#更新 #self.alpha*=0.9#对学习参数进行衰减,使用算法尽快收敛 cost=0#误差 for user in range(userSum): for item in range(itemSum): if self.ratingMatrix[user,item]>0: cost+=(1/2)*math.pow(self.ratingMatrix[user,item]-np.dot(self.U[user],self.I.T[:,item]),2) for f in range(self.F): cost+=(1/2)*self.λ*(math.pow(self.U[user,f],2)+math.pow(self.I[item,f],2)) if cost<convergence: flag=False return np.dot(self.U,self.I.T)#返回全部,两个矩阵相乘

