
Spark学习(四) -- Spark作业提交
标签(空格分隔): Spark
作业提交
先回顾一下WordCount的过程:
sc.textFile("README.rd").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
- 步骤一:
val rawFile = sc.textFile("README.rd") - texyFile先生成
HadoopRDD-->MappedRDD; - 步骤二:
val splittedText = rawFile.flatMap(line => line.split(" ")) - flatMap将原来的
MappedRDD-->FlatMappedRDD; - 步骤三:
val wordCount = splittedText.map(word => (word, 1)) - 将词语生成相应的键值对,
FlatMappedRDD-- >MappedRDD; - 步骤四:
val reduceJob = wordCount.reduceByKey(_+_) - 其中,
reduceByKey不是MappedRDD的方法。 - Scala将MappedRDD隐式转换为PairRDDFunctions
- 步骤五:触发执行
reduceJob.foreach(println) - foreach会调用sc.runjob,从而生成Job并提交到Spark集群中运行。
ClosureCleaner的主要功能
当Scala在创建一个闭包时,需要先判定那些变量会被闭包所使用并将这些需要使用的变量存储在闭包之内。但是有时会捕捉太多不必要的变量,造成带宽浪费和资源浪费,ClosureCleaner则可以移除这些不必要的外部变量。
经常会遇到Task Not Serializable错误,产生无法序列化的原因就是在RDD的操作中引用了无法序列化的变量。
作业执行
作业的提交过程主要涉及Driver和Executor两个节点。
在Driver中主要解决一下问题:
- RDD依赖性分析,以生成DAG;
- 根据RDD DAG将Job分割为多个Stage;
- Stage一经确认,即生成相应的Task,将生成的Task分发到Executor执行。

(对于WordCount程序来说,一直到foreach()阶段才会被提交,分析,执行!!)
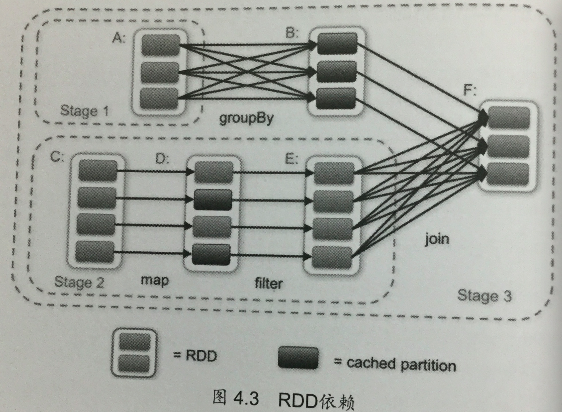
依赖性分析及Stage划分
Spark中的RDD之间的依赖分为窄依赖和宽依赖。
- 窄依赖是指父RDD的所有输出都会被指定的子RDD使用,也就是输出路径是指定的;
- 宽依赖是指父RDD的输出由不同的子RDD使用,输出路径不固定。
将会导致窄依赖的Transformation有:
- map
- flatmap
- filter
- sample
将会导致宽依赖的Transformation有:
- sortByKey
- reduceByKey
- groupByKey
- cogroupByKey
- join
- cartensian
Scheduler会计算RDD之间的依赖关系,将拥有持续窄依赖的RDD归并到同一个Stage中,而宽依赖则作为划分不同Stage的判断标准。其中,handleJobSubmitted和submitStage主要负责依赖性分析,对其处理逻辑做进一步的分析。
handleJobSubmitted -- 生成finalStage并产生ActiveJob
finalStage = new Stage(finalRDD, partitions.size, None, jobId, callSite); //生成finalStage
val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties) //根据finalStage产生ActiveJob
newStage -- 创建一个新的Stage
private def newStage(rdd:RDD[_], numTasks:Int, shuffleDep:Option[shuffleDependency[_,_,_]], jobId:Int, callSite:CallSite) : Stage = {
val stage = new Stage(id,rdd, numTasks, shuffleDep, getParentStages(rdd, jobId), jobId, callSite)
}
//参数含义:id -- Stage的序号,数字越大,优先级越高
//rdd:Rdd[_] -- 归属本Stage的最后一个rdd
//numTasks -- 创建的Task数目,等于父rdd的输出Partition的数目
//parents -- 父Stage列表
也就是说,在创建Stage的时候,已经清楚该Stage需要从多少不同的Partition读入数据,并写出到多少个不同的Partition中,即输入与输出的个数已经明确。
submitStage -- 递归完成所依赖的Stage然后提交
-
所依赖的Stage是否都已经完成,如果没有则先执行所依赖的Stage;
-
如果所依赖的Stage已经完成,则提交自身所处的Stage。
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if(jobId.isDefined) {
....
//依次处理所依赖的没有完成的Stage
} else {
abortStage(stage, "No active job for stage " + stage.id) //提交自身的Stage
}
}
getMissingParentStage -- 通过图的遍历,找出依赖的所有父Stage
private def getMissingParentStage(stage: Stage) : List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
}
Stage的划分是如何确定的呢? -- 重要的判断依据是是否存在ShuffleDependency,如果有则创建一个新的Stage。
如何判断是否存在ShuffleDependency呢? -- 取决于RDD的转换。ShuffledRDD, CoGroupedRDD, SubtractedRDD都会返回ShuffleDependency。
getDependencies -- 对于所创建的RDD,明确其Dependency类型
override def getDependencies: Seq[Dependency[_]] = {
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}
Stage划分完毕就会明确以下内容:
1) 产生的Stage需要从多少个Partition中读取数据;
2) 产生的Stage会生成多少个Partition -- 决定需要产生多少不同的Task;
3) 产生的Stage是否属于ShuffleMap类型 -- 决定生成的Task类型。
Spark中共分2种不同的Task:ShuffleMap和ResultTask。
Actor Model和Akka -- 消息交互机制
在作业提交及执行期间,Spark会产生大量的消息交互,那么这些信息如何进行交互的呢?
Actor Model
- Actor Model最适合用于解决并发编程问题。
- 每个Actor都是一个独立的个体,它们之间没有任何继承关系,所有的交互通过消息传递完成;
- 每个Actor的行为只有3种:消息接收;消息处理;消息发送;
- 为啥不适用共享内存的方式来进行信息交互呢?
- 共享内存会导致并发问题,为了解决状态不一致,要引入锁,对锁的申请处理不好又容易形成死锁,同时性能会下降!
HelloWorld in Akka:
import akka.actor.Actor
import akka.actor.ActorSystem
import akka.actor.Props
class HelloActor extends Actor {
def receive = {
case "hello" => println("hello back at you")
case _ => println("huh?")
}
}
object Main extends App {
val system = ActorSystem("HelloSystem")
//default Actor constructor
val helloActor = System.actorOf(Props[HelloActor], name = "helloactor")
helloActor ! "hello"
helloActor ! "dias"
}
注意:
- 首先要创建一个Actor;
- 消息发送要使用
!; - Actor中必须实现
receive函数来处理接收到的消息。
任务创建和分发
- Spark将由Executor执行的Task分为
ShuffleMapTask(Map)和ResultTask(Reduce)两种; - 每个Stage生成Task的时候,根据Stage中的
isShuffleMap标记确定Task的类型,如果标记为True则创建shuffleMapTask,否则创建ResultTask; submitMissingTasks负责创建新的Task(根据isShuffleMap标志来确定是哪种Task,然后确定Stage的输出和输出Partition);- 一旦任务任务类型及任务个数确定后,由Executor启动相应的线程来执行;
makeOffers -- 处理DriverActor接收到的消息信号
TaskschedulerImpl发送ReviveOffers消息给DriverActor,DriverActor接收到消息后,调用makeOffers处理消息;
def makeOffers() {
launchTasks(scheduler.resourceOffers(
executorHost.toArray.map{case(id, host) => new WorkerOffer(id, host, freeCores(id))}))
}
makeOffers的处理逻辑为:
- 找到空闲的Executor,分发的策略是随机分发,尽可能的将任务平摊到每个Executor;
- 如果有空闲额Executor,就将任务列表中的部分任务利用launchTasks发送给指定的Executor。
resourceOffers -- 任务分发
SchedulerBackend -- 将新创建的Task分发给Executor
LaunchTasks -- 发送指令
TaskDescription -- 完成序列化
任务执行
- LaunchTask消息被Executor接收,Executor会使用launchTask对给消息进行处理;
- 如果Executor没有被注册到Driver,即使接收到launchTask指令,也不会做任何处理。
launchTask
//CoarseGrainedSchedulerBackend.launchTasks
def launchTasks(context: ExecutorBackend, taskId: Long, serializedTask: ByteBuffer) {
val tr = new TaskRunner(context, taskId, serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
TaskRunner -- 反序列化
updateDependencies -- 解决依赖性问题
Shuffle Task
TaskRunner会启动一个新的线程,如何在run中调用用户自己定义的处理函数呢?作用于RDD上的Operation是如何真正起作用的呢?
TaskRunner.run
|_Task.run
|_Task.runTask
|_RDD.iterator
|_RDD.computeOrReadCheckpoint
|_RDD.compute
Reduce Task
Task在执行的时候,会产生大量的数据交互,这些数据可以分成3种不同的类型:
1)状态相关,如StatusUpdate;
2)中间结果;
3)计算相关的数据Metrics Data.
ShuffleMapTask和ResultTask返回的结果有什么不同:
ShuffleMapTask需要返回MapStatus,而ResultTask只需要告知是否已经成功完成执行;ScheduleBack接收到Executor发送过来的StatusUpdate;ScheduleBackend接收到StatusUpdate之后:如果任务已经成功处理,则将其从监视列表中删除。如果整个作业都完成,将占用的资源释放;TaskSchedulerImpl将当前顺利完成的任务放入完成队列,同时取出下一个等待运行的Task;DAGSchedule中的handleTaskCompletion,会针对ResultTask和ShuffleMapTask区别对待结果:- 如果ResultTask执行成功,
DAGSchedule会发出TaskSucced来通知对整个作业执行情况感兴趣的监听者
Checkpoint和Cache -- 存储中间结果
出于容错性及效率方面的考虑,有时需要将中间结果进行持久化保存,可以方便后面再次利用到该RDD时不需要重新计算。
中间结果的存储有两种方式:Checkpoint 和 Cache
- Checkpoint将计算结果写入到HDFS文件系统中,但不会保存RDD Lineage;
- Checkpoint有两种类型:Data Checkepoint 和 Metadata Checkpoint;
- Cache则将数据缓存到内存,如果内存不足时写入到磁盘,同时将Lineage也保存下来。
WebUI和Metrics -- 可视化观察工具
当用户在使用Spark时,无论对Spark Cluster的运行情况还是Spark Application运行时的一些细节,希望能够可视化的观察。
WebUI
浏览器输入:http://localhost:8080
Http Server是如何启动的,网页中显示的数据是从哪里得到的?
1) Spark用到的Http Server是Jetty,用Java编写,能够嵌入到用户程序中执行,不用想Tomcat或JBoss那样需要自己独立的JVM进程。
2) SparkUI在SparkContext初始化时创建。
//Initial the spark UI, registering all asociated listeners
private[spark] val ui = new SparkUI(this)
ui.bind() //bind()函数真正启动JettyServer
3) SparkListener持续监听Stage和Task相关事件的发生,并进行数据更新(典型的观察者设计模式)。
Metrics
测量模块是不可或缺的,通过测量数据来感知系统的运行情况。在Spark中,由MetricsSystem来担任这个任务。
Instance:表示谁在使用MetricSystem -- Master,Worker,Executor,Client Driver;Source:表示数据源;Sinks:数据目的地:- ConsoleSink -- 输出到控制台;
- CSVSink -- 定期保存为CSV文件;
- JmxSink -- 注册到Jmx;
- MetricsServlet -- 在SparkUI中添加MetricsServlet,以查看Task运行时的测量数据;
- GraphiteSink -- 发送给Grapgite以对整个系统进行监控。
存储机制
在WordCount程序中,在JobTracker提交之后,被DAGScheduler分为两个Stage:ShuffleMapTask和ResultTask。ShuffleMapTask的输出数据是ResultTask的输入。
ShuffleMapTask.runTask ---| |-->ShuffledRDD.compute ---|
| | |
V-Store V-Store
那么问题来了,ShuffleMapTask的计算结果是如何被ResultTask获得的呢?
1)ShuffleMapTask将计算的状态(不是具体的计算数值)包装为MapStatus返回给DAGScheduler;
2)DAGScheduler将MapStatus保存到MapOutputTrackerMaster中;
3)ResultTask在调用ShuffledRDD时会利用BlockStoreShuffleFetcher中的fetch方法获取数据:
a. 首先要咨询MapOutputTrackerMaster所要获取数据的location;
b. 根据返回的结果调用BlockManager.getMultiple获取到真正的数据。

其中,MapStatus的结构如上图所示,由blockmanager_id 和 byteSize构成,blockmanager_id表示计算的中间结果数据实际存储在哪个BlockManager,byteSize表示不同reduceid所要读取的数据的大小。
Shuffle结果写入
写入过程:
ShuffleMapTask.runTask
HashShuffleWriter.write
BlockObjectWriter.write
HashShuffleWriter.write主要完成两件事情:
- 判断是否要进行聚合,比如
<hello, 1>和<hello, 1>都要写入的话,要先生成<hello, 2>,再进行后续的写入工作; - 利用Partitioner函数来决定
<k, val>写入哪一个文件中。 - 每一个临时文件由三元组
(shuffle_id, map_id, reduce_id)决定,;
shuffle结果读取
ShuffledRDD的compute函数式读取ShuffleMapTask计算结果的触点。
ShuffleRDD.compute() -- 触发读取ShuffleMapTask的计算结果
override def compute(split:Partition, context:TaskContext) : Iterator[P] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K,V,C]]
SparkEnv.get.shuffleManager.getReader().**read()**.asInstanceOf[Iterator[P]] //getReader()返回HashShuffleReader
......
}
HashShuffleReader.read()
override def read() : Iterator[Product2[K,C]] = {
val iter = BlockStoreShuffleFetcher.fetch(handle.shuffleId, startPartition, context, Serializer.getSerializer(dep.serializer))
.....
}
BlockStoreShuffleFetcher.fetch()
BlockStoreShuffleFetcher需要解决的问题:
-
所要获取的mapid的MapStatus的内容是什么;
-
如何根据获得的MapStatus取相应的BlockManager获取数据。
-
一个ShuffleMapTask会产生一个MapStatus,MapStatus中含有当前ShuffleMapTask产生的数据落到各个Partition中的大小,如果为0则表示该分区没有数据产生;
-
索引为reduceId,如果array(0) == 0则表示上一个ShuffleMapTask中生成的数据中没有任何内容可以作为reduceId为0的ResultTask的输入;
-
如果所要获取的文件落在本地,则调用getLocal读取;否则发送请求到远端BlockManager。
Spark内存的消耗。
Spark对内存的要求较高,在ShuffleMapTask和ResultTask中,由于需要先将计算结果保存在内存,然后写入磁盘,如果每个数据分区的数据很大则会消耗大量的内存。
- 每个Writer开启100KB的缓存;
- Records会占用大量内存;
- 在ResultTask的combine阶段,利用HashMap来缓存数据。如果读取的数据量很大或则分区很多,都会导致内存不足。
Memory Store -- 获取缓存的数据
在Spark运行过程中,可以将结果显示地保存下来,那么如果想获取缓存中的数据该怎么办?
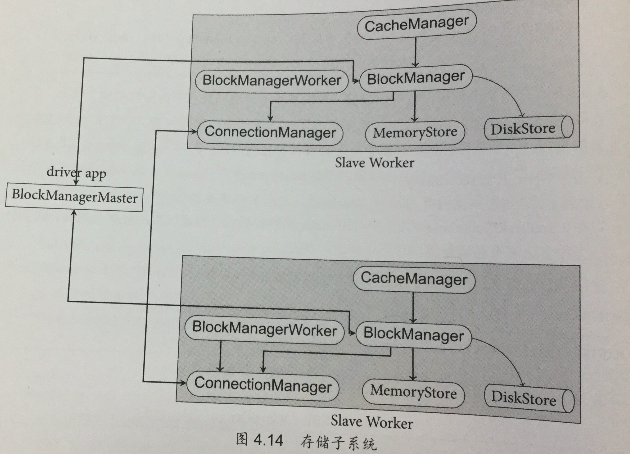
CacheManager:RDD在进行计算转换的时候,通过CacheManager来获取数据,并通过CacheManager来存储计算结果;BlockManager:CacheManager在读取和存储数据的时候主要依赖BlockManager来操作,它决定数据是从内存还是磁盘读取数据;MemoryStore:负责将数据保存在或从内存中读取数据;DiskStore:复杂将数据保存在或从内存中读取数据;BlockManagerWorker:数据写入本地的MemoryStore或DiskStore是一个同步操作,为了保证容错性还需要将数据复制到其他节点,由BlockManagerWorker异步完成数据复制操作;ConnectionManager:负责与其他计算节点建立连接,并负责数据的发送和接收;BlockManagerMaster:该模块只运行在Driver Application所在的Executor,功能是负责记录下所有BlockId存储在哪个SlaveWorker上。
存储子模块启动过程分析
每个存储子模块有SparkEnv来创建,创建过程在SparkEnv.create中完成。
数据写入过程

① RDD.iterator是与Storage子系统交互的入口;
② CacheManager.getOrCompute调用BlockManager中的put接口来写入数据;
③ 数据优先写入到MemoryStore,如果内存已满,则将最近使用次数较少的数据写入磁盘;
④ 通知BlockManagerMaster有新的数据写入,在BlockManagerMaster中保存元数据;
⑤ 如果数据备份数目大于1,则将写入的数据与其他Slave Worker同步。
数据读取过程
- 数据读取的入口是
BlockManager.get(),先尝试从本地获取,如果所要获取的内容不在本地,则发起远程获取。 - 远程获取的代码调用路径为:
getRemote -> doGetRemote;
TachyonStore
Spark优先将计算结果存储到内存中,当内存不足的时候,写到外部磁盘,到底是怎样做的呢?
- Spark实际上将中间结果放在了当前JVM的内存中,也就是JVM既是计算引擎,又是存储引擎。
- 当计算引擎中的错误导致JVM进程退出时,会导致所有存储的内存全部消失;
- 大量的Cache又会使得JVM发生GC的概率增大,严重影响计算性能。
- 因此,使用Tachyon代替JVM的存储功能。
Tachyon以Master/Worker的方式组织集群,由Master负责管理、维护文件系统,文件数据存储在Worker节点中。
- 底层支持Plugable的文件系统,如HDFS用于用户指定文件的持久化;
- 使用Journal机制持久化文件系统中的Metadata;
- 利用ZooKeeper构件Master的HA;
- 采用和Spark RDD类似的Lineage的思想用于灾难恢复。
在最新的Spark中,Storage子系统引入了TachyonStore,在内存中实现了HDFS文件系统的接口,主要目的是尽可能的利用内存来作为数据持久层,避免过多的磁盘读写操作。

